S2
S2 — это быстрый бесплатный движок сайта, написанный мной на PHP и выпущенный под лицензией GNU GPL.
Подключил Akismet для борьбы со спамом
Со временем технологии развивались, и через selenium разработчики автоматизировали действия ботов через полноценные браузеры. Метод защиты с помощью Javascript стал фильтровать только самых тупых ботов.
Затем для борьбы со спамом я включил предарительную проверку комментариев перед публикацией. К этому времени поток комментариев на сайте как раз уменьшился. Немногочисленные нормальные комментарии легко одобрить вручную, особенно когда отвечаешь на них. Тогда же я запрограммировал обход предварительной проверки для залогиненных модераторов — пользователей, которые управляют отображением комментариев.
Чтобы облегчить себе жизнь по окончательному удалению спаммерских комментариев из очереди на модерацию, я задумался над тем, какова цель спаммеров? Конечная цель — разместить ссылки для манипуляции индексом цитирования и для привлечения посетителей. Если запретить оставлять ссылки, спаммерам не будет смысла оставлять комментарии без них. А если ссылку хочет разместить человек в хорошем комментарии, сайт скажет ему, чтобы он удалил http:// из ссылки. Запрет на ссылки принес свои плоды, но
Сейчас я решил посмотреть, как привлечь новые технологии для фильтрации спама. Теоретически можно натренировать нейросеть на
Akismet — это система фильтрации спама в комментариях, разработанная авторами WordPress. В вордпрессе есть плагин, который обращается к API Akismet. Однако сам API открыт и может быть использован любым сайтом, для обращения нужен только лицензионный ключ. Лизензия для некоммерческого использования бесплатная.
Основная особенность Akismet заключается в том, что он используется на множестве сайтов. Таким образом можно быстро выявлять новые
Я подключил сервис и несколько дней его тестировал. По каждому комментарию Akismet возвращает свое решение: либо это хороший комментарий, либо спам, либо «вопиющий» (blatant) спам. В итоге остановился на следующем алгоритме фильтрации комментариев:
- если комментарий хороший, он публикуется сразу;
- если комментарий признан вопиющим спамом, он даже не сохраняется, при попытке его отправить будет возвращено сообщение об ошибке;
- если комментарий спаммерский, он остается скрытым, а уведомление о нем отправляется модераторам;
- если владелец сайта не указал в настройке лицензионный ключ Akismet или если сервис не ответил, комментарий либо публикуется либо остается скрытым в зависимости от того, включен ли режим модерации (откат к старому алгоритму).
После внедрения за две недели пришло 62 комментария. Из них 60 спаммерских комментариев были отсеяны либо как вопиющий спам (21 комментарий), либо как спам с наличием ссылок в тексте. Остальные два комментария опубликованы: один хороший комментарий и один спаммерский со ссылкой на yotube.

Понятно, что у способа есть свои недостатки.
Мысли о движке сайтов S2
В этом году я сделал несколько доработок своего движка сайтов S2, главная и самая заметная из которых — система рекомендаций. Я бы не стал об этом опять писать, если бы не одно но — до этого крупные доработки в движке я делал больше 8 лет назад. В этой заметке я хочу зафиксировать, как так получилось и что теперь с этим делать.
История
Историю движка можно проследить по тегу «S2». Главная проблема движка в том, что он был полем для моих экспериментов в процессе изучения
С другой стороны, в движке были и удачные находки. Например, шаблон страницы обрабатывается не только после подготовки данных, когда они подставляются в этот самый шаблон, но и до того, чтобы определить, какие именно данные нужны шаблону. Это позволяет гибко управлять функциональностью и не нагружать сервер лишней работой, если она не требуется для отображения текущей страницы. Такую оптимизацию я не встречал в других системах.
В
Со второй частью намерений не сложилось. Были желающие помочь развитию движка, но других активных разработчиков у движка так и не появилось.
Со временем я приобрел достаточный опыт в разработке и стал понимать, насколько тяжело дописывать новый код движка в старой парадигме. Я несколько раз пытался переписывать код с нуля. Сначала без фреймворков с «нормальным» объектным подходом (версия 2.0dev). Потом на микрофеймворке Silex. Потом авторы Silex отказались от его развития, и я подключил Symfony. Все эти попытки сделать версию 3.0 останавливались на том, что надо переделать на новую схему админку и расширения, и для такой объемной работы у меня не было времени и желания.
Одновременно с этим активность на форуме угасла. Авторы некоторых сайтов перенесли их на другие движки. Некоторых сайтов больше нет. Некоторые заброшенные сайты до сих пор работают на S2.
В итоге сейчас у движка больше нет пользователей, на которых надо ориентироваться.
