Храните состояние долгоживущих процессов в базе данных, а не в памяти
Долгоживущие процессы давно стали важной частью
Обычно нефункциональные требования в техническом задании не сформулированы, и о них никто кроме разработчика не думает. Чтобы выделить их в явном виде, попробуйте ответить на следующие вопросы:
- Как понять, чем сейчас занимается долгоживущий процесс? Он работает или завис?
- Как понять, сколько задач он обработал за последние 10 минут? За полчаса? За сегодня?
- Что будет, если процесс упадет?
(Да-да, ваш код, конечно, не падает, но обрыв соединения с базой данных и другими сервисамииз-за проблем с сетью никто не отменял.) Зависнет ли обрабатываемая задача? - Зависнет только одна задача? Или все N задач, попавшие в процесс?
- Продолжит ли выполняться задача после перезапуска процесса?
- Если продолжить выполнение задачи нельзя, вернется ли ответ в вызывающую систему об ошибочной ситуации? Будет ли он обработан? Зависнет ли задача в вызывающей системе?
- Позволяет ли ваша система потерять выполняемые задачи? Какие у вас требования к надежности? (Сравните, для примера, пропуск одного обновления данных в
каком-нибудь кеше при его ежеминутном обновлении и потерю данных о финансовой транзакции.)
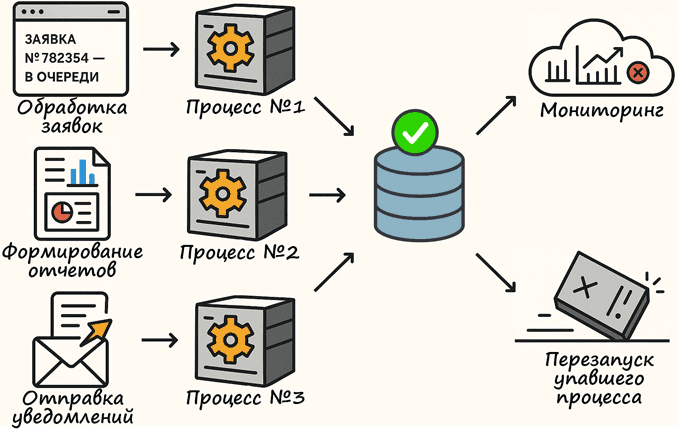
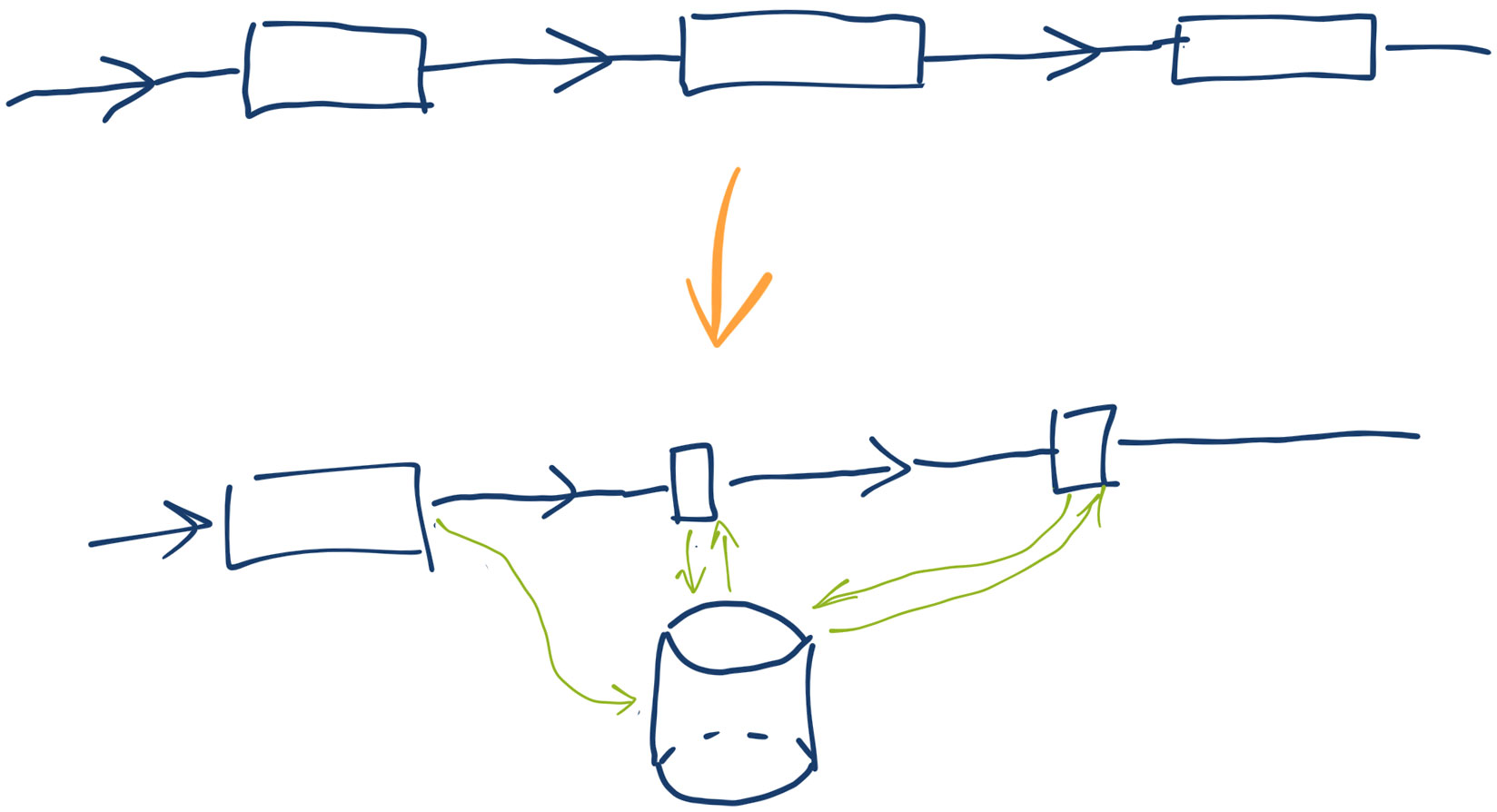
Возможным решением проблем, которые выявляются этими вопросами, является хранение состояния долгоживущих процессов в базе данных, вместо хранения их в памяти приложения. Этот способ подойдет, если долгоживущие процессы выполняют задачи, связанные с обработкой некоторых сущностей, которые и так хранятся в базе данных. Тогда в эти сущности можно добавить поле со статусом обработки, или даже завести отдельную таблицу с задачами для долгоживущих процессов.
