программирование
Разбираем вопросы о том, как писать код.
Статьи по этой теме:
Программирование
Вайб-кодинг как компьютерная болезнь
Прочитал тут у Михаила Озорнина интересное сравнение
В программировании — состояние потока, фокус, длинные сессии, более медленный и стабильный темп. Уверен, что там совсем другая биохимия и другие нейромедиаторы.
Я думаю, что эта рекомендация может и не сработать. Программирование и без
А что касается мистера Френкеля, который затеял всю эту деятельность, то он начал страдать от компьютерной болезни — о ней сегодня знает каждый, кто работал с компьютерами. Это очень серьезная болезнь, и работать при ней невозможно. Беда с компьютерами состоит в том, что ты с ними играешь. Они так прекрасны, столько возможностей — если четное число, делаешь это, если нечетное, делаешь то, и очень скоро на
одной-единственной машине можно делать все более и более изощренные вещи, если только ты достаточно умен.Через некоторое время вся система развалилась. Френкель не обращал на нее никакого внимания, он больше никем не руководил. Система действовала
очень-очень медленно, а он в это время сидел в комнате, прикидывая, как бы заставить один из табуляторов автоматически печатать арктангенс x. Потом табулятор включался, печатал колонки, потом — бац, бац, бац — вычислял арктангенс автоматически путем интегрирования и составлял всю таблицу за одну операцию.Абсолютно бесполезное занятие. Ведь у нас уже были таблицы арктангенсов. Но если вы
когда-нибудь работали с компьютерами, вы понимаете, что это за болезнь — восхищение от возможности увидеть, как много можно сделать. Френкель подцепил эту болезнь впервые, бедный парень; бедный парень, который изобрел всю эту штуку.
Как правильно запрограммировать условие «по такое-то число»
Наверно, не будет преувеличением сказать, что я ни разу не видел, чтобы
Сейчас, в эпоху нейросетей, легко обобщить это наблюдение на всех программистов. Нейросети выдают как раз «усредненный» код. Так что рассмотрим фрагмент сгенерированного кода (дополнительный плюс в том, что на это некому обижаться, по крайней мере пока):
$dateFrom = $this->createDateTime($filters['dateFrom'], endOfDay: false);
if (null !== $dateFrom) {
$queryBuilder
->andWhere('log.loggedAt >= :dateFrom')
->setParameter('dateFrom', $dateFrom)
;
}
$dateTo = $this->createDateTime($filters['dateTo'], endOfDay: true);
if (null !== $dateTo) {
$queryBuilder
->andWhere('log.loggedAt <= :dateTo')
->setParameter('dateTo', $dateTo)
;
}
// ...
private function createDateTime(?string $value, bool $endOfDay): ?\DateTimeImmutable
{
if (null === $value || '' === $value) {
return null;
}
$date = \DateTimeImmutable::createFromFormat('Y-m-d', $value) ?: \DateTimeImmutable::createFromFormat(\DateTimeInterface::ATOM, $value);
if (false === $date) {
return null;
}
return $endOfDay ? $date->setTime(23, 59, 59) : $date->setTime(0, 0, 0);
}
Для простоты понимания перепишем этот код на чистом SQL для интервала, скажем, с 1 по 10 ноября:
SELECT *
FROM audit_logs
WHERE logged_at >= '2025-11-01'
AND loggged_at <= '2025-11-10 23:59:59'Когда я вижу эти 23:59:59, у меня сразу возникает неприятное ощущение от того, насколько это неэстетичное решение. Некоторые не останавливаются на секундах, а добавляют еще и микросекунды, и время превращается в

Правильный способ состоит в том, чтобы не приписывать финальной дате последний доступный момент времени, а заменить условие «по
SELECT *
FROM audit_logs
WHERE logged_at >= '2025-11-01'
AND loggged_at < '2025-11-11'Стоит запомнить этот шаблон использования полуоткрытых интервалов, когда нижняя граница диапазона включается в условие, а верхняя исключается. Он пригождается чаще, чем может показаться на первый взгляд.
Разбираем конечный автомат в системе личных сообщений
В прошлый раз я рассказывал о применении понятия конечного автомата в программировании. В этот раз рассмотрим практический пример.
Одним из первых моих заданий в команде форума PunBB была система обмена личными сообщениями, которую я проектировал и разрабатывал с нуля. На примере этой системы посмотрим, как требования к системе преобразуются в набор состояний и переходов между ними.
Требование №1: черновики и уведомления о прочтении
Когда один пользователь отправляет другому сообщения внутри
$$\usetikzlibrary{arrows} \begin{tikzpicture}[node distance=4cm,font=\sffamily] \tikzset{ mynode/.style={rectangle,rounded corners,draw=black,thick, inner sep=0.7em, text width=7em,text centered}, myarrow/.style={->, >=latex', shorten >=1pt, shorten <=2pt,thick,font=\small\sffamily} } \node[mynode,fill=gray!10] (Draft) {Черновик\\status=draft}; \node[mynode, right of=Draft,fill=cyan!10] (Sent) {Отправлено\\status=sent}; \node[mynode, right of=Sent,fill=green!10] (Read) {Прочитано\\status=read}; \draw[myarrow] (Draft) to[in=130,out=50] node[above,align=center] {Отправитель нажал\\«Отправить»} (Sent); \draw[myarrow] (Sent) to[in=130,out=50] node[above,align=center] {Получатель открыл\\ сообщение} (Read); \end{tikzpicture}$$
Требование №2: отзыв отправленных сообщений
Кроме очевидной функциональности мы решили добавить уникальную по тем временам фичу — отзыв сообщения. Если получатель не заходил на форум и не имел возможности узнать о том, что ему пришло сообщение, отправитель мог бесследно отозвать это сообщение, даже если после отправки прошло много времени.
Чтобы дать отправителю возможность отзывать сообщения, нужно не только разрешить обратный переход из «отправлено» в «черновик», но и добавить дополнительный статус «доставлено». Переход к нему происходит в тот момент, когда отправитель может узнать о том, что ему пришло новое сообщение. (В зависимости от настройки форума это либо посещение любой страницы, если количество непрочитанных сообщений отображается в меню, либо переход непосредственно ко входящим сообщениям.)
$$\usetikzlibrary{arrows} \begin{tikzpicture}[node distance=4cm,font=\sffamily] \tikzset{ mynode/.style={rectangle,rounded corners,draw=black,thick, inner sep=0.7em, text width=7em,text centered}, myarrow/.style={->, >=latex', shorten >=1pt, shorten <=2pt,thick,font=\small\sffamily} } \node[mynode,fill=gray!10] (Draft) {Черновик\\status=draft}; \node[mynode, right of=Draft,fill=cyan!10] (Sent) {Отправлено\\status=sent}; \node[mynode, right of=Sent,fill=green!10] (Delivered) {Доставлено\\status=delivered}; \node[mynode, right of=Delivered,fill=green!10] (Read) {Прочитано\\status=read}; \draw[myarrow] (Draft) to[in=130,out=50] node[above,align=center] {Отправитель нажал\\«Отправить»} (Sent); \draw[myarrow] (Sent) to[in=-50,out=-130] node[below,align=center] {Отправитель нажал\\«В черновики»} (Draft); \draw[myarrow] (Sent) to[in=130,out=50] node[above,align=center] {Получатель увидел\\ кол-во сообщений} (Delivered); \draw[myarrow] (Delivered) to[in=130,out=50] node[above,align=center] {Получатель открыл\\ сообщение} (Read); \end{tikzpicture}$$
Если бы требовалось сделать отправку уведомлений о новых личных сообщениях по электронной почте, пришлось бы делать переход «отправлено» → «доставлено» в момент отправки письма, так как мы уже не контролируем процесс доставки этого письма и не знаем, когда оно будет прочитано.
Требование №3: удаление сообщений
По требованиям и получатель, и отправитель могут удалять сообщения. В свое время я сделал два флага: deleted_by_sender и deleted_by_receiver. Они нужны для того, чтобы знать, от кого из участников уже надо скрыть сообщение, а от кого еще нет. Если же они оба удаляют сообщение, то оно удаляется из базы данных целиком. (Здесь важно не повторить мою ошибку и устанавливать флаги в транзакции после блокировки строк, иначе при одновременном удалении отправителем и получателем получим оба установленных флага вместо полного удаления сообщения.)
С одной стороны флаги deleted_by_sender и deleted_by_receiver выглядят красиво и симметрично. Но с другой стороны, если вы внимательно читали предыдущий пост, то уже догадались, что набор из трех полей (status, deleted_by_sender и deleted_by_receiver) — не самое лучшее решение для кодирования состояния.
Первая проблема этих флагов и поля состояния заключается в том, что некоторые наборы значений (например, status = draft и deleted_by_receiver = 1) не соответствуют ни одному допустимому состоянию (черновик не может иметь отметку об удалении получателем, потому что получатель ничего не получал). Вторая проблема проявляется в повторении в коде одних и тех же условий. Так, условие deleted_by_receiver = 0 AND (status = 'delivered' OR status = 'read'), которое соответствует доступным получателю сообщениям, повторяется в коде три раза.
Что же делать с признаками удаления сообщений? На диаграмме состояний видно, что статусами управляет сначала отправитель, а потом получатель. Также получатель может удалить сообщение только после его доставки. Поэтому состояние «удалено получателем» вполне естественно вписывается в имеющийся набор состояний:
$$\usetikzlibrary{arrows} \begin{tikzpicture}[node distance=3.6cm,font=\sffamily] \tikzset{ mynode/.style={rectangle,rounded corners,draw=black,thick, inner sep=0.5em, text width=7em,text centered}, myarrow/.style={->, >=latex', shorten >=1pt, shorten <=2pt,thick,font=\small\sffamily} } \node[mynode,fill=gray!10] (Draft) {\shortstack{Черновик\\status=draft}}; \node[mynode, right of=Draft,fill=cyan!10] (Sent) {Отправлено\\status=sent}; \node[mynode, right of=Sent,fill=green!10] (Delivered) {\shortstack{Доставлено\\status=delivered}}; \node[mynode, right of=Delivered,fill=green!10] (Read) {Прочитано\\status=read}; \node[mynode, right of=Read,fill=red!10] (Deleted) {Удалено\\status=deleted}; \draw[myarrow] (Draft) to[in=130,out=50] node[above,align=center] {Отправитель нажал\\«Отправить»} (Sent); \draw[myarrow] (Sent) to[in=-50,out=-130] node[below,align=center] {Отправитель нажал\\«В черновики»} (Draft); \draw[myarrow] (Sent) to[in=130,out=50] node[above,align=center] {Получатель увидел\\ кол-во сообщений} (Delivered); \draw[myarrow] (Delivered) to[in=130,out=50] node[above,align=center] {Получатель открыл\\ сообщение} (Read); \draw[myarrow] (Read) to[in=130,out=50] node[above,align=center] {Получатель удалил\\ сообщение} (Deleted); \end{tikzpicture}$$
К сожалению, от флага deleted_by_sender не получится избавиться так же просто. Дело в том, что удаление сообщения отправителем может произойти в любом статусе, и у этого действия будут разные последствия:
- при удалении черновика или отправленного сообщения запись удаляется из базы данных;
- при удалении доставленного или прочитанного сообщения мы скрываем его от отправителя;
- при удалении отправителем уже удаленного получателем сообщения запись также удаляется из базы данных.
