Мастер костылей, или сущности в DOMDocument
Я тут решил потратить некоторое время на собственные проекты. Сейчас перерабатываю движок для поиска Rose. На нем работает поиск на этом сайте, также его использует Илья Бирман в Эгее.
Для извлечения текста из
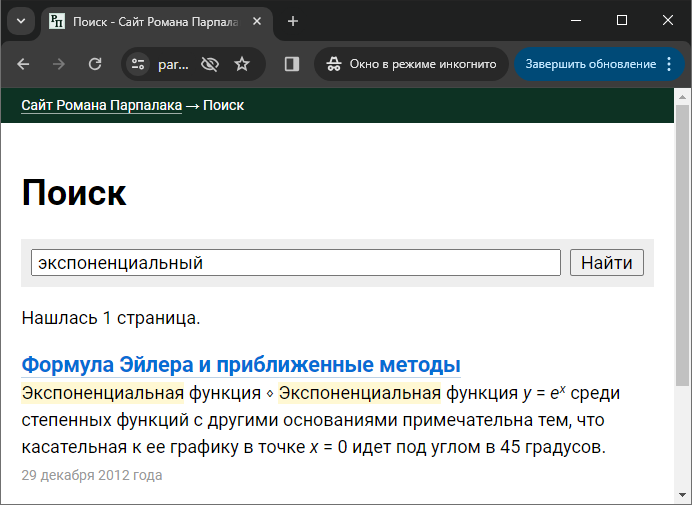
Как оказалось, DOM API не поддерживает HTML5. Это выливается в практическую проблему с непоследовательной обработкой сущностей HTML. Например, если в исходнике написать & ★, при получении текстового содержимого из & ★. Видим, что первая сущность из HTML предыдущих версий распознается и раскодируется, а вторая из HTML5 — нет. Такие ошибки приведут к искажениям при выводе сниппетов.
Моя первая идея — прогнать текстовое содержимое через html_entity_decode($a, ENT_HTML5);. Действительно, что не доделал встроенный парсер, доделает эта функция. Но проблема в том, что раскодирование неидемпотентно. Если на вход подать ★, то после DOM API мы получим ★. И на этапе повторного раскодирования мы не будем знать, нужно ли раскодировать ★ еще раз, или нет.
Поиск проблемы в гугле разумного решения не выявил. В классе DOMDocument есть
Для начала нужно все вхождения амперсанда заменить на его сущность:
$text = str_replace('&', '&', $text);После этого DOM API раскодирует копии только одой сущности — этого самого амперсанда. При рекурсивном обходе в текстовом содержимом узлов html_entity_decode($a, ENT_HTML5);.
Уже который раз убеждаюсь, что искусство программиста во многом заключается в умении подобрать нужный костыль. Так и живем.
Комментарии
Моя задача — разбить HTML сначала по блочным элементам на абзацы, потом по знакам препинания на предложения. Попутно другие элементы обработать. Я для этого обхожу
Бегло просмотрел документацию и пока не понял, как tidy может помочь. Может есть
Буду иметь в виду, что есть tidy. Пока у меня всё работает через DOMDocument и libxml даже на HTML с ошибками. На стековерфлоу по ссылке так и пишут: «DOM is capable of parsing and modifying real world (broken) HTML» ()
Кстати, надо будет добавить в
Оставьте свой комментарий