Доработка
Недавно я решил просмотреть все заметки в блоге, удалить устаревшие заметки, актуализировать теги. На удивление некоторые заметки перечитал с удовольствием. Этот процесс вдохновил меня на то, чтобы залезть в код движка и посмотреть, что можно с ним сделать.
У меня получилось за 1 января (обычно бесполезный день) подключить к S2 версии 2.0dev свежую версию поискового движка Rose, и при этом сделать так, чтобы в общем кодовом пространстве движка сосуществовали устаревший код, на который больно смотреть, и новый код, с которым приятно работать. Такой быстрый прогресс открыл дорогу к тому, чтобы сделать уже упоминавшуюся систему рекомендаций.
Также я внес несколько менее масштабных, но не менее желанных изменений. Перенес
Еще подключил codeception — библиотеку для написания автотестов, и стал добавлять эти автотесты. Среди нескольких видов тестов пришлось выбрать приемочные (acceptance). В них выполняются настоящие
Продуктовый подход
Я как единственный оставшийся пользователь движка подошел к нему и своему сайту как к работающему продукту. Вместо того чтобы пытаться переписать движок с нуля на идеальной архитектуре, потратив непонятное количество времени, я сконцентрировался на том, какие фичи могу добавить прямо сейчас. Практика показала, что многое можно сделать в текущей версии, не переписывая ее код с нуля.
Альтернатива — забросить S2 и перейти на другой движок, хотя бы ту же Эгею Ильи Бирмана. Но для этого надо создать свою тему оформления, написать и отладить конвертер заметок, разобраться со старыми адресами URL, пройтись по всем заметкам и убедиться, что ни в одной ничего не сломалось (а ломаться есть чему: у меня есть заметки с нетривиальной версткой вроде рецензии на книгу о фильме «Интерстеллар»). Это значительный объем работы, которую нельзя делать понемногу, мелкими шагами. Мне проще было постепенно доработать свой движок.
Светлое будущее
S2 переехал на гитхаб, откуда его можно скачать. Версию 1.0 я пока что использую, поэтому еще некоторое время буду исправлять баги и проблемы совместимости со свежими версиями PHP. Новых фич в ней не будет. С версии 1.0 можно обновиться до 2.0dev, переработав стили.
Версию 2.0dev буду иногда дорабатывать на досуге. Не планирую свои сайты переводить с неё на
На вопросы возможных пользователей движка я отвечать не планирую. Я не вижу перспектив в том, чтобы у движка появлялись новые пользователи. Сейчас соцсети, облачные платформы и конструкторы сайтов не оставляют движкам типа S2
Как разработать систему рекомендаций ★
Продолжим разговор о системе рекомендаций в S2. Эта система подбирает к каждой заметке набор других заметок, которые посетитель может почитать дальше. В прошлый раз я рассказал об этой системе в целом, сейчас же опишу алгоритм подбора самих рекомендаций.
За рекомендации в моем случае отвечает движок полнотекстового поиска Rose. Структура данных в полнотекстовом индексе как раз подходит для задачи подбора похожих заметок. Если совсем упростить, то получается, что обычный поиск — это подбор подходящих заметок к словам из поискового запроса, а рекомендации к заметке — это подбор других заметок по словам из нее. А теперь давайте погрузимся в детали.
Теория рекомендаций
Для начала давайте поймем, как вообще могут работать системы рекомендаций. Рассуждать будем на примере существовавшего
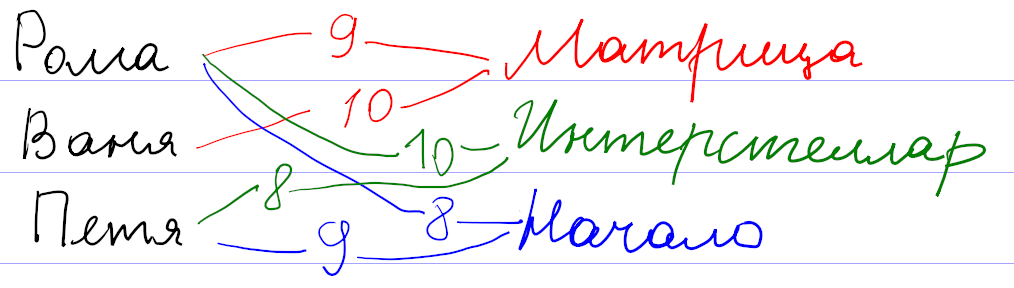
Оценки пользователей сохраняются как веса связи
Математика позволяет предложить более формальный и универсальный подход. Будем рассматривать оценки к фильмам как координаты некоторой точки во многомерном пространстве всех фильмов. Тогда всех пользователей можно представить как множество точек в таком пространстве. При достаточном количестве они начнут группироваться в кластеры по разным предпочтениям. После этого задача подбора рекомендаций сведется к поиску соответствующего кластера.