С учетом этих требований диаграмма всех возможных состояний приобретает следующий вид:
$$\usetikzlibrary{arrows} \begin{tikzpicture}[node distance=3.6cm,font=\sffamily] \tikzset{ mynode/.style={rectangle,rounded corners,draw=black,thick, inner sep=0.5em, text width=7.0em,text centered}, myarrow/.style={->, >=latex', shorten >=1pt, shorten <=2pt,thick,orange!70!black,font=\small\sffamily}, sender/.style={blue!80!black} } \clip (-10,10) rectangle (20,-8); %костыль \node[mynode,fill=gray!10] (Draft) {Черновик\\status=draft}; \node[mynode,above of=Draft,dashed] (New) {В БД пусто}; \node[mynode, right of=Draft,fill=cyan!10] (Sent) {Отправлено\\status=sent}; \node[mynode, right of=Sent,fill=green!10] (Delivered) {Доставлено\\status=delivered}; \node[mynode, below of=Delivered,fill=yellow!10] (DeliveredAndDeleted) {\shortstack{Доставл. и удал.}\\status=delivered\\del\_by\_sendr=1}; \node[mynode, right of=Delivered,fill=green!10] (Read) {Прочитано\\status=read}; \node[mynode, below of=Read,fill=yellow!10] (ReadAndDeleted) {Прочит. и удал.\\status=read\\del\_by\_sendr=1}; \node[mynode, right of=Read,fill=yellow!10] (Deleted) {Удалено\\status=deleted}; \node[mynode, below of=Deleted,dashed] (Deleted2) {Удалено из БД}; \draw[myarrow,sender] (New) to[] node[left,align=right] {Отправитель\\нажал\\«В черновики»} (Draft); \draw[myarrow,sender] (New) to[out=0,in=90] node[right,pos=0.2,align=center] {Отправитель нажал\\«Отправить»} (Sent); \draw[myarrow,sender] (Draft) to[in=130,out=50] node[above,align=center] {Отправитель\\нажал\\«Отправить»} (Sent); \draw[myarrow,sender] (Sent) to[in=-50,out=-130] node[below,align=center] {Отправитель\\нажал\\«В черновики»} (Draft); \draw[myarrow] (Sent) to[in=130,out=50] node[above,align=center] {Получатель увидел\\ кол-во сообщений} (Delivered); \draw[myarrow] (Delivered) to[in=130,out=50] node[above,align=center] {Получатель открыл\\ сообщ.} (Read); \draw[myarrow] (Read) to[in=130,out=50] node[above,align=center] {Получатель удалил\\ сообщ.} (Deleted); \draw[myarrow,sender] (Delivered) to node[left,align=right] {Отправитель\\удалил\\сообщ.} (DeliveredAndDeleted); \draw[myarrow,sender] (Read) to node[left,align=right] {Отправитель\\удалил\\сообщ.} (ReadAndDeleted); \draw[myarrow,sender] (Deleted) to node[left,align=right] {Отправитель\\удалил\\сообщ.} (Deleted2); \draw[myarrow,sender] (Draft) to[in=-80,out=-90,looseness=1.2] node[below,pos=0.6] {Отправитель удалил сообщ.} (Deleted2); \draw[myarrow,sender] (Sent) to[in=-90,out=-90,looseness=1.3] node[below,pos=0.58] {Отправитель удалил сообщ.} (Deleted2); \draw[myarrow] (DeliveredAndDeleted) to[in=-130,out=-50] node[below,align=center] {Получатель открыл\\ сообщ.} (ReadAndDeleted); \draw[myarrow] (ReadAndDeleted) to[in=-130,out=-50] node[below,align=center,pos=0.4] {Получатель удалил\\ сообщ.} (Deleted2); \end{tikzpicture}$$
Я добавил на диаграмму начальное состояние, когда в базе данных еще нет сообщения и отправитель сохраняет его впервые, а также конечное состояние, когда оба участника переписки удалили сообщение. В принципе, никто не запрещает ввести отдельные коды для состояний «доставлено получателю и удалено отправителем» и «прочитано получателем и удалено отправителем», чтобы состояние кодировалось всего одним полем status. Но я бы оставил флаг deleted_by_sender отдельно от поля status, чтобы смысл данных в таблице был интуитивно понятным.
Выводы и анализ корректности требований
Я показал, как можно анализировать
Проанализируем корректность и полноту диаграммы из нашего примера. На диаграмме отсутствует переход между доставленным и удаленным состоянием сообщения. Должен ли он существовать? Должен, если получатель может удалить сообщение из списка, не открывая его. Должна ли система отображать отправителю, что получатель, не прочитав, удалил сообщение? Если должна, то одного состояния «удалено» недостаточно, так как мы теряем информацию о прочтении удаленных сообщений. Возможно, в этом случае не стоило удалять флаг deleted_by_receiver и заменять его на status=deleted.
Аналогичными вопросами проверяется корректность всей диаграммы состояний на этапе проектирования. Их можно задавать и самому себе, и постановщику задачи для полного прояснения требований.
Применение конечных автоматов в программировании
Когда мы пишем программы, часто управляем состоянием
Для управления состоянием полезно иметь представление о конечных автоматах. Конечный автомат — это математическая модель, состоящая из конечного набора состояний, переходов между этими состояниями и действий, выполняемых при этих переходах. Посмотрим, как можно применить идеи из теории конечных автоматов на примере системы комментариев в блоге.
Проблемы в примере без конечных автоматов
shown. Комментарий создавался сразу опубликованным (shown = 1), и позднее его можно было скрыть (shown = 0).
Зачем вообще скрывать комментарии, если их можно удалить? Я сделал комментарии скрываемыми, чтобы можно было передумать, а также чтобы анализировать комментарии со спамом для борьбы с ним. Например, если с
Потом я решил добавить модерацию — предварительную проверку комментариев перед публикацией. Сделал по аналогии еще один флаг sent, который хранит информацию о том, был ли разослан этот комментарий подписавшимся авторам предыдущих комментариев.
Если режим предварительной проверки выключен, набор состояний остается таким же:
shown=1, sent=1— комментарий опубликован и разослан сразу в момент создания;shown=0, sent=1— комментарий скрыт.
А в режиме с включенной предварительной проверкой появляется новое состояние:
shown=0, sent=0— комментарий в момент создания только записан в БД, его должен одобрить модератор;shown=1, sent=1— комментарий опубликован модератором, в момент публикации он рассылается;shown=0, sent=1— комментарий скрыт после публикации.
За публикацию комментария, находящегося на рассмотрении, отвечала та же кнопка, которая ранее управляла флагом shown. В обработчик ее нажатия добавилось только одно условие: если в момент изменения shown с 0 на 1 комментарий еще не разослан, он рассылался. Таким образом, переходы между этими состояниями можно отобразить в виде такой диаграммы:
$$\usetikzlibrary{arrows} \begin{tikzpicture}[node distance=4cm,font=\sffamily] \tikzset{ mynode/.style={rectangle,rounded corners,draw=black,thick, inner sep=0.7em, text width=7em,text centered}, myarrow/.style={->, >=latex', shorten >=1pt, shorten <=2pt,thick} } \node[mynode,fill=yellow!10] (moder) {\shortstack{На проверке\\\tt shown=0\\\tt sent=0}}; \node[mynode, right of=moder,fill=green!10] (pub) {\shortstack{Опубликован\\\tt shown=1\\\tt sent=1}}; \node[mynode, right of=pub,fill=gray!10] (hidden) {\shortstack{Скрыт\\\tt shown=0\\\tt sent=1}}; \draw[myarrow] (moder) to[in=130,out=50] node[above] {рассылка} (pub); \draw[myarrow] (pub) to[in=130,out=50] (hidden); \draw[myarrow] (hidden) to[in=-50,out=-130] (pub); \end{tikzpicture}$$
Если присмотреться к этой диаграмме, можно заметить недостаток: из состояния «на проверке» можно перейти только в состояние «опубликован», при этом комментарий будет разослан авторам предыдущих комментариев. Но что делать, если комментарий проверку не прошел? Спам хотелось бы отправить напрямую в состояние «скрыт», минуя состояние «опубликован».
Когда я увидел на практике необходимость такого перехода, то запрограммировал новую кнопку «оставить скрытым и не рассылать», которая (внимание!) изменяла значение флага sent с 0 на 1 без фактической рассылки комментариев. Таким образом, поменялся смысл флага sent: раньше он указывал на то, что комментарий был разослан, а теперь указывает на отсутствие необходимости разослать комментарий.
$$\usetikzlibrary{arrows} \begin{tikzpicture}[node distance=4cm,font=\sffamily] \tikzset{ mynode/.style={rectangle,rounded corners,draw=black,thick, inner sep=0.7em, text width=7em,text centered}, myarrow/.style={->, >=latex', shorten >=1pt, shorten <=2pt,thick} } \node[mynode,fill=yellow!10] (moder) {\shortstack{На проверке\\\tt shown=0\\\tt sent=0}}; \node[mynode, right of=moder,fill=green!10] (pub) {\shortstack{Опубликован\\\tt shown=1\\\tt sent=1}}; \node[mynode, right of=pub,fill=gray!10] (hidden) {\shortstack{Скрыт\\\tt shown=0\\\tt sent=1}}; \draw[myarrow] (moder) to[in=140,out=40] node[above] {\shortstack{Одобрить\\ (+рассылка)}} (pub); \draw[myarrow] (moder) to[in=-120,out=-60] node[below] {Оставить скрытым и не рассылать} (hidden); \draw[myarrow] (pub) to[in=140,out=40] node[above] {Скрыть} (hidden); \draw[myarrow] (hidden) to[in=-40,out=-140] node[below,pos=0.7] {Опубликовать} (pub); \end{tikzpicture}$$
В итоге мы получили следующие проблемы:
- состояние комментария определяется косвенно по набору значений отдельных признаков
showиsent; - признак
sentпотерял свой первоначальный смысл, его значение уже не говорит о том, произошла ли рассылка комментария; - признаки, по которым определяется состояние, не могут меняться независимо: например, набор значений
shown=1иsent=0не имеет смысла.
Последний пункт особенно важно осознать: значения shown=1 и sent=0 можно получить либо в результате ошибки в коде, либо прямым редактированием базы данных. Выходит, такая модель данных может кодировать несуществующее состояние, и это свидетельствует об ошибке проектирования.
Если мы продолжим дорабатывать систему таким же путем, проблемы при масштабировании усугубятся. По мере добавления новых состояний системы количество флагов будет расти, что усложнит логику проверки состояния. Сама проверка может происходить в нескольких местах, что потребует копирования этой сложной логики по всему коду.
Как хранить и обрабатывать статусы
Мы уже нарисовали граф состояний конечного автомата — возможные состояния комментария и переходы между ними. В нашем случае разрешены не все переходы: в состояние «на проверке» вернуться нельзя. Это ограничение обусловлено требованием
Каждое состояние конечного автомата должно определяться значением одного свойства, причем значения этого свойства должны быть взаимоисключающими. В разобранном примере в модели данных вместо двух свойств shown и sent нужно ввести одно свойство status с тремя возможными значениями:
$$\usetikzlibrary{arrows,positioning} \begin{tikzpicture}[font=\sffamily] \tikzset{ block/.style={rectangle,rounded corners,draw=black,thick, inner sep=0.7em, text width=8em,text centered}, myarrow/.style={->, >=latex', shorten >=1pt, shorten <=2pt,thick} } \node[block,fill=yellow!10] (moder) {\shortstack{На проверке\\\tt status=pending}}; \node[block, above right=0cm and 3cm of moder,fill=green!10] (pub) {\shortstack{Опубликован\\\tt status=published}}; \node[block, below right=0cm and 3cm of moder,fill=gray!10] (hidden) {\shortstack{Скрыт\\\tt status=hidden}}; \draw[myarrow] (moder) to[in=180,out=30] node[above] {\shortstack{Одобрить\\ (+рассылка)}} (pub); \draw[myarrow] (moder) to[in=180,out=-30] node[below] {Отклонить} (hidden); \draw[myarrow] (pub) to[in=120,out=-120] node[left] {Скрыть} (hidden); \draw[myarrow] (hidden) to[in=-60,out=60] node[right] {Опубликовать} (pub); \end{tikzpicture}$$
После этого везде в коде вместо проверки двух разных свойств shown и sent нужно проверять значение одного свойства status. Например, в запросе для вывода комментариев читателям блога нужно писать не WHERE shown=1, а WHERE status='published'.
Сходу программисту может быть непонятно, какой набор значений должен быть у поля «статус». Но это не значит, что у моделируемых объектов нет набора состояний и возможных переходов между ними. Если их не выявить, код окажется более сложным и запутанным, чем мог бы быть. А если статус выделен правильно, получаем такие преимущества:
- в условных операторах происходит простая проверка статуса, в них нет дополнительных проверок набора свойств;
- добавление новых состояний и переходов упрощается и не требует значительных изменений имеющегося кода;
бизнес-логика прозрачная, состояния моделей и самих моделируемых объектов напрямую соответствуют друг другу.
