Codeium — нейросетевой помощник программиста
Попробовал в работе Codeium — нейросетевой помощник в написании кода. Его обзор уже был на хабре, так что я просто запишу свои наблюдения, не претендуя на полноту рассмотрения.
Как работает Codeium
Я установил его как плагин к PhpStorm. Для работы он требует войти в аккаунт, но регистрация бесплатна.
Пользователь взаимодействует с плагином двумя способами. Первый — автодополнение. Вы набираете код, останавливаетесь, и в этот момент нейросеть выдает возможное продолжение. Вот я написал название метода, остановился в начале пустого тела, и Codeium вывел серым предполагаемое начало кода:
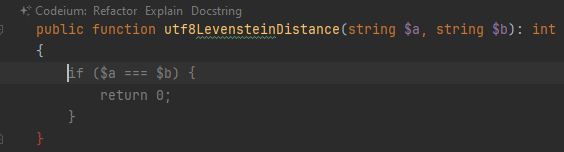
После нажатия на tab и перевода строки нейросеть продолжает сочинять. Вот тут одним махом предлагает написать весь оставшийся код метода:
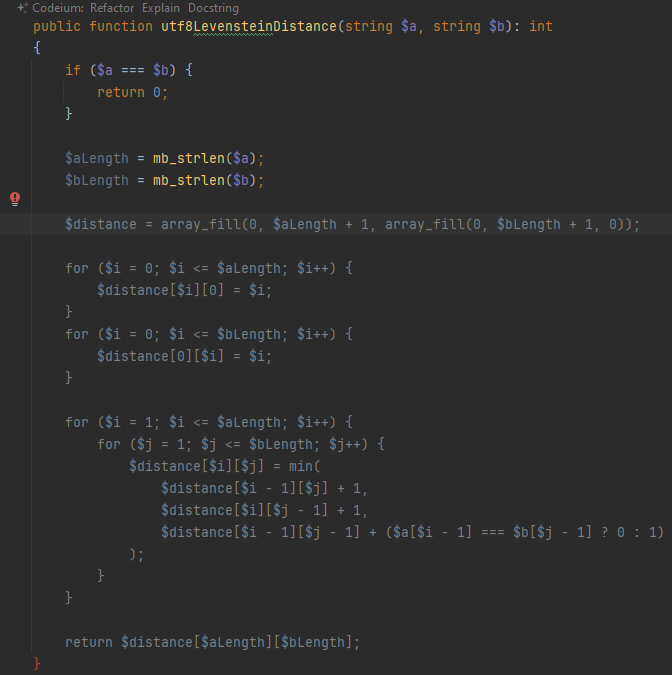
Нейросеть «поняла» из названия метода, что мне нужна версия алгоритма для вычисления расстояния Левенштейна между строками, корректно работающая с кодировкой levenshtein(), но она правильно работает только для однобайтных кодировок). Идея алгоритма оказалась правильной, но с деталями не вышло: сравнение $a[$i - 1] === $b[$j - 1] берет не символы с соответствующими номерами, а байты. После исправления этого фрагмента на mb_substr($a, $i - 1, 1) === mb_substr($b, $j - 1, 1) код заработал правильно.
Второй способ взаимодействия — это чат. Он мне показался туповатым по сравнению с ChatGPT. Я так и не понял, лучше ли работают английские запросы, или можно писать
Главный вау-эффект
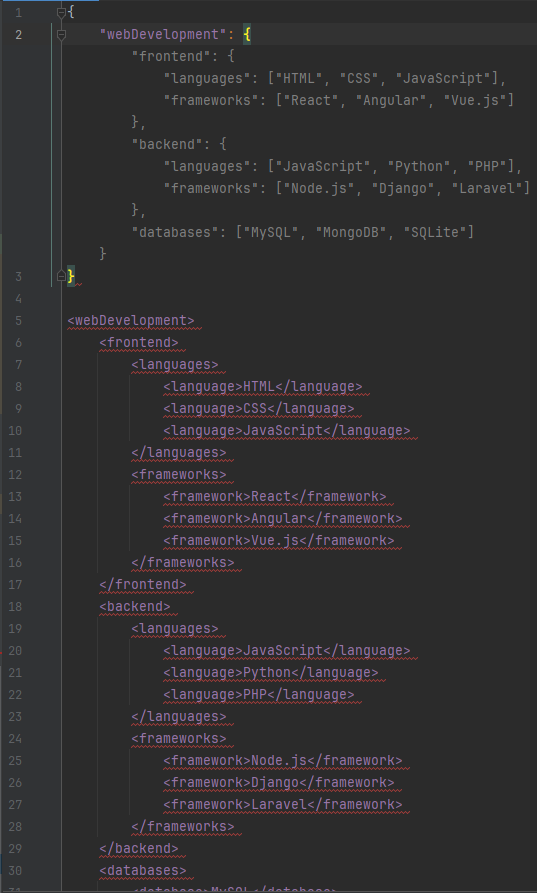
Наибольшая помощь от «искусственного интеллекта» была в переписывании кода и конфигурации из одного формата в другой. Допустим, вы меняете формат
Недостатки
Теперь о недостатках, куда же без них.
