Некоторые возможности регулярных выражений, о которых мало кто знает
На примере задачи с поиском определенных последовательностей символов в строке расскажу о некоторых не очень известных возможностях регулярных выражений.
Условие задачи
Нужно найти в строке символы i, b, u, d, перед которыми расположено нечетное количество обратных слешей, например \I или \\\b.
Мотивация
Расскажу, откуда появилась эта задача. В свой поисковый движок Rose я добавил поддержку простейшего форматирования в сниппетах: курсив, жирный шрифт, верхние и нижние индексы. Благодаря этому формула
Я не хотел хранить текст сниппетов с частично вырезанными \i включает курсивное начертание, последовательность \I отключает. Аналогично с остальным форматированием. При этом, чтобы хранить сам символ обратного слеша, его нужно продублировать для экранировки (\\). Таким образом, формула из примера выше хранится в сниппетах как \iy\I = e\u\ix\I\U.
Как видно на скриншоте выше, сниппеты собираются из отдельных предложений, а форматирование может распространяться за их границы. Например, я могу выделить курсивом целый абзац, тогда \i будет в начале первого предложения, а \I — в конце последнего. Поэтому важно после разбиения текста на предложения убедиться, что всё открытое форматирование корректно завершено в текущем предложении и перенесено на следующее, и нет завершения неоткрытого форматирования. Для этого как раз и нужна сформулированная задача.
Решение
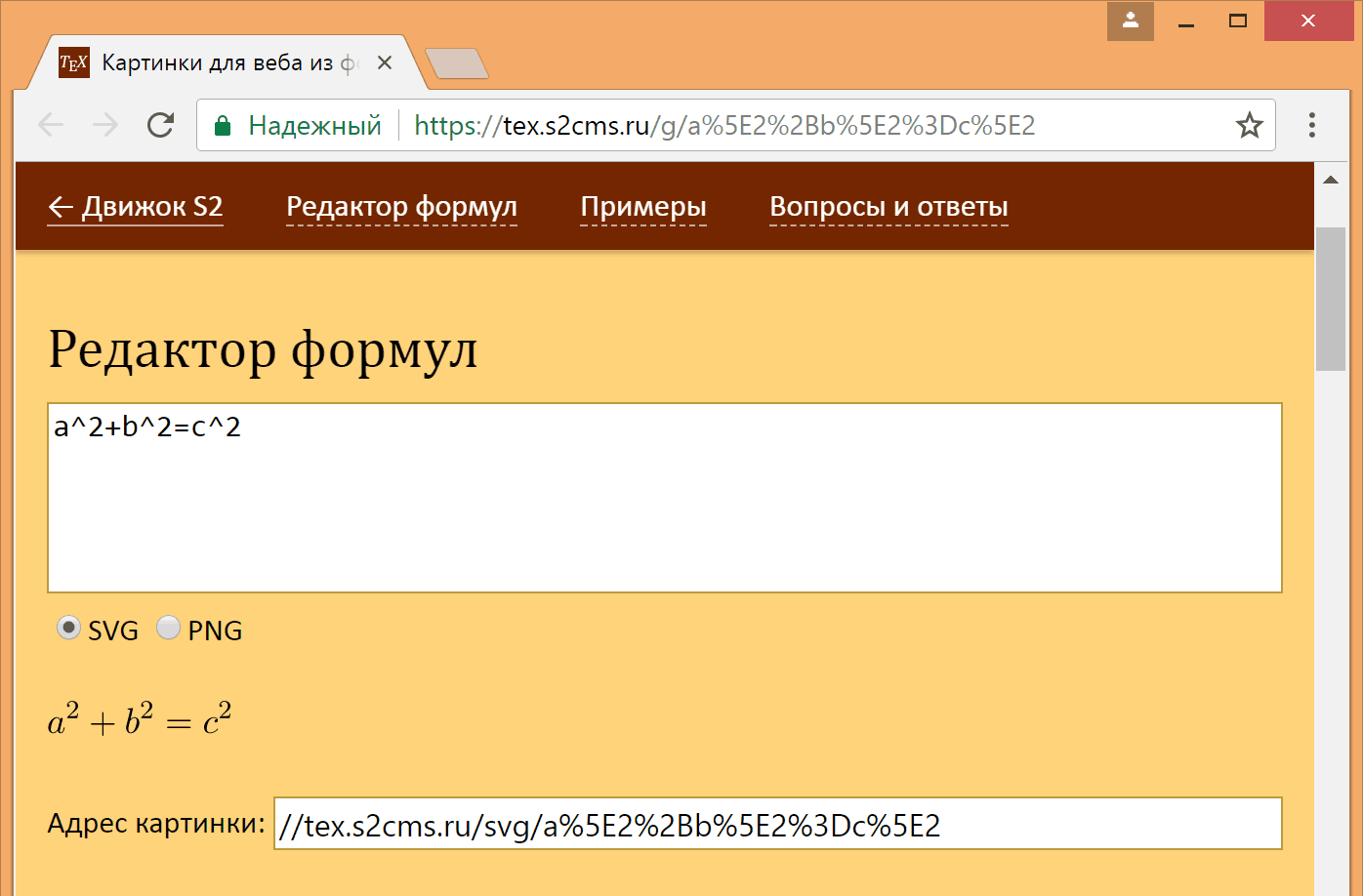
Я составил такую регулярку: #\\(?:\\(*SKIP)\\)*\K[ibud]#i. Давайте разберем ее по шагам.
- Регулярка начинается с символа обратного слеша. Нужно помнить, что в регулярных выражениях он имеет специальное значение, и сам по себе должен быть экранирован.
- Дальше идет группа
(?:...)без захвата, то есть ее содержимое не попадает в итоговый массив результатов$matches. - Внутри группы находятся два обратных слеша, а сама группа указана с
квантификатором , означающим её повторение любого количества раз, включая нулевое. Таким образом уже разобранная часть регулярки должна срабатывать на нечетном количестве слешей.* - Внутри группы также расположена управляющая последовательность бэктрекинга