Польза для общения с бизнесом
Последний пункт имеет отдельную ценность и требует дополнительного объяснения. Важным элементом в разработке проектов является общий язык. Статусы сущностей — это часть общего языка, на котором должны разговаривать не только разработчики, но и заказчики со стороны бизнеса. Не бойтесь использовать статусы при объяснении того, как работает система сейчас и как она будет работать после внесения изменений.
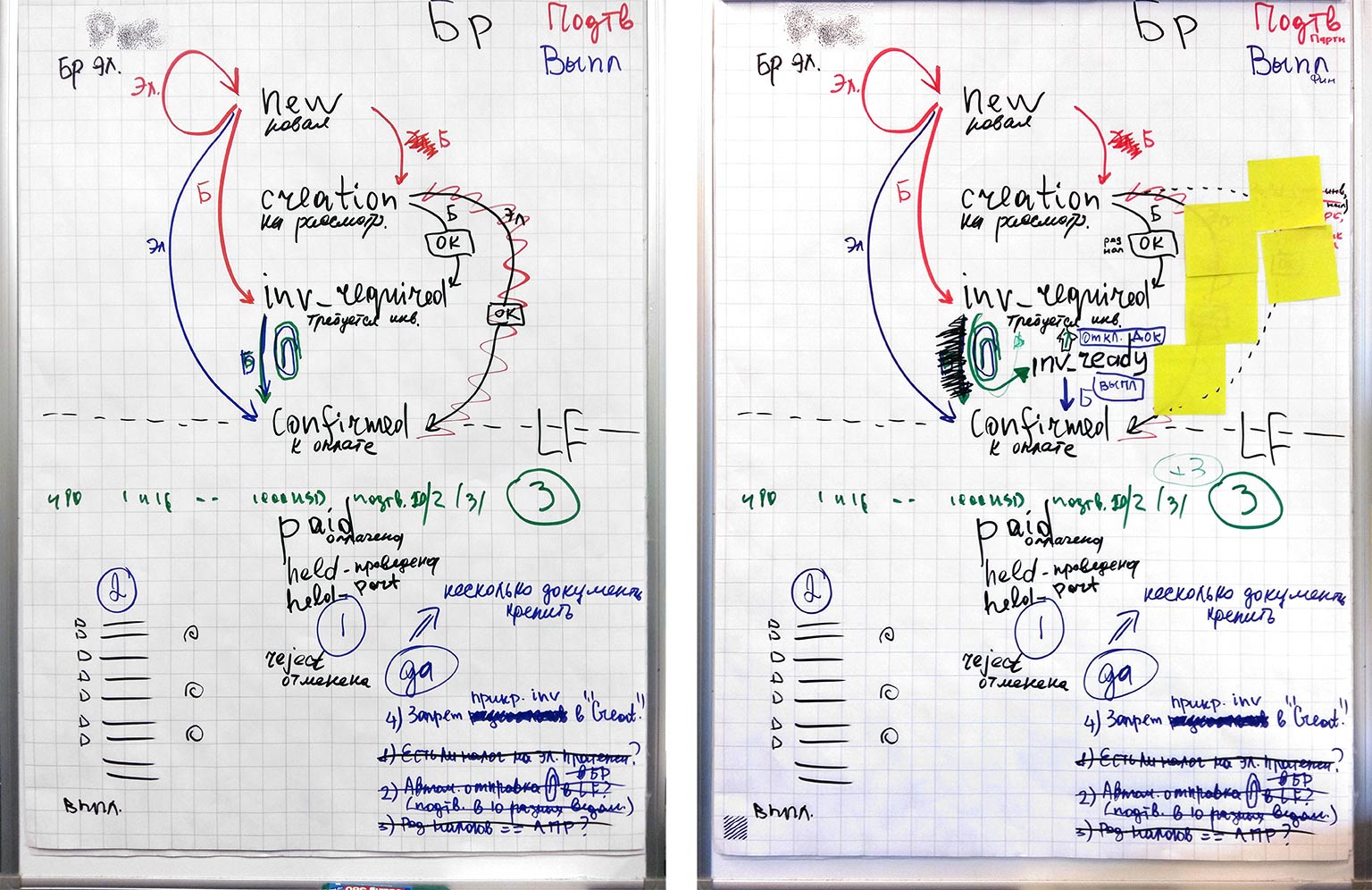
На этой фотографии пример того, как я рисовал конечный автомат заявок на выплаты во время проработки задачи с заказчиком. Видно, что у заявок много статусов, за разные переходы отвечают пользователи с разными ролями. По мере проработки задачи мы поняли, что одного нового статуса мало, нам нужен еще один дополнительный статус.
Состояния в больших системах
В крупных системах невозможно хранить информацию о состоянии обрабатываемых сущностей в одной колонке одной таблицы базы данных, как это было в примере выше.
Для примера представьте, что вы отправляете заявку на ипотечный кредит через личный кабинет на сайте банка. Пока вы заполняете анкету, фотографируете и прикрепляете документы, заявка находится в статусе «черновик». При отправке заявки вы переводите ее в статус «на проверке». Одни сервисы начинают выполнять автоматические проверки. В других сервисах происходит ручная проверка прикрепленных фотографий. Личный кабинет скорее всего не будет знать о таких мельчайших подробностях, как состояние запроса в ФНС на получение вашего ИНН (запрос еще не отправлен, ожидается ответ, ответ получен). Но если в ходе проверки были выявлены проблемы, личный кабинет их отобразит. Например, если паспорт прошел проверку, а справка по форме
Таким образом, за одним значением статуса
Состояния в append-only системах
На первый взгляд кажется, что для сохранения меняющегося статуса нужно делать UPDATE записи в базе данных. Однако это несовместимо с иммутабельными объектами и с логическим продолжением принципа иммутабельности — с таблицами, в которых данные не изменяются, а только дописываются.
В
Зачем вообще делать
- Если записи в таблице никогда не обновляются, не нужно дополнительно программировать и хранить историю изменений. Вся история будет в основных таблицах с данными.
- Базы данных любят, когда данные в таблицах не обновляются, а только дописываются. Например, в PostgreSQL
UPDATE— это на самом деле комбинацияDELETEиINSERT. Удаленные версии строккакое-то время хранятся на диске, их потом нужно дополнительно вычищать. Происходитчто-то вроде фрагментации, когда дисковое пространство используется неэффективно. Кроме того, в огромныхappend-only таблицах на поля вроде времени создания можно повесить эффективный и компактный индекс BRIN. - Не нужно заботиться об инвалидации закешированных строк из базы данных. Например, в кеше второго уровня в Доктрине из коробки лучше всего работает режим READ_ONLY. Инвалидация кеша приложения становится особенно проблематичной в системах с несколькими копиями приложения на разных серверах: когда один сервер делает
UPDATE, другие об этом просто так не узнают и продолжат использовать старую версию из кеша.
Некоторые возможности регулярных выражений, о которых мало кто знает
На примере задачи с поиском определенных последовательностей символов в строке расскажу о некоторых не очень известных возможностях регулярных выражений.
Условие задачи
Нужно найти в строке символы i, b, u, d, перед которыми расположено нечетное количество обратных слешей, например \I или \\\b.
Мотивация
Расскажу, откуда появилась эта задача. В свой поисковый движок Rose я добавил поддержку простейшего форматирования в сниппетах: курсив, жирный шрифт, верхние и нижние индексы. Благодаря этому формула
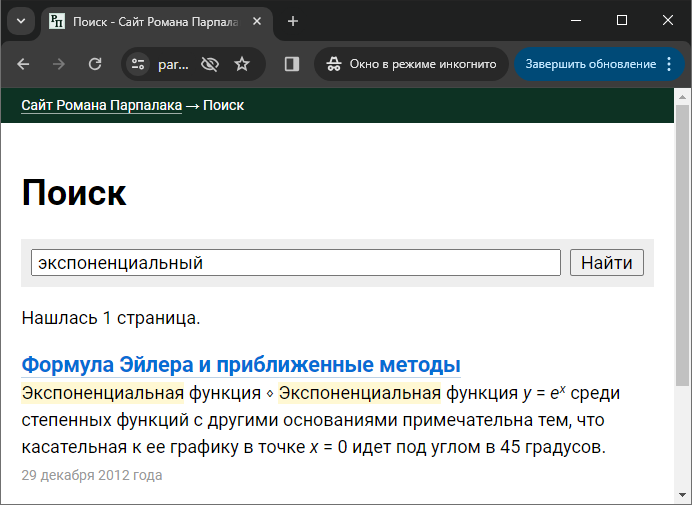
Я не хотел хранить текст сниппетов с частично вырезанными \i включает курсивное начертание, последовательность \I отключает. Аналогично с остальным форматированием. При этом, чтобы хранить сам символ обратного слеша, его нужно продублировать для экранировки (\\). Таким образом, формула из примера выше хранится в сниппетах как \iy\I = e\u\ix\I\U.
Как видно на скриншоте выше, сниппеты собираются из отдельных предложений, а форматирование может распространяться за их границы. Например, я могу выделить курсивом целый абзац, тогда \i будет в начале первого предложения, а \I — в конце последнего. Поэтому важно после разбиения текста на предложения убедиться, что всё открытое форматирование корректно завершено в текущем предложении и перенесено на следующее, и нет завершения неоткрытого форматирования. Для этого как раз и нужна сформулированная задача.
Решение
Я составил такую регулярку: #\\(?:\\(*SKIP)\\)*\K[ibud]#i. Давайте разберем ее по шагам.
- Регулярка начинается с символа обратного слеша. Нужно помнить, что в регулярных выражениях он имеет специальное значение, и сам по себе должен быть экранирован.
- Дальше идет группа
(?:...)без захвата, то есть ее содержимое не попадает в итоговый массив результатов$matches. - Внутри группы находятся два обратных слеша, а сама группа указана с
квантификатором , означающим её повторение любого количества раз, включая нулевое. Таким образом уже разобранная часть регулярки должна срабатывать на нечетном количестве слешей.* - Внутри группы также расположена управляющая последовательность бэктрекинга
(*SKIP). Она обозначает некоторую границу и дает инструкции движку регулярных выражений, чтобы он не переходил эту границу при переборе возможных повторений, задаваемыхквантификатором , а также сразу переходил к ней в исходной строке, если было только частичное совпадение с регуляркой. Без этой управляющей последовательности мы бы получили ложное совпадение на строке*\\iс четным количеством слешей. Действительно, в ней на первом проходе, начиная с первого символа\\i, совпадения нетиз-за четного количества слешей. Но дальше мы получим совпадение, начиная со второго символа:\\i.(*SKIP)же задает границу между вторым слешем и следующим символом, поэтому движок регулярок при работе не будет проверять совпадение со второго символа, а сразу перейдет к третьему. В англоязычной литературе для подобных управляющих последовательностей используется термин Backtracking Control Verbs, среди них есть и другие полезные возможности. - Следующей идет последовательность
\K. Она убирает из результатов общего совпадения всё, что было до нее. Таким образом, в$matches[0]попадет только оставшаяся часть совпадения, без слешей. - Наконец, мы требуем, чтобы после нечетного количества слешей был один из управляющих символов
[ibud]. Так как у регулярки указан модификаторi, совпадение будет в любом регистре.
Если не использовать жемчужину этой регулярки, (*SKIP), можно сочинить выражение с ретроспективной проверкой (lookbehind): #(?<=^|[^\\])\\(?:\\\\)*\K[ibud]#i. Правда, оно будет менее эффективно на строках с обратным слешем. Ну а наивное выражение #(?:^|[^\\])\\(?:\\\\)*\K[ibud]#i будет медленнее на любых строках, так как не начинается с фиксированного символа обратного слеша.
При применении регулярных выражений не нужно забывать о дополнительном экранировании слешей по требованиям синтаксиса языка программирования. Итоговый код на PHP получается таким:
preg_match_all('#\\\\(?:\\\\(*SKIP)\\\\)*\K[ibud]#i', $text, $matches);
foreach ($matches[0] as $match) {
// в $match будет один из символов ibudIBUD
}Тесты выявляют проблемы не только с вашим кодом
Удивительные тесты
Представьте, что вы пришли на новый проект и обнаружили в нем вот такой тест:
<?php
use Codeception\Test\Unit;
class MyTest extends Unit
{
public function testHash(): void
{
$this->assertEquals('098f6bcd4621d373cade4e832627b4f6', md5('test'));
}
}
Для неспециалистов поясню, что этот тест вызывает встроенную в PHP функцию md5(), передает ей аргумент 'test' и проверяет, что она возвращает указанное значение.