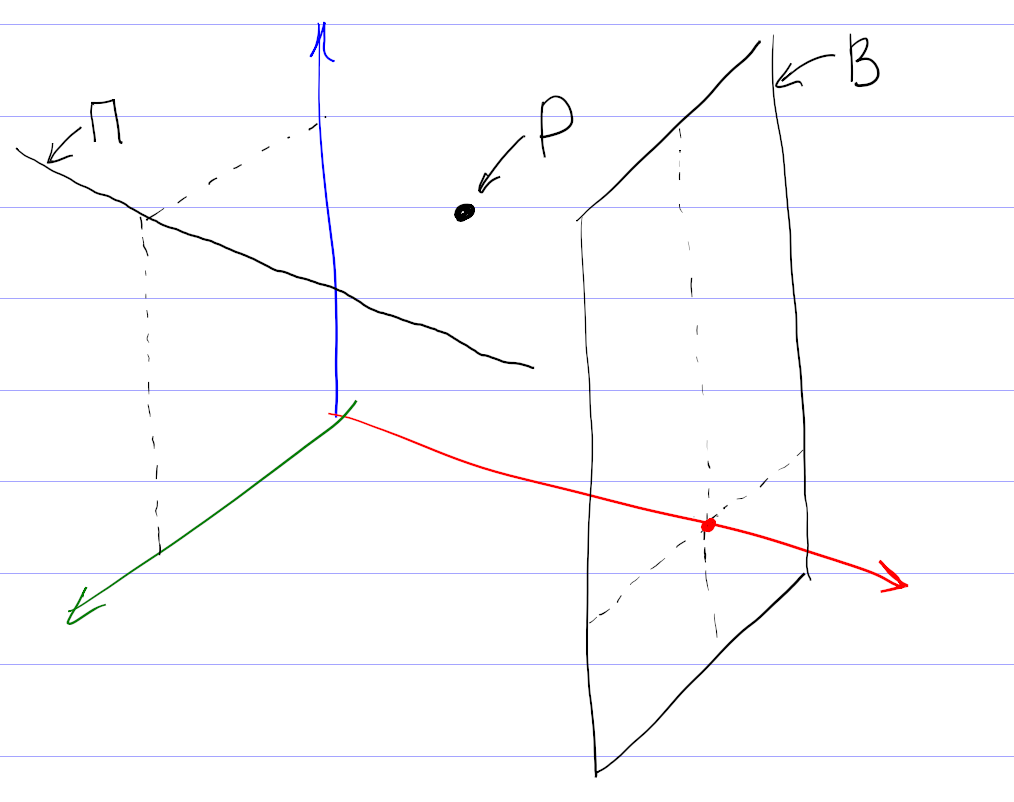
На самом деле, картина сложнее, так как никто не может поставить оценки всем фильмам. Поэтому вместо точек мы имеем дело с некоторыми подпространствами (прямыми, плоскостями и т. д.). Чтобы сформировать мои рекомендации, система проецирует все оценки на подпространство просмотренных мной фильмов, находит кластер в проекции, и по нему уже пытается восстановить кластер в полном пространстве.
Понятно, что процедура восстановления кластера из проекции неоднозначна, и в этом месте система рекомендаций может ошибаться, даже если в ней собраны оценки большого количества пользователей. Например, по оценкам фильмов, единогласно оцениваемых зрителями, нельзя восстановить предполагаемую оценку и однозначно рекомендовать фильм, мнения по которому разделились на два равновеликих полюса.
Эта теория прекрасно выглядит на листе бумаги. Но я уверен, что при практической реализации разработчики столкнулись с кучей проблем. Очевидная проблема — нормировка оценок. Например, у меня средняя оценка была около 7. Оценки меньше 4 я практически не ставил. Задумывался над тем, чем отличается оценка 9 от 10. Оценки других пользователей наверняка отличались по характеристикам.
Вы наверняка встречались с другим примером системы рекомендаций: поиском друзей в соцсетях. Здесь тоже работает связь
Теперь давайте посмотрим, как можно эти знания применить для подбора рекомендаций заметок.
Рекомендации на основе тегов
Как видно из предыдущего рассмотрения, систему рекомендаций можно сделать везде, где есть связь
Недостатки подхода лежат на поверхности.
Рекомендации на основе похожих текстов
В движке S2 есть другая связь
| word_id | toc_id | positions |
|---|---|---|
| 1 | 1 | 0,37 |
| 3 | 4 | 0,15,74,193,614 |
| 3 | 8 | 94 |
| 3 | 9 | 73 |
| 4 | 1 | 3,16,57 |
| … |
В первой колонке хранится id «слова», во второй — внутренний id проиндексированного элемента (ToC — это сокращение от table of contents), в третьей — положения соответствующего слова в проиндексированном тексте.