Ненативность автодополнения проявляется еще, например, при переименовании. Вот здесь я переименовываю метод так, что PhpStorm заменит его вызовы по всему проекту. На этот режим указывает голубая рамка. Codeium умудряется дописать свое мнение еще и сюда, но сам PhpStorm о нем ничего не знает. Когда я применил подсказку пару недель назад и закончил переименовывать, PhpStorm заменил вызовы по всему проекту на недополненное несуществующее название. Сейчас при попытке воспроизведения tab в режиме переименования просто не работает, подсказка не применяется. То есть Codeium выдает свой вариант, но применить его никак нельзя.
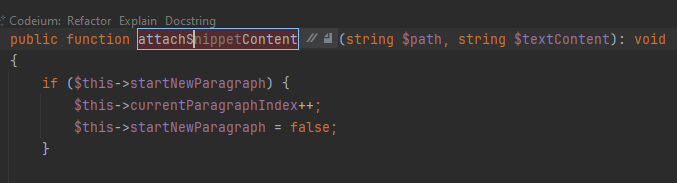
По внешнему виду автодополнения непонятно, что это предложение помощника. Просто серый текст, неотличимый от комментария. В
Еще одна особенность текущего механизма взаимодействия: нет возможности оставить часть предложенного автодополнения, скажем, первые несколько слов. Можно только принять всё целиком и удалить лишнее.
Вывод
В процессе работы перевешивают то достоинства нейросетевого помощника, то его недостатки. Забавно наблюдать, как нейросеть «читает» твои мысли, выдавая ровно тот код, который ты сам собрался написать. Правда, происходит такое не всегда. Когда нейросеть предлагает нужные фрагменты кода, их надо тщательно проверить, как за
В общем, перспективы большие. Пользовательский опыт сейчас страдает. Пробуйте сами.
Да, и не забывайте о вопросах безопасности. Наверняка Codeium отправляет всё редактируемое на свои серверы. Я пробовал его на открытом опубликованном коде своего движка, так что дополнительно ничего «утечь» не может. Если хотите попробовать на работе — проконсультируйтесь с вашим отделом по информационной безопасности.
Некоторые возможности регулярных выражений, о которых мало кто знает
На примере задачи с поиском определенных последовательностей символов в строке расскажу о некоторых не очень известных возможностях регулярных выражений.
Условие задачи
Нужно найти в строке символы i, b, u, d, перед которыми расположено нечетное количество обратных слешей, например \I или \\\b.