Зачем нужен этот тест, если встроенная функция и так вычисляет хеш по известному задокументированному алгоритму? Мы же пишем тесты на наш проект, а не на интерпретатор PHP. Написавший этот тест коллега на вопросы отвечает так:
— В наших алгоритмах мы полагаемся на значения хешей, сохраненные в базе данных. Если вдруг функция начнет возвращать другие значения в будущих версиях PHP, мы заметим это по упавшему тесту. Конечно, такие изменения нарушают обратную совместимость, и они должны быть написаны в информации о релизе PHP. Но их можно просмотреть
Как считаете, писать в проекте тест на встроенную функцию PHP — это паранойя? Или разумная предусмотрительность? А что, если это не встроенная функция в PHP, а сторонняя библиотека? Правда же, такой тест вызывает меньше удивления:
<?php
use Codeception\Test\Unit;
use SuperVendor\SuperHashLib\SuperHash;
class MyTest extends Unit
{
public function testHash(): void
{
$this->assertEquals('098f6bcd4621d373cade4e832627b4f6', SuperHash::getHash('test'));
}
}
Тест выявил изменение поведения при обновлении PHP
В моей практике похожий тест действительно однажды помог отследить вредный побочный эффект от нарушения обратной совместимости при обновлении PHP. Минимальный пример для воспроизведения такой:
<?php
class A
{
public $prop1 = '1';
public $prop2 = '2';
public function getHash(): string
{
return md5(serialize($this->normalize()));
}
public function normalize(): array
{
return get_object_vars($this);
}
}
class B extends A
{
public $prop3 = '3';
}
$a = new A;
var_dump($a->getHash());
$b = new B;
var_dump($b->getHash());
Этот код в старых версиях PHP до 8.1 выводит следущее:
string(32) "e5f8d9c52536e3412aa273c7bd4c9dbb"
string(32) "46d9b1133eec8d47fe6e00e970cf0a77"А начиная с 8.1 значение хеша у объекта класса B изменилось:
string(32) "e5f8d9c52536e3412aa273c7bd4c9dbb"
string(32) "8275b764cf277cbbd3b00b1e86d8a4eb"Причина различий в изменении порядка свойств в массиве, возвращаемом get_object_vars(). В старых версиях сначала шли свойства самого класса, а затем унаследованные от родительского:
// До PHP 8.1
Array
(
[prop3] => 3
[prop1] => 1
[prop2] => 2
)В новых же версиях сначала идут унаследованные свойства, а потом собственные свойства класса:
// PHP 8.1 и старше
Array
(
[prop1] => 1
[prop2] => 2
[prop3] => 3
)Как видите, такое изменение поведения при обновлении PHP меняет значения хешей, вычисляемые очевидным и прямолинейным способом. И это изменение даже не было заявлено в информации о релизе как ломающее обратную совместимость!
Мы смогли отловить проблему как раз благодаря тесту, в котором проверялось точное значение вычисленного хеша. Правда, он был написан с другой целью. В нашем случае при добавлении новых полей мы исключали их из вычисления хеша, чтобы хеш не менялся, если новые поля не используются:
<?php
class A
{
public $prop1 = '1';
public $prop2 = '2';
public $propN = null;
public function getHash(): string
{
return md5(serialize($this->normalize()));
}
private function normalize(): array
{
$data = get_object_vars($this);
if ($this->propN === null) {
unset($data['propN']);
}
return $data;
}
}Чтобы разработчики не забывали добавлять unset() новых
Пример решения проблем с обратной совместимостью алгоритмов хеширования
Чтобы дважды не вставать и рассказать не только о проблеме, но и о том, как ее решать, рассмотрим пример, в котором требуется подход с get_object_vars() и вычислением хешей.
Предположим, вы разрабатываете сервис для отслеживания цен на товары в
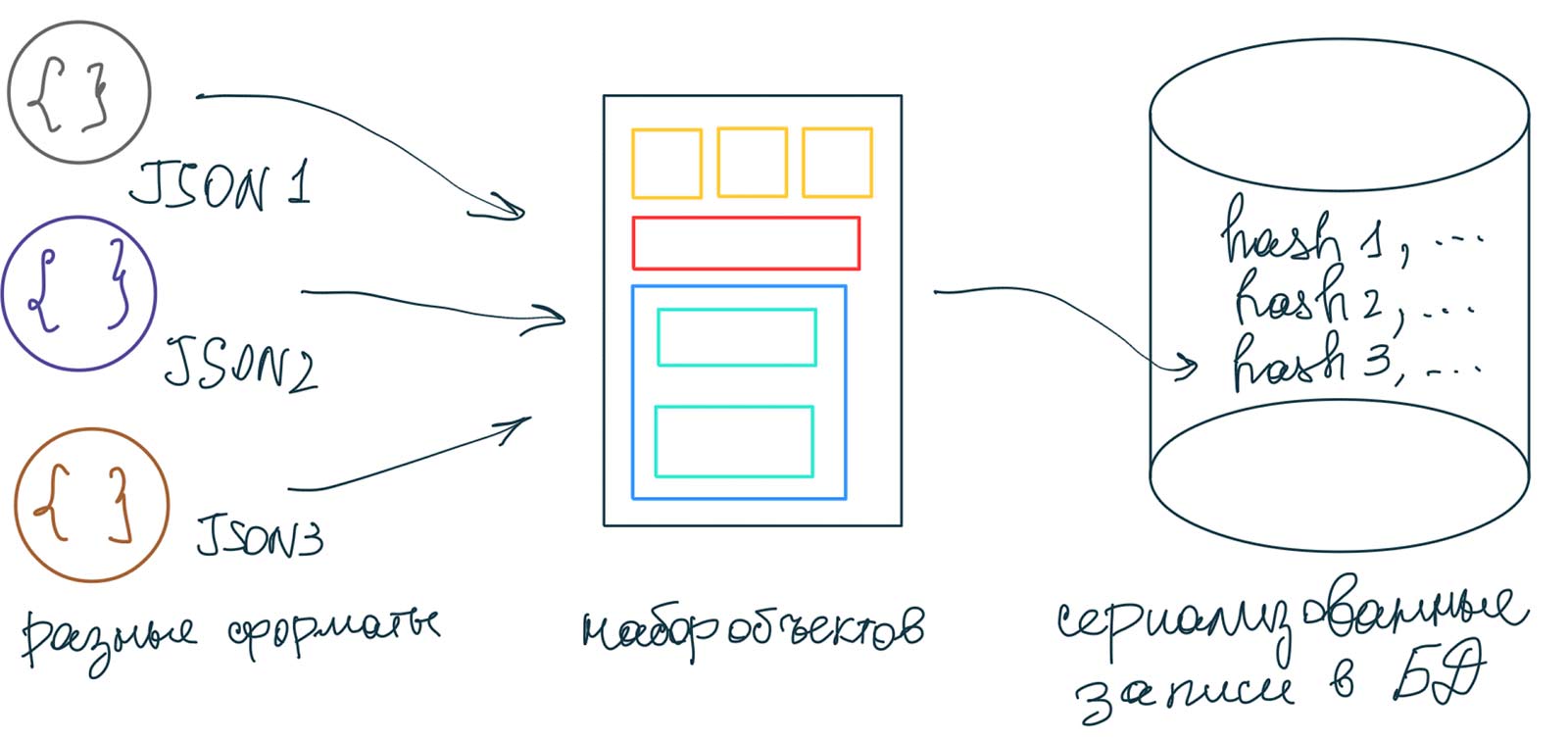
На входе у вас множество источников данных из разных products:
| id | hash | data |
|---|---|---|
| 1001 | e5f8d9c52… | {"color":"red"…} |
| 1002 | 8275b764c… | {"color":"green"…} |
После этого для записи истории цен достаточно вести таблицу price_history:
| product_id | date | price |
|---|---|---|
| 1001 | 1099,9 | |
| 1001 | 1199,9 |
Если в источниках данных появляется новый товар или новая модификация известного товара, метод getHash() вернет неизвестное ранее значение, и в таблицу products добавится новая запись. Если товар ранее уже встречался, значение getHash() уже будет присутствовать в таблице products, и значение для product_id берется из соответствующей записи.
Теперь мы видим, к каким последствиям может привести изменение в алгоритме вычисления хешей. product_id. Вы потратите много времени и сил, пытаясь сначала найти причину проблем, а потом исправлять данные в БД, изменяя идентификаторы и подчищая дубликаты.
Как же решать проблему с изменением алгоритма хеширования? Примерно так же, как изменяется тип колонок в огромных таблицах БД. Для начала напишем новый метод вычисления хеша, инвариантный относительно изменения порядка свойств:
public function getHash2(): string
{
$data = $this->normalize();
ksort($data);
return md5(serialize($data));
}
Далее делаем в таблице БД новую колонку со значением нового хеша. При поиске записей в этой таблице по хешу нужно сначала искать по новой версии хеша, а затем, если ничего не нашли, по старой версии. При добавлении новых записей пока будем записывать значения и новой колонки, и старой. Старые значения хеша всё еще требуются для возможного отката.
После успешной выкладки, если откат не нужен, надо обновить значения новой колонки у старых записей. Это сделает отдельный скрипт, который прочитает все записи, переведет данные в объекты, по объектам посчитает новую версию хешей и выполнит UPDATE.
В завершение можно выкладывать окончательную версию кода, в которой останется только новая версия алгоритма хеширования, и запускать миграцию, которая удалит колонку со старыми версиями хешей.
Вывод
Обычно, когда программист пишет тесты к разрабатываемому приложению, он ориентируется на выполняемые приложением функции. В нашем примере приложение собирает цены из нескольких источников и выводит на странице. Тогда и в тесте сначала импортируется несколько файлов с данными, а затем проверяется, что эти данные выводятся корректно. Это будет означать, что вся цепочка преобразования данных отработала правильно.
Кроме функций приложения, нужно задуматься еще о том, какие предположения делаются в ходе разработки. И эти предположения тоже можно проверять в тестах. Мы разобрали один из примеров, когда предполагалось, что одинаковые данные на входе дадут одинаковые значения хешей. Если забыть о неявном требовании, что хеши не должны меняться со временем (на практике они ведь сравниваются с записанными ранее значениями в БД!), легко написать тесты на саму функцию, которые не упадут при изменении алгоритма хеширования. И вы отправите проблемные изменения в рабочую систему, будучи уверенными, что всё в порядке, так как тесты пройдены.
Как правильно представлять и обрабатывать состояние фильтров в коде
Фильтры в интерфейсах
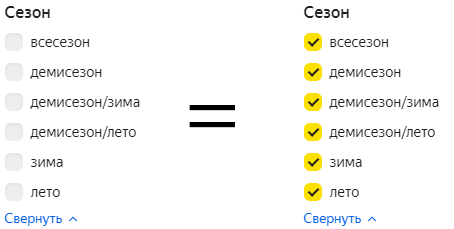
Если рассуждать с точки зрения формальной логики, пустому фильтру нужно было бы сопоставить пустой результат. Но на практике в этом нет смысла. Об этом как раз сегодняшний совет Бюро.
Я хочу рассказать, как правильно обрабатывать в коде эту особенность фильтров. Вообще естественно сопоставить выбранным элементам фильтра элементы массива. В этом случае пустому фильтру будет соответствовать пустой массив. Если мы напишем код из этого предположения, то по всей цепочке передачи состояния фильтра нужно отдельной логикой обрабатывать пустой массив, а это будет громоздко и некрасиво.
Чтобы показать, в чем недостатки кодирования пустого фильтра пустым массивом, рассмотрим типовую операцию — пересечение фильтров. Она требуется, когда мы проверяем права доступа пользователя к выбранным в фильтре элементам. Для иллюстрации представим, что в примере выше есть скрытые сезоны, а в них — скрытые товары. Допустим, мы не хотим продавать летом зимние товары, потому что их нет на складе, и скрываем до следующей зимы. Логика в коде может быть примерно такой:
$filterValues = $request->get('seasons');
$allowedValues = getActiveSeasons();
if ($filterValues === []) {
// В фильтре ничего не выбрано - используем все доступные значения
$intersectValues = $allowedValues;
} else {
$intersectValues = array_intersect($allowedValues, $filterValues);
}
// Получаем список товаров из БД
$result = getProductsByConditions(['seasons' => $intersectValues]);
Мы видим недостаток: $allowedValues и $filterValues обрабатываются несимметрично в этом коде. Пустой массив в $filterValues не приводит к ограничениям списка товаров. А пустой массив в $allowedValues должен приводить к пустому результату. Было бы неправильно отображать товары из всех категорий, после того как я скрыл последнюю доступную категорию.