(*SKIP). Она обозначает некоторую границу и дает инструкции движку регулярных выражений, чтобы он не переходил эту границу при переборе возможных повторений, задаваемыхквантификатором , а также сразу переходил к ней в исходной строке, если было только частичное совпадение с регуляркой. Без этой управляющей последовательности мы бы получили ложное совпадение на строке*\\iс четным количеством слешей. Действительно, в ней на первом проходе, начиная с первого символа\\i, совпадения нетиз-за четного количества слешей. Но дальше мы получим совпадение, начиная со второго символа:\\i.(*SKIP)же задает границу между вторым слешем и следующим символом, поэтому движок регулярок при работе не будет проверять совпадение со второго символа, а сразу перейдет к третьему. В англоязычной литературе для подобных управляющих последовательностей используется термин Backtracking Control Verbs, среди них есть и другие полезные возможности. - Следующей идет последовательность
\K. Она убирает из результатов общего совпадения всё, что было до нее. Таким образом, в$matches[0]попадет только оставшаяся часть совпадения, без слешей. - Наконец, мы требуем, чтобы после нечетного количества слешей был один из управляющих символов
[ibud]. Так как у регулярки указан модификаторi, совпадение будет в любом регистре.
Если не использовать жемчужину этой регулярки, (*SKIP), можно сочинить выражение с ретроспективной проверкой (lookbehind): #(?<=^|[^\\])\\(?:\\\\)*\K[ibud]#i. Правда, оно будет менее эффективно на строках с обратным слешем. Ну а наивное выражение #(?:^|[^\\])\\(?:\\\\)*\K[ibud]#i будет медленнее на любых строках, так как не начинается с фиксированного символа обратного слеша.
При применении регулярных выражений не нужно забывать о дополнительном экранировании слешей по требованиям синтаксиса языка программирования. Итоговый код на PHP получается таким:
preg_match_all('#\\\\(?:\\\\(*SKIP)\\\\)*\K[ibud]#i', $text, $matches);
foreach ($matches[0] as $match) {
// в $match будет один из символов ibudIBUD
}

Оставьте свой комментарий