Мотивация
Расскажу, откуда появилась эта задача. В свой поисковый движок Rose я добавил поддержку простейшего форматирования в сниппетах: курсив, жирный шрифт, верхние и нижние индексы. Благодаря этому формула
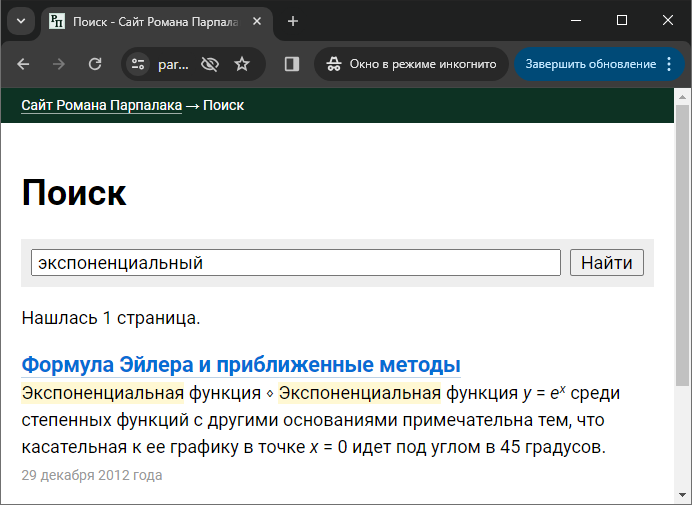
Я не хотел хранить текст сниппетов с частично вырезанными \i включает курсивное начертание, последовательность \I отключает. Аналогично с остальным форматированием. При этом, чтобы хранить сам символ обратного слеша, его нужно продублировать для экранировки (\\). Таким образом, формула из примера выше хранится в сниппетах как \iy\I = e\u\ix\I\U.
Как видно на скриншоте выше, сниппеты собираются из отдельных предложений, а форматирование может распространяться за их границы. Например, я могу выделить курсивом целый абзац, тогда \i будет в начале первого предложения, а \I — в конце последнего. Поэтому важно после разбиения текста на предложения убедиться, что всё открытое форматирование корректно завершено в текущем предложении и перенесено на следующее, и нет завершения неоткрытого форматирования. Для этого как раз и нужна сформулированная задача.
Решение
Я составил такую регулярку: #\\(?:\\(*SKIP)\\)*\K[ibud]#i. Давайте разберем ее по шагам.
- Регулярка начинается с символа обратного слеша. Нужно помнить, что в регулярных выражениях он имеет специальное значение, и сам по себе должен быть экранирован.
- Дальше идет группа
(?:...)без захвата, то есть ее содержимое не попадает в итоговый массив результатов$matches. - Внутри группы находятся два обратных слеша, а сама группа указана с
квантификатором , означающим её повторение любого количества раз, включая нулевое. Таким образом уже разобранная часть регулярки должна срабатывать на нечетном количестве слешей.* - Внутри группы также расположена управляющая последовательность бэктрекинга
(*SKIP). Она обозначает некоторую границу и дает инструкции движку регулярных выражений, чтобы он не переходил эту границу при переборе возможных повторений, задаваемыхквантификатором , а также сразу переходил к ней в исходной строке, если было только частичное совпадение с регуляркой. Без этой управляющей последовательности мы бы получили ложное совпадение на строке*\\iс четным количеством слешей. Действительно, в ней на первом проходе, начиная с первого символа\\i, совпадения нетиз-за четного количества слешей. Но дальше мы получим совпадение, начиная со второго символа:\\i.(*SKIP)же задает границу между вторым слешем и следующим символом, поэтому движок регулярок при работе не будет проверять совпадение со второго символа, а сразу перейдет к третьему. В англоязычной литературе для подобных управляющих последовательностей используется термин Backtracking Control Verbs, среди них есть и другие полезные возможности. - Следующей идет последовательность
\K. Она убирает из результатов общего совпадения всё, что было до нее. Таким образом, в$matches[0]попадет только оставшаяся часть совпадения, без слешей. - Наконец, мы требуем, чтобы после нечетного количества слешей был один из управляющих символов
[ibud]. Так как у регулярки указан модификаторi, совпадение будет в любом регистре.
Если не использовать жемчужину этой регулярки, (*SKIP), можно сочинить выражение с ретроспективной проверкой (lookbehind): #(?<=^|[^\\])\\(?:\\\\)*\K[ibud]#i. Правда, оно будет менее эффективно на строках с обратным слешем. Ну а наивное выражение #(?:^|[^\\])\\(?:\\\\)*\K[ibud]#i будет медленнее на любых строках, так как не начинается с фиксированного символа обратного слеша.
При применении регулярных выражений не нужно забывать о дополнительном экранировании слешей по требованиям синтаксиса языка программирования. Итоговый код на PHP получается таким:
preg_match_all('#\\\\(?:\\\\(*SKIP)\\\\)*\K[ibud]#i', $text, $matches);
foreach ($matches[0] as $match) {
// в $match будет один из символов ibudIBUD
}