Представьте теперь, что нам поступило новое требование: администратор должен видеть скрытые товары. Тогда код еще больше усложнится и станет примерно таким:
$filterValues = $request->get('seasons');
$allowedValues = getActiveSeasons();
$conditions = [];
if (grantedHiddenProducts($currentUser)) {
if (!$filterValues === []) {
// Админу фильтруем, только если он сам заполнил фильтр
$conditions = ['seasons' => $filterValues];
}
} elseif ($filterValues === []) {
// В фильтре ничего не выбрано - используем все доступные значения
$conditions = ['seasons' => $allowedValues];
} else {
$intersectValues = array_intersect($allowedValues, $filterValues);
$conditions = ['seasons' => $intersectValues];
}
// Получаем список товаров из БД
$result = getProductsByConditions($conditions);
Я предлагаю интерпретировать значения null. В этом случае множество элементов массива всегда соответствует множеству разрешенных элементов, а null соответствует универсальному множеству — дополнению к пустому множеству.
Если следовать соглашению о кодировке отсутствия ограничений через null, пустой интерфейсный фильтр конвертируется в null в самом начале потока данных. В конце потока при формировании запроса к БД значение null в фильтре игнорируется и в array_intersect() как раз может вернуть пустой массив, если
$filterValues = $request->get('seasons');
if ($filterValues === []) {
// По бизнес-логике если фильтр не выбран, показываем все доступные товары
$filterValues = null;
}
// Скрытые товары показываем только админам
$allowedValues = grantedHiddenProducts($currentUser) ? null : getActiveSeasons();
// Комбинируем ограничения
$intersectValues = array_intersect_sets($allowedValues, $filterValues);
// Получаем список товаров из БД
$result = getProductsByConditions(['seasons' => $intersectValues]);
// ...
function array_intersect_sets(?array $a, ?array $b): ?array {
if ($a === null) {
return $b;
}
if ($b === null) {
return $a;
}
return array_intersect($a, $b);
}
function getProductsByConditions(array $conditions): array {
// ...
if ($conditions['seasons'] !== null) {
if ($conditions['seasons'] === []) {
return [];
}
$queryBuilder->andWhere('p.seasons IN (?)', $conditions['seasons']);
}
// ...
}
В этом варианте в каждом фрагменте кода прозрачная и ясная логика. Функция array_intersect_sets() является симметричной по отношению к перестановке аргументов. Она переиспользуется везде, где нужно применять несколько ограничений одновременно. Из кода пропала проблемная длинная цепочка условных операторов. Раньше при изменении логики фильтрации программист должен был осознать эту цепочку целиком и быть очень внимательным, чтобы не упустить
Как покрыть тестами устаревший код?
Многим разработчикам приходилось поддерживать и дорабатывать устаревшие приложения, в которых никогда не было автотестов. С помощью приемочных тестов библиотеки Codeception можно покрыть
Идея приемочных тестов в том, что приложение тестируется целиком, как есть. Для
Я расскажу на примере S2, как добавлять приемочные тесты в
Проще всего Codeception подключить к проекту через composer:
"require-dev": {
"codeception/codeception": "^4.2",
"codeception/module-asserts": "^2.0.0",
"codeception/module-phpbrowser": "^2.0"
}В проекте нужно создать файл codeception.yml:
suites:
acceptance:
actor: AcceptanceTester
modules:
enabled:
- Asserts
- PhpBrowser:
url: http://localhost:8881
curl:
CURLOPT_TIMEOUT_MS: 120000
После этого файлы тестов можно писать в таком
<?php
use Codeception\Example;
class InstallCest
{
public function tryToTest(AcceptanceTester $I, Example $example): void
{
$I->install('admin', 'passwd', $example['db_type'], $example['db_user'], $example['db_password']);
$I->amOnPage('/');
$I->see('Site powered by S2');
$I->click(['link' => 'Page 1']);
$I->see('If you see this text, the install of S2 has been successfully completed.');
$I->canWriteComment();
}
}Здесь методы amOnPage(), see(), click() — встроенные, а install() и canWriteComment() — мои сокращения, определенные в
<?php
use Codeception\Actor;
class AcceptanceTester extends Actor
{
public function install(string $userName, string $userPass, string $dbType, string $dbUser, string $dbPassword): void
{
$I = $this;
$I->amOnPage('/');
$I->seeLink('install S2', '/_admin/install.php');
$I->amOnPage('/_admin/install.php');
$I->seeResponseCodeIs(200);
$I->see('S2 2.0dev', 'h1');
$I->selectOption('req_db_type', $dbType);
$I->fillField('req_db_host', '127.0.0.1'); // not localhost for Github Actions
$I->fillField('req_db_name', 's2_test');
$I->fillField('db_username', $dbUser);
$I->fillField('db_password', $dbPassword);
$I->fillField('req_username', $userName);
$I->fillField('req_password', $userPass);
$I->click('start');
$I->canSeeResponseCodeIs(200);
$I->see('S2 is completely installed!');
}
public function canWriteComment(): void
{
$I = $this;
$name = 'Roman 🌞';
$I->fillField('name', $name);
$I->fillField('email', 'roman@example.com');
$I->fillField('text', 'This is my first comment! 👪🐶');
$text = $I->grabTextFrom('p#qsp');
preg_match('#(\d\d)\+(\d)#', $text, $matches);
$I->fillField('question', (int)$matches[1] + (int)$matches[2]);
$I->click('submit');
$I->seeResponseCodeIs(200);
$I->see($name . ' wrote:');
$I->see('This is my first comment!');
}
}Теперь посмотрим, как это всё запускается. Я написал отдельный скрипт:
# Очистка тестовой базы данных
mysql -uroot --execute="DROP DATABASE IF EXISTS s2_test; CREATE DATABASE s2_test;"
# Запуск веб-сервера
APP_ENV=test \
PHP_CLI_SERVER_WORKERS=2 \
nohup php \
-d "max_execution_time=-1" \
-d "opcache.revalidate_freq=0" \
-S localhost:8881 >/dev/null 2>&1 &
serverPID=$!
# Запуск тестов
php _vendor/bin/codecept run acceptance
pkill -P $serverPID # Убиваем воркеры PHP, образовавшиеся из-за PHP_CLI_SERVER_WORKERS
kill $serverPIDПеред запуском тестов поднимается встроенный в php http://localhost:8881/. PHP_CLI_SERVER_WORKERS=2), так как движок в процессе установки обращается сам к себе, чтобы понять, какая схема перезаписи URL доступна. В процессе установки создается файл config.php. Чтобы PHP сразу видел изменения в этом файле, пришлось переопределить параметр из php.ini: opcache.revalidate_freq=0. Альтернатива — добавить sleep(), но я не хотел играться с ненадежными способами. Переменная окружения APP_ENV=test говорит движку, чтобы он вместо файла config.php создавал и использовал файл config.test.php. Это упрощает запуск и тестов и обычной версии для разработки из одной папки.
Достоинства получившегося способа написания приемочных тестов следующие. Устаревший код приложения практически не нужно дорабатывать, чтобы писать тесты. Так как приложение тестируется через HTTP API, внутренние изменения в приложении, не меняющие API, не требуют доработки тестов. Тесты запускаются где угодно, я даже добавил запуск тестов в github actions при каждом пуше веток.
Недостатки, как обычно, есть продолжения достоинств. Тесты покрывают только серверную часть,
Http-прокси на PHP
Обычно в постах о программировании я пишу об успешных подходах и находках. В этот раз расскажу об идее, которая на практике не заработала.
В прошлый раз я рассказывал, что если у вас есть свой виртуальный сервер, вы можете не возиться с VPN, а отправить трафик из браузера через
Я задумался, можно ли провернуть такой же трюк без своего виртуального сервера. Стал смотреть в сторону виртуальных (shared) хостингов, в частности бесплатных или предоставляющих бесплатный тестовый период. На hostings.info нашел бесплатный хостинг с доступом по SSH. Трюк с
Я стал думать дальше и решил попробовать другой вариант. На сервере хостера запущен PHP. Я могу подключиться к нему через обычный
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Psr7\Request;
use GuzzleHttp\Psr7\ServerRequest;
// Создание экземпляра клиента Guzzle
$client = new Client();
// Обработка входящего запроса
$request = ServerRequest::fromGlobals();
// Получение URL-адреса запрашиваемого сайта
$url = $request->getUri();
$url
// Я собирался ходить на https-сайты, поэтому подменил протокол и порт
->withScheme('https')
->withPort(443)
// Подменяем хост (видимо, тут и происходит обработка протокола http-прокси)
->withHost($request->getHeaderLine('host'))
->withQuery($request->getUri()->getQuery())
;
// Создание прокси-запроса
$proxyRequest = new Request(
$request->getMethod(),
$url,
$request->getHeaders(),
$request->getBody(),
$request->getProtocolVersion()
);
// Отправка прокси-запроса и получение ответа
$response = $client->send($proxyRequest, [
'stream' => true,
'verify' => false,
'allow_redirects' => false, // Коды редиректов отправляем назад в браузер
]);
// Передача заголовков ответа клиенту
foreach ($response->getHeaders() as $name => $values) {
foreach ($values as $value) {
header(sprintf('%s: %s', $name, $value), false);
}
}
// Передача тела ответа клиенту
echo $response->getBody();
Чтобы этот скрипт завести, нужно сохранить его в файл со произвольным редким названием, например, q7e6r53t.php, и установить через composer библиотеку guzzle. Кроме того, в nginx в настройку хоста надо добавить следующее:
server {
listen 8082;
server_name localhost;
root /mnt/c/git/proxy;
location / {
try_files $uri $uri/ /q7e6r53t.php$is_args$args;
}
location ~ \q7e6r53t.php$ {
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_index index.php;
include fastcgi.conf;
}
}
В таком варианте прокси заработал локально, даже с авторизацией и куками. Самый большой недостаток этого подхода в том, что нельзя проксировать
127.0.0.1 - - [18/Jun/2023:12:56:47 +0300] "CONNECT www.google.com:443 HTTP/1.1" 400 166 "-" "-"И даже если вдруг представить, что такое возможно, это был бы man in the middle. Поэтому в браузере приходится набирать адрес сайта с http, а скрипт подменяет протокол на https. Если в PHP нет нужных сертификатов, подключиться к сайту будет невозможно. Для отключения проверки сертификатов я добавил флаг 'verify' => false. Конечно, это несекьюрно, но тут и так трафик передается хостеру в открытом виде, так что держать ворота запертыми в открытом поле смысла нет :)
На практике у хостера этот скрипт не заработал. В браузере отображалась страница ошибки Apache о неправильно сконфигурированном хосте. Очевидно, Apache настроен так, чтобы не позволять так просто делать
В ходе лабораторной работы мы написали простейший скрипт
Как разработать систему рекомендаций ★
Продолжим разговор о системе рекомендаций в S2. Эта система подбирает к каждой заметке набор других заметок, которые посетитель может почитать дальше. В прошлый раз я рассказал об этой системе в целом, сейчас же опишу алгоритм подбора самих рекомендаций.
За рекомендации в моем случае отвечает движок полнотекстового поиска Rose. Структура данных в полнотекстовом индексе как раз подходит для задачи подбора похожих заметок. Если совсем упростить, то получается, что обычный поиск — это подбор подходящих заметок к словам из поискового запроса, а рекомендации к заметке — это подбор других заметок по словам из нее. А теперь давайте погрузимся в детали.