Какие преимущества получаем от хранения состояния долгоживущих процессов в базе данных?
Свобода в управлении процессами. Если процесс падает или его необходимо перезапустить, выполняемые задачи остаются в базе данных. При повторном запуске новый экземпляр проверяет и подхватывает незавершенные задачи. Это позволяет избежать потери данных или остановки обработки выполняемых задач.
Упрощение масштабирования. Если хранить данные в памяти процесса, легко попасть в ситуацию, когда несколько процессов не смогут делить между собой задачи и выполнять их параллельно Так получается, когда разработчик пишет код в предположении, что будет запущена только одна копия процесса. Я сам не писал код с такими ошибками, но часто слышу от коллег о подобных проблемах.
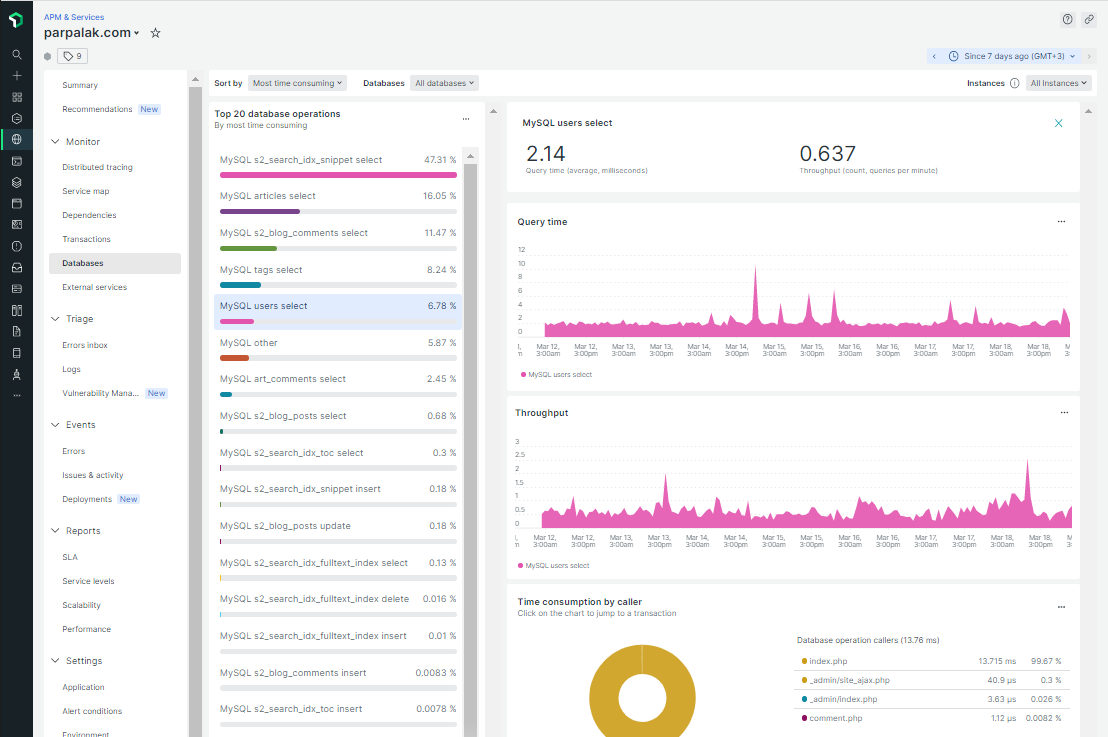
Простота мониторинга. В подготовленной системе мониторинга достаточно написать
Наблюдаемость состояния в админке. Когда состояние хранится в базе данных, его легко вывести в админке. Таким образом, вы сделаете работу приложения наблюдаемым. Иначе ваше рабочее время будет уходить на однотипные вопросы коллег, реагирующих на обращения пользователей: «что случилось с заявкой №782354, запрос ушел, но ответа не было?»
Совет, вынесенный в заголовок, не нов. Делать процессы без состояния (stateless) — одно из требований к
Когда не нужно хранить состояние долгоживущих процессов в базе данных? Когда вы сами понимаете, что в вашем случае написанное выше неприменимо. Если же противопоказаний нет, попробуйте в следующий раз сделать обработку фоновых задач описанным способом.
Оставьте свой комментарий