Теория рекомендаций
Для начала давайте поймем, как вообще могут работать системы рекомендаций. Рассуждать будем на примере существовавшего
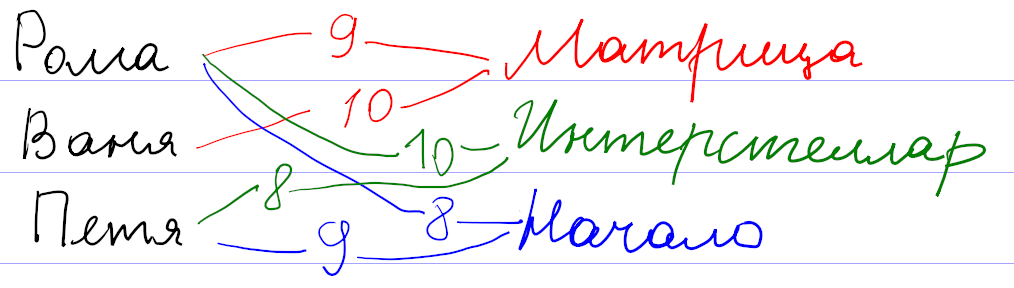
Оценки пользователей сохраняются как веса связи
Математика позволяет предложить более формальный и универсальный подход. Будем рассматривать оценки к фильмам как координаты некоторой точки во многомерном пространстве всех фильмов. Тогда всех пользователей можно представить как множество точек в таком пространстве. При достаточном количестве они начнут группироваться в кластеры по разным предпочтениям. После этого задача подбора рекомендаций сведется к поиску соответствующего кластера.
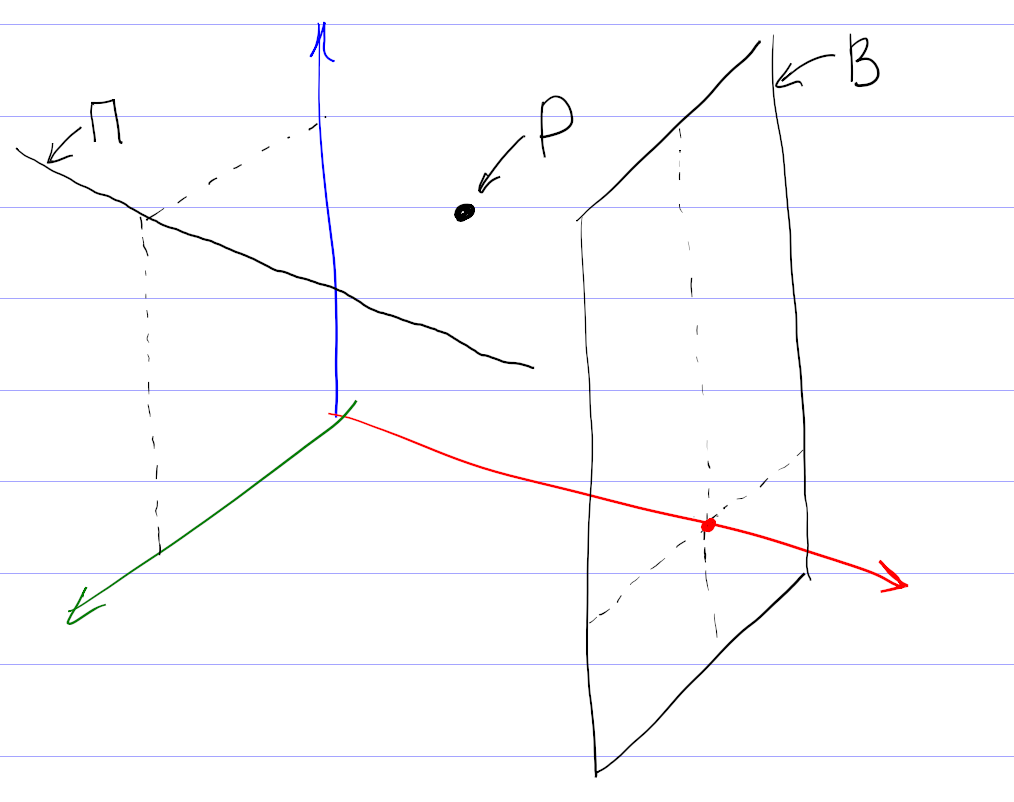
На самом деле, картина сложнее, так как никто не может поставить оценки всем фильмам. Поэтому вместо точек мы имеем дело с некоторыми подпространствами (прямыми, плоскостями и т. д.). Чтобы сформировать мои рекомендации, система проецирует все оценки на подпространство просмотренных мной фильмов, находит кластер в проекции, и по нему уже пытается восстановить кластер в полном пространстве.
Понятно, что процедура восстановления кластера из проекции неоднозначна, и в этом месте система рекомендаций может ошибаться, даже если в ней собраны оценки большого количества пользователей. Например, по оценкам фильмов, единогласно оцениваемых зрителями, нельзя восстановить предполагаемую оценку и однозначно рекомендовать фильм, мнения по которому разделились на два равновеликих полюса.
Эта теория прекрасно выглядит на листе бумаги. Но я уверен, что при практической реализации разработчики столкнулись с кучей проблем. Очевидная проблема — нормировка оценок. Например, у меня средняя оценка была около 7. Оценки меньше 4 я практически не ставил. Задумывался над тем, чем отличается оценка 9 от 10. Оценки других пользователей наверняка отличались по характеристикам.
Вы наверняка встречались с другим примером системы рекомендаций: поиском друзей в соцсетях. Здесь тоже работает связь
Теперь давайте посмотрим, как можно эти знания применить для подбора рекомендаций заметок.
Рекомендации на основе тегов
Как видно из предыдущего рассмотрения, систему рекомендаций можно сделать везде, где есть связь
Недостатки подхода лежат на поверхности.
Рекомендации на основе похожих текстов
В движке S2 есть другая связь
| word_id | toc_id | positions |
|---|---|---|
| 1 | 1 | 0,37 |
| 3 | 4 | 0,15,74,193,614 |
| 3 | 8 | 94 |
| 3 | 9 | 73 |
| 4 | 1 | 3,16,57 |
| … |
В первой колонке хранится id «слова», во второй — внутренний id проиндексированного элемента (ToC — это сокращение от table of contents), в третьей — положения соответствующего слова в проиндексированном тексте.
При индексации исходный текст заметок очищается от
При поиске запрос преобразуется по такой же схеме: слова заменяются на идентификаторы word_id, и из поискового индекса мы получаем информацию о том, в каких проиндексированных текстах (toc_id) встречались эти слова. Положения слов (positions) нужны для вычисления релевантности: чем ближе слова из запроса друг к другу в тексте, тем выше окажется этот текст в выдаче.
Рекомендации на основе близости текста тоже используют эту таблицу. У меня получилось уместить все существенные вычисления в один
SELECT
relevance_info.*, -- информация из подзапроса
m.images, -- добавляем к ней информацию о картинках
t.*, -- добавляем к ней оглавление
-- и первые 2 предложения из текста
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1) AS snippet,
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1 OFFSET 1) AS snippet2
FROM (
SELECT -- Перебираем все возможные заметки и вычисляем релевантность каждой для подбора рекомендаций
i.toc_id,
round(sum(
original_repeat + -- доп. 1 за каждый повтор слова в оригинальной заметке
exp( - abn/30.0 ) -- понижение веса у распространенных слов
* (1 + length(positions) - length(replace(positions, ',', ''))) -- повышение при повторе в рекомендуемой заметке, конструкция тождественна count(explode(',', positions))
) * pow(m.word_count, -0.5), 3) AS relevance, -- тут нормировка на корень из размера рекомендуемой заметки. Не знаю, почему именно корень, но так работает хорошо.
m.word_count
FROM fulltext_index AS i
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) ON m.toc_id = i.toc_id
JOIN (
SELECT -- достаем информацию по словам из оригинальной заметки
word_id,
toc_id,
(SELECT count(*) FROM fulltext_index WHERE word_id = x.word_id) AS abn, -- распространенность текущего слова по всем заметкам
length(positions) - length(replace(positions, ',', '')) AS original_repeat -- сколько раз слово повторяется в оригинальной заметке. Выше используется как доп. важность
FROM fulltext_index AS x FORCE INDEX FOR JOIN(toc_id)
JOIN toc AS t ON t.id = x.toc_id
WHERE t.external_id = :external_id AND t.instance_id = :instance_id
AND length(positions) - length(replace(positions, ',', '')) < 200 -- отсекаем слишком частые слова. Хотя 200 слишком завышенный порог, чтобы на что-то влиять
HAVING abn < 100 -- если слово встречается более чем в 100 заметках, выкидываем его, так как слишком частое. Помогает с производительностью
) AS original_info ON original_info.word_id = i.word_id AND original_info.toc_id <> i.toc_id
GROUP BY 1
HAVING count(*) >= :min_word_count -- количество общих слов, иначе отбрасываем
) AS relevance_info
JOIN toc AS t FORCE INDEX FOR JOIN(PRIMARY) on t.id = relevance_info.toc_id
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) on m.toc_id = t.id
ORDER BY relevance DESC
LIMIT :limitОпишу ключевые шаги, которые здесь выполняются.
1. Взять все слова в заметке, к которой подбираем рекомендации. Я называю эту заметку оригинальной. Выбор слов происходит в самом внутреннем подзапросе.
2. Выкинуть распространенные слова. Это нужно делать для повышения точности и при поиске, и при подборе рекомендаций. Можно даже составить список игнорируемых слов вроде союзов или предлогов. Но вместо составления такого неизменяемого списка я вычисляю распространенность (abundance, сокращенно abn — количество заметок, в которых встречается это слово) для каждого слова в индексе. Например, в блоге о дизайне в каждой заметке будет слово «дизайн», и его тоже надо игнорировать.
Слова с распространенностью больше 100 наверняка окажутся слишком общими, и я отбрасываю их по соображениям производительности. Скорее всего порог должен
3. Найти одинаковые слова у оригинальной заметки с остальными заметками. Это происходит в промежуточном подзапросе. У заметок при этом должно быть достаточное количество общих слов (порог определяется параметром min_word_count).
Я пробовал разные значения параметра. Если увеличивать, количество рекомендаций падает. Если уменьшать, в рекомендации попадают не очень подходящие заметки за счет случайного использования общих слов. Я остановился на варианте, когда запрос сначала выполняется со значением 4. Если результатов нет, как это часто бывает у коротких заметок, то запрос повторяется со значением параметра 2.
4. По повторяющимся словам вычислить релевантность. Это тоже происходит в промежуточном подзапросе в выражении в селекте благодаря group by. Релевантность я вычисляю как количество повторений общих слов. Чтобы понизить влияние распространенных слов, я добавил ослабление за счет веса exp(-abn/30.0). Хотел было использовать колоколообразную функцию типа exp(-sqr(abn/30.0)), но на практике линейное уменьшение веса при малых значениях распространенности повысило качество рекомендаций.
Кроме того, повторы в оригинальной заметке (original_repeat) и в рекомендуемых заметках влияют на релевантность несимметрично: повторяющиеся слова в оригинальной заметке не ослабляются, даже если они распространены. Объяснение можно предложить такое: если автор пишет одинаково часто о шахматах и шашках, то к оригинальной заметке с пятью словами «шахматы» и одним словом «шашки» лучше рекомендовать заметку с одним словом «шахматы», чем с пятью словами «шашки». Эффект несимметричности я не закладывал специально. Практика показала, что отсутствие ослабления у original_repeat субъективно улучшает качество рекомендаций.
Несимметричность веса оригинальной заметки и рекомендуемых может быть даже полезной, чтобы избежать «зацикливания» рекомендаций, когда к заметке А мы рекомендуем заметку Б, а к заметке Б — заметку А. Правда, у меня этот критерий не был обязательным, и я не проверял, как он выполняется. Применительно к моему сайту эффект зацикливания может ослабляться ещё и за счет последующего предпочтения в рекомендациях заметок с картинками.
Последний множитель в релевантности pow(m.word_count, -0.5) учитывает размер рекомендуемой заметки в словах. Без него в моем случае среди рекомендуемых оказывались очень длинные заметки, набиравшие релевантность за счет большого количества повторяющихся слов средней распространенности. Тогда я подумал, что сортировать рекомендации нужно не по абсолютному количеству общих слов, а по относительному, то есть надо поделить вычисленную релевантность на количество слов в рекомендуемой заметке. В рекомендации стали попадать короткие заметки всего из нескольких слов, а у нормальных заметок из нескольких сотен слов релевантность сильно просела. Чтобы было ни нашим ни вашим, я попробовал поделить абсолютную релевантность на корень из длины рекомендуемой заметки, и это сработало: с первых мест рекомендаций ушли как очень короткие, так и очень длинные заметки. Изменение показателя степени −0,5 в обе стороны приводило к некоторому повышению ранга одних и понижению ранга других таких нерелевантных заметок.
У меня не было объяснения, почему нормировка релевантности именно на корень из длины оказалась подходящей. Но в момент набора этого текста появилась гипотеза. Нормировка на длину рекомендуемых заметок не учитывает длину оригинальной заметки. Но для подбора рекомендаций к одной оригинальной заметке ее длина ни на что не влияет. Возможно, что для более общей задачи подбора рекомендаций к N оригинальным заметкам релевантность нужно нормировать на среднее геометрическое из длин оригинальной и рекомендуемой заметок. Тогда для одной оригинальной заметки ее длина превратится в несущественный постоянный коэффициент и уйдет за скобки, а длина рекомендуемой заметки как раз окажется в знаменателе под корнем.
5. Получить заголовок, картинки и фрагмент текста. Это неинтересная техническая задача, решаемая во внешней части запроса. Для «сниппетов» — коротких фрагментов текста — я достаю первые два предложения из заметок. Сначала думал выводить те предложения из текста, которые содержат общие слова. Зависимость сниппетов от контекста как раз бы показала, почему рекомендуется именно эта заметка. Но
Вопросы производительности
В запросе вы видите явное указание использовать конкретные индексы. Без них планировщик не использовал часть индексов. Почему он так решал — непонятно. За счет расстановки хинтов я оптимизировал запрос раз в 20 до нескольких десятков миллисекунд. Я последние 6 лет работаю с PostgreSQL, и он даже думать отучил, что в запросы можно добавить хинты. Но тут пришлось.
Производительность в несколько десятков миллисекунд я посчитал достаточной, чтобы выполнять
При работе на настоящем сервере выяснилось, что в режиме невысокой нагрузки база данных может иногда выполнять запрос существенно дольше — несколько сот миллисекунд или даже больше секунды. Вот данные мониторинга по средней длительности запроса:
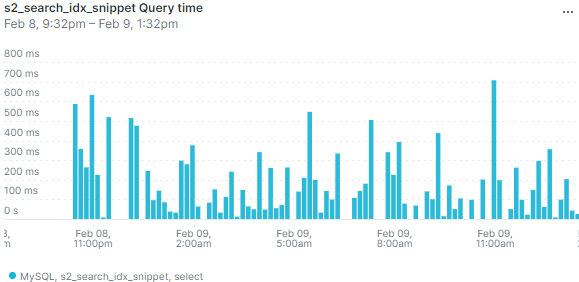
Выбросы на графике означают, что иногда пользователи будут замечать, что страница долго открывается. И изредка приходящий
Я добавил кеширование подбора рекомендаций. Кеш инвалидируется не по времени, а по обновлению заметок. Правда, мне пришлось инвалидировать весь кеш рекомендаций при любом изменении опубликованных заметок. Действительно, изменение хотя бы одного слова в
Кеш хорошо решает проблему с редкими выбросами, даже если заметки часто обновляются. Если в кеше есть устаревшие рекомендации, всё равно выводятся они, а в фоне в это время просчитываются новые рекомендации.
Я так и не понял, почему возникают такие всплески времени выполнения запроса. Не думаю, что конкуренция MySQL за процессорное время с PHP или Похоже, проблема связана с нагрузкой на гипервизор от соседних виртуальных машин.
Направления развития
- Убрать из запроса захардкоженные числа.
- [✓] Если рекомендаций с четырьмя общими словами нет, делать повторный запрос с ослабленным ограничением. А вообще тут важно найти баланс: надо ли показывать неподходящие рекомендации, если нет подходящих?
- Получать сниппеты из релевантных предложений, а не первых двух.
Дополнение о нормальной форме
Внимательный читатель отметил, что таблица полнотекстового индекса не находится даже в первой нормальной форме: в одной ячейке positions через запятую перечислен список положений слова. Что хорошо в теории, не всегда хорошо в настоящем работающем софте. Раньше действительно структура этой таблицы была другой, и каждый элемент из positions располагался на своей строке. Для корректной работы алгоритма мне нужно было обеспечить уникальность строк, поэтому элементы (word_id, toc_id, position) я еще добавил в уникальный индекс.
Достаточно быстро в целях оптимизации я отказался от индекса по word_id и повесил первичный ключ сразу на все колонки (word_id, toc_id, position). В этом есть смысл, так как первичный индекс в InnoDB кластерный, то есть данные строк хранятся на диске вместе с первичным индексом.
Сейчас я пошел в оптимизации дальше и отказался от нормальной формы для хранения положений. Базы данных устроены так, что в таблицах в каждой строке хранится дополнительная служебная информация. Объединение нескольких строк с одинаковыми word_id и toc_id в одну дало экономию места в полтора раза (поисковый индекс в целом уменьшился с 22 до 14 мегабайт при суммарном объеме заметок 2,8 мегабайт). Кроме того, скорость индексации тоже выросла примерно в полтора раза, так как сократилось количество выполняемых запросов. Я не обнаружил
Понятно, что отказ от нормальной формы — не универсальное решение. Так, в рассматриваемом примере пропала возможность фильтрации по полю position. Для задач поиска в этом ничего страшного нет, так как в них фильтрация по position не встречается. Хотя по большому счету мало что изменилось: фильтрацию всё еще можно делать через операции с поиском подстроки, и это не будет сильно медленнее, потому что и раньше по полю position отдельного индекса не было.
Мастер костылей, или сущности в DOMDocument
Я тут решил потратить некоторое время на собственные проекты. Сейчас перерабатываю движок для поиска Rose. На нем работает поиск на этом сайте, также его использует Илья Бирман в Эгее.
Для извлечения текста из
Как оказалось, DOM API не поддерживает HTML5. Это выливается в практическую проблему с непоследовательной обработкой сущностей HTML. Например, если в исходнике написать & ★, при получении текстового содержимого из & ★. Видим, что первая сущность из HTML предыдущих версий распознается и раскодируется, а вторая из HTML5 — нет. Такие ошибки приведут к искажениям при выводе сниппетов.
Моя первая идея — прогнать текстовое содержимое через html_entity_decode($a, ENT_HTML5);. Действительно, что не доделал встроенный парсер, доделает эта функция. Но проблема в том, что раскодирование неидемпотентно. Если на вход подать &bigstar;, то после DOM API мы получим ★. И на этапе повторного раскодирования мы не будем знать, нужно ли раскодировать ★ еще раз, или нет.
Поиск проблемы в гугле разумного решения не выявил. В классе DOMDocument есть
Для начала нужно все вхождения амперсанда заменить на его сущность:
$text = str_replace('&', '&', $text);После этого DOM API раскодирует копии только одой сущности — этого самого амперсанда. При рекурсивном обходе в текстовом содержимом узлов html_entity_decode($a, ENT_HTML5);.
Уже который раз убеждаюсь, что искусство программиста во многом заключается в умении подобрать нужный костыль. Так и живем.
Деление на код и данные в ООП
Любая программа, выполняемая на современных процессорах, состоит из данных и кода — набора инструкций, обрабатывающих эти данные. Такое деление четко прослеживается как в ассемблерном коде, так и в процедурных языках.
В
Правильный код в стиле ООП разделяет
Читайте о правильном подходе в статье Дмитрия Елисеева «Структуры с процедурами или объекты?». Он подробно разобрал тезис о разном применении разных типов объектов и проиллюстрировал всё на примерах для PHP.
Связь между физикой и программированием: абстракции и язык — В кресле препода №6
Я заметил нетривиальную связь между физикой и программированием. Она находится в области используемых и там и там абстракций и обозначений. Записал видео с объяснением и примерами.
Придумал название «В кресле препода» для таких видео, где я обсуждаю
00:00:47 Зачем слушать этот рассказ
00:01:33 Замечание о формате презентаций
00:03:15 План рассказа
00:04:01 Математический аппарат физических теорий
00:05:39 Механика Ньютона и двойной маятник
00:09:45 Уравнения Максвелла: векторная и компонентная форма записи
00:14:17 Четырехвекторы и скорость света
00:18:01 Принцип наименьшего действия
00:21:25 Разнообразие форм уравнений Максвелла
00:23:41 Причем здесь программирование?
00:28:28 Уровни абстракций в языках программирования: физический, процедурный, ООП
00:33:26 Кто создает больше абстракций: физик или программист?
00:37:23 Практический пример
00:41:21 Разбор примера обработки
00:48:50 Переписывание примера из документации в объектном стиле и добавление функциональности на примере головоломки Арнольда (исходник на гитхабе)
01:17:58 О «пользе» MVC и что такое ООП на самом деле
01:20:35 Сравнение процедурного и объектного подходов и принцип High Cohesion Low Couping
01:23:42 Наследования и полиморфизма нет, а дух ООП есть
Описание головоломки Арнольда в предыдущем посте и на хабре.
Одновременная вставка уникальных значений в словарные таблицы — В кресле препода №3
Как правильно добавлять данные в словарную таблицу с уникальными строками одновременно из нескольких потоков? В PostgreSQL вот так:
CREATE TABLE words (
id SERIAL PRIMARY KEY,
word TEXT NOT NULL UNIQUE
);
BEGIN;
SELECT id FROM words WHERE word = 'a';
INSERT IGNORE INTO words (word) VALUES ('a');
SELECT id FROM words WHERE word = 'a';
COMMIT;В видео рассказываю, почему именно так, и показываю, как это работает.
00:25 Пример
01:34 Демонстрация наивной реализации вставки в словарные таблицы
02:32 Недостаток: появление дублей
03:45 Демонстрация уникального индекса
04:47 Недостаток одного только уникального индекса
05:55 Нет поддержки целостности ⇒ нужны транзакции
06:37 Демонстрация параллельной вставки в таблицу с уникальным индексом в транзакции
08:59 Вставка с игнорированием
09:17 Демонстрация вставки с игнорированием в транзакции с уровнем READ COMMITTED
12:15 Демонстрация дедлока при вставке с игнорированием в транзакции с уровнем REPEATABLE READ
13:44 Особенности метода в MySQL
Кеширование и условие гонки
Одна из важных идей в программировании — кеширование. Если
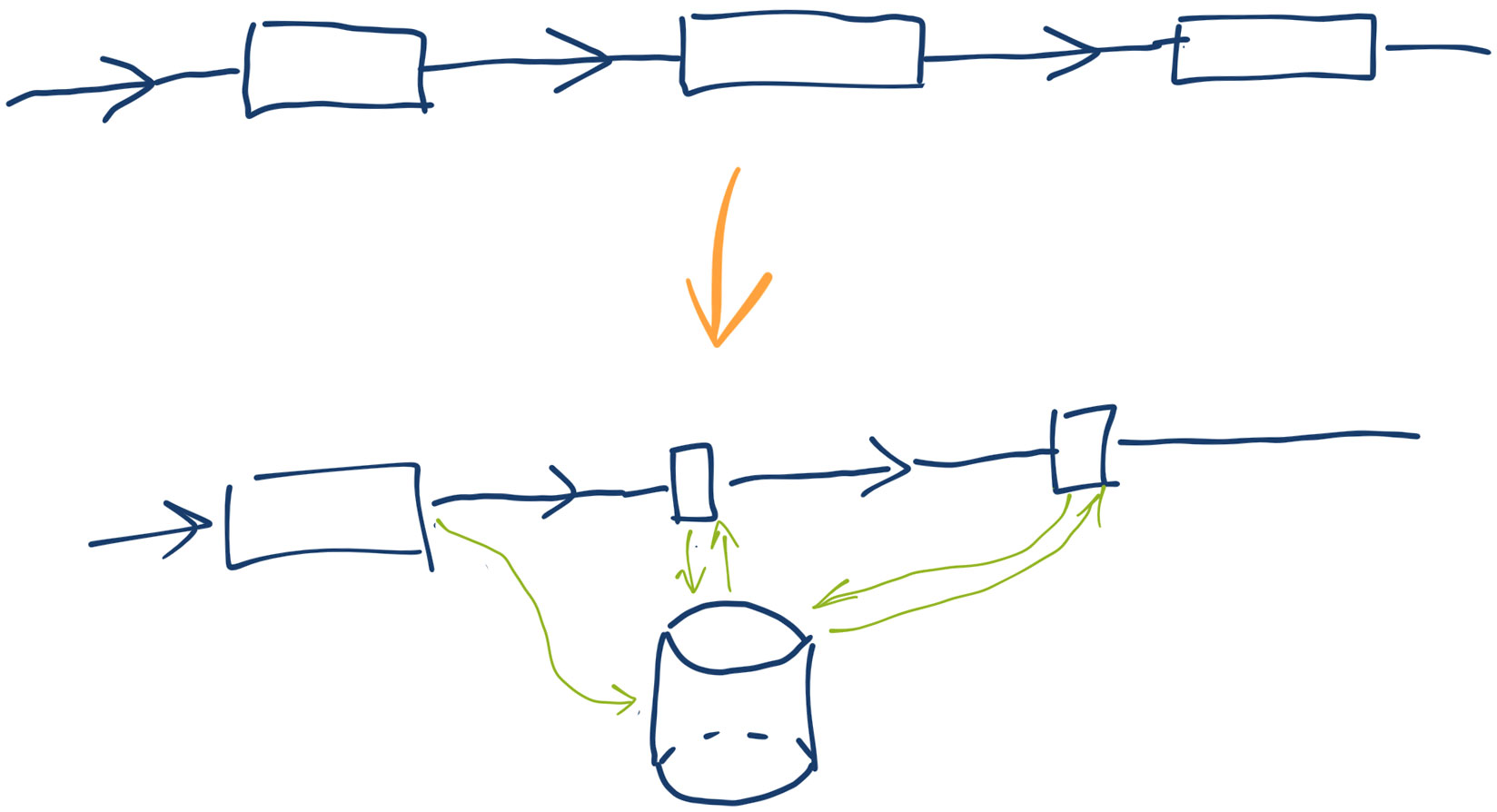
Кеширование не только экономит ресурсы и делает систему более отзывчивой. Без кеширования долгих операций система в принципе не сможет работать в режиме высокой нагрузки. Если вы разрабатываете кеширование в такой системе, важно помнить об одной частой ошибке проектирования — условии гонки (race condition). Расскажу об этой проблеме на выдуманном примере главной страницы
Предположим, на главной странице
235 запросов в минуту — вроде как не очень мало. Но сайт быстро ляжет, если ссылку разместят на
Если запрос к базе данных выполнить один раз и запомнить список наиболее популярных товаров, скажем, на час, то сервер сможет выдержать до
Однако запомнить результаты выполнения запроса недостаточно. Рано или поздно они устареют, и список популярных товаров надо пересчитать заново. Здесь и кроется та самая ошибка — условие гонки. Если результаты выполнения запроса устареют сразу для всех посетителей, и этих посетителей много, тяжелый запрос начнет выполняться одновременно.
Одновременное выполнение тяжелого запроса — неприятная ситуация по многим причинам:
- Несколько конкурентных запросов могут нагружать базу данных и выполняться медленнее, чем один запрос.
- Процессы приложения вместо полезной работы будут ждать окончания выполнения долгих запросов (если, конечно, у вас не асинхронная архитектура; хотя я сомневаюсь, что в этом случае вы бы стали сейчас читать в интернете об условии гонки). При достаточном количестве посетителей 20 процессов израсходуются очень быстро, и сайт перестанет открываться, пока, наконец, не завершится выполнение долгих запросов.
- Кроме того, если вы еще и допустили ошибку при программировании самого кеша, и система записывает данные в него неатомарно (например, в файл с помощью fopen/fwrite, file_put_contents и т. д.), вы с большой вероятностью получите испорченные данные (записанные вперемешку байты из разных процессов). Если система не готова к некорректным данным в кеше, она может вообще перестать работать, пока не посчитает, что данные в кеше устарели. А если готова — продолжит пытаться выполнить тяжелый запрос в конкурентном режиме и не восстановится до тех пор, пока не посчастливится записать корректные данные в кеш, или пока не упадет нагрузка.
Как избежать условия гонки? Есть два способа.
Синхронизировать параллельные процессы. Один из процессов «прогревает кеш» (выполняет долгую операцию). Остальные понимают, что процесс прогрева идет, и всё еще используют устаревшие данные из кеша. Способ не требует глубокой переработки приложения и подходит в простых случаях. Но универсальных методов синхронизации процессов не существует. Придется подбирать подходящий: блокировка файлов (flock), блокировки в базе данных, редисе и т. д.
Прогревать кеш в фоне. Если вы хотите обновлять список популярных товаров каждый час, вычисляете его по расписанию и складываете в кеш из отдельного процесса, который не имеет отношения к обработке
Очередь на основе PHP-FPM
Применил на практике прием, когда асинхронная очередь обработки сообщений реализовывается через
Обычно
Положительные стороны:
- Не нужны дополнительные компоненты в системе.
PHP-FPM сам заботится о запуске рабочих процессов, достаточно отредактировать конфиг.
Отрицательные стороны:
- Нет надежного хранения сообщений. Если процесс
PHP-FPM упадет, сообщения потеряются. - Нет мониторинга. Если нужен — придется делать самостоятельно.
Чтобы сделать такую очередь, возьмите готовые библиотеки для общения по протоколу fastcgi, например,
Спагетти-код
Большой перевод на Хабре про
Автор рассказывает о
Объектно-ориентированное программирование, первоначально разработанное для предотвращенияспагетти-кода, стало(из-за использования без полного понимания «паттернов проектирования») одним из худших его источников. «Объект» может спокойно совмещать в себе код и данные, имея при этом любое количество интерфейсов, в то же время класс может свободно порождать подклассы по всей программе.Объектно-ориентированное программирование таит в себе большую мощь, и при дисциплинированном использовании, оно может быть очень эффективно. Но большинство программистов не могут с этим справиться, и со временем их код превращается в спагетти.
Потом рассматривается «Большой код» вообще. Автор заявляет, что у нас вообще нет хороших методов разработки «Большого кода», и противопоставляет его философии Unix — сделай одну вещь, и сделай ее хорошо.
История программирования в СССР
История программирования в СССР (первая часть, вторая часть). Написано интересно и легко читается. Вот, например, про
Давным давно, еще в докомпьютерную эру (с двадцатых годов) применялись для изображения последовательных процессов или алгоритмов
блок-схемы (flowcharts). На них отдельные элементарные (на данном уровне абстракции) шаги изображались прямоугольничками, последовательность шагов — стрелочками, а ветвления (проверки условий) ромбиками. Всамом-самом начале, когда языков программирования еще не было, а программы непосредственно кодировались числовыми кодами или, в лучшем случае, писались в «содержательных обозначениях», как рекомендовал патриарх нашего ремесла Александр Львович Брудно,блок-схемы были важным подспорьем. В таковом качестве во время оно их и застандартизировали.Прошли десятилетия, то есть минули целые эпохи. А от программистов
по-прежнему требовали чертить эти чертовы стрелочки и ромбики. Смысла в этом было аж никакого.Во-первых, теоретически доказано, что любой алгоритм, записанный на языке высокого уровня (на любом языке) имеет эквивалентное графическое представление в видеблок-схемы и почти наоборот, любая правильнаяблок-схема (фишка тут в слове «правильная») эквивалентна некоторому тексту на том или ином языке программирования. Но текст программы завсегда лучшеблок-схемы, хотя бы потому, что последней можно только любоваться, а первый — это реальный кусок программы, который компилируется и выполняется на машине. Есть разница?Во-вторых, блок-схема может показать только синхронный, строго последовательный процесс вычислений, а в жизни такое наблюдается разве что в небольших несложных программах. Реальные же системы — это не однопоточные алгоритмы, а целые искусственные миры, где множество населяющих ихобъектов-персонажей (как программных, так и аппаратных) взаимодействуют друг с другом, посылая в непредсказуемые моменты времени сигналы и возбуждая прерывания, и где множество потоков вычислений исполняются одновременно и асинхронно, порой еще и на множестве процессоров и машин. Получается, чтоблок-схемами можно проиллюстрировать только маленькие кирпичики, но никак не всю систему, но зачем дополнительно иллюстрировать то, что и так внятно и понятно (с комментариями) записывается в текстовом виде?Казалось бы, не нужны, так не пользуйтесь. А действительно не нужны — любой программист, хоть разработчик, хоть представитель заказчика предпочтет посмотреть исходный текст программы, а не эти картинки. Непрограммисту они — тем более до лампочки. И только ГОСТу, в лице его полномочного представителя — нормоконтролера, они нужны. Дороги как произведения изобразительного искусства. Он их проверяет на соответствие требованием оформления —
такая-то ширина линий,столько-то миллиметров длина стрелочки,такой-то отступ квадратика от ромбика… Смысл схемы контролеру совершенно недоступен. Можете себе представить, какая халтура там процветала? В нашей конторе (как и в сотнях и тысячах таких же контор по всему Союзу) сиделитетки-чертежницы и тушью на кальках рисовали никому не нужные стрелочки и ромбики. Зато безработицы не было! Уже Союз загибался, но в девяностом году, если не ошибаюсь, успели под занавес выпустить новый ГОСТ все на ту же тему рисованияблок-схем. Какая-то навязчивая, неотвратимая мания. Ну да ладно…
Почему я никогда не стану настоящим программистом
Я не смогу стать настоящим программистом. Это было понятно давно. Но только что я смог сформулировать, почему. Потому, что я слишком консервативен и ленив для изучения новых технологий, если старые успешно работают.
Я заинтересовался Паскалем еще до того, как мы его начали проходить в школе, потому что это позволило мне
Я начал программировать на Delphi, потому что это почти что Паскаль :) И еще потому, что на нем легко делать интерфейсы. Но вот делать
Я принялся за изучение PHP, потому что он был на моем хостинге и мне хотелось «оживить» свой сайт. Но браться за Python или Ruby я не вижу смысла.
То же самое и с
Для меня Java, .NET, MVC, XML, x64 и остальное X — пустой звук. Уж лучше играться с
Delphi 2009 и не только
Я давно уже собираюсь выпустить новую версию The Game of Life, 3.6. Внес ряд полезных изменений. Проблема, которую осталось решить, как ни странно, связана с Вистой :)
Кажется, микрософты сделали так, что GDI в Висте эмулируется через DirectX (я не специалист в этом вопросе, точно утверждать не берусь).
Версию 3.6 я задумал как переходную — в ней я хотел разобраться с графикой, а переписывание алгоритма расчета оставить для следующих версий. Мой приятель, просивший не упоминать его имя, помог с OpenGL. Теперь некритичная к быстродействию часть кода выводит графику через Canvas, а критичная — через OpenGL.
В ходе тестирования выяснилось, что в Висте есть еще одна проблема, которая связана, вероятно, с тем, что Виста запоминает содержимое PaintBox'а. Виста считает себя умнее всех остальных систем, в которых посылается сообщение wmpaint, и без спроса восстанавливает то, что было PaintBox'е, хотя оно уже перезаписано более свежей картинкой.
Логично предположить, что всё дело в Делфи 7. Она вообще не подозревает о существовании Висты :) Вполне возможно, что подобные ошибки уже исправлены в последней версии Делфи. Не долго думая, установил Делфи 2009. После небольших изменений кода программа скомпилировалась, но заработать отказалась
Делфи 2009 —
К счастью, после удаления Делфи 2009 проблема с ошибкой «List capacity out of bounds (%d)» исчезла. Баг, связанный с обновлением PaintBox'а, исправлю
Да, и еще. Вот объясните мне, как можно пользоваться последними версиями программных продуктов и технологий, если они настолько кривые?
Добавлено: Обычно я не склонен к поспешным выводам, однако Делфи 2009 произвела на меня совсем уж удручающее впечатление :) По всей видимости, проблема с ошибкой при старте программы не связана с Делфи 2009. И, может быть, в ней можно заставить PNG работать нормально. В общем, нужно еще раз ее поставить, чтобы разобраться до конца.
Стиль оформления кода
Как заставить неправильный код выглядеть неправильно. Описывается один из вариантов оформления кода. Даже если вы — опытный программист, статья будет полезна для вас.