При индексации исходный текст заметок очищается от
При поиске запрос преобразуется по такой же схеме: слова заменяются на идентификаторы word_id, и из поискового индекса мы получаем информацию о том, в каких проиндексированных текстах (toc_id) встречались эти слова. Положения слов (positions) нужны для вычисления релевантности: чем ближе слова из запроса друг к другу в тексте, тем выше окажется этот текст в выдаче.
Рекомендации на основе близости текста тоже используют эту таблицу. У меня получилось уместить все существенные вычисления в один
SELECT
relevance_info.*, -- информация из подзапроса
m.images, -- добавляем к ней информацию о картинках
t.*, -- добавляем к ней оглавление
-- и первые 2 предложения из текста
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1) AS snippet,
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1 OFFSET 1) AS snippet2
FROM (
SELECT -- Перебираем все возможные заметки и вычисляем релевантность каждой для подбора рекомендаций
i.toc_id,
round(sum(
original_repeat + -- доп. 1 за каждый повтор слова в оригинальной заметке
exp( - abn/30.0 ) -- понижение веса у распространенных слов
* (1 + length(positions) - length(replace(positions, ',', ''))) -- повышение при повторе в рекомендуемой заметке, конструкция тождественна count(explode(',', positions))
) * pow(m.word_count, -0.5), 3) AS relevance, -- тут нормировка на корень из размера рекомендуемой заметки. Не знаю, почему именно корень, но так работает хорошо.
m.word_count
FROM fulltext_index AS i
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) ON m.toc_id = i.toc_id
JOIN (
SELECT -- достаем информацию по словам из оригинальной заметки
word_id,
toc_id,
(SELECT count(*) FROM fulltext_index WHERE word_id = x.word_id) AS abn, -- распространенность текущего слова по всем заметкам
length(positions) - length(replace(positions, ',', '')) AS original_repeat -- сколько раз слово повторяется в оригинальной заметке. Выше используется как доп. важность
FROM fulltext_index AS x FORCE INDEX FOR JOIN(toc_id)
JOIN toc AS t ON t.id = x.toc_id
WHERE t.external_id = :external_id AND t.instance_id = :instance_id
AND length(positions) - length(replace(positions, ',', '')) < 200 -- отсекаем слишком частые слова. Хотя 200 слишком завышенный порог, чтобы на что-то влиять
HAVING abn < 100 -- если слово встречается более чем в 100 заметках, выкидываем его, так как слишком частое. Помогает с производительностью
) AS original_info ON original_info.word_id = i.word_id AND original_info.toc_id <> i.toc_id
GROUP BY 1
HAVING count(*) >= :min_word_count -- количество общих слов, иначе отбрасываем
) AS relevance_info
JOIN toc AS t FORCE INDEX FOR JOIN(PRIMARY) on t.id = relevance_info.toc_id
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) on m.toc_id = t.id
ORDER BY relevance DESC
LIMIT :limitОпишу ключевые шаги, которые здесь выполняются.
1. Взять все слова в заметке, к которой подбираем рекомендации. Я называю эту заметку оригинальной. Выбор слов происходит в самом внутреннем подзапросе.
2. Выкинуть распространенные слова. Это нужно делать для повышения точности и при поиске, и при подборе рекомендаций. Можно даже составить список игнорируемых слов вроде союзов или предлогов. Но вместо составления такого неизменяемого списка я вычисляю распространенность (abundance, сокращенно abn — количество заметок, в которых встречается это слово) для каждого слова в индексе. Например, в блоге о дизайне в каждой заметке будет слово «дизайн», и его тоже надо игнорировать.
Слова с распространенностью больше 100 наверняка окажутся слишком общими, и я отбрасываю их по соображениям производительности. Скорее всего порог должен
3. Найти одинаковые слова у оригинальной заметки с остальными заметками. Это происходит в промежуточном подзапросе. У заметок при этом должно быть достаточное количество общих слов (порог определяется параметром min_word_count).
Я пробовал разные значения параметра. Если увеличивать, количество рекомендаций падает. Если уменьшать, в рекомендации попадают не очень подходящие заметки за счет случайного использования общих слов. Я остановился на варианте, когда запрос сначала выполняется со значением 4. Если результатов нет, как это часто бывает у коротких заметок, то запрос повторяется со значением параметра 2.
4. По повторяющимся словам вычислить релевантность. Это тоже происходит в промежуточном подзапросе в выражении в селекте благодаря group by. Релевантность я вычисляю как количество повторений общих слов. Чтобы понизить влияние распространенных слов, я добавил ослабление за счет веса exp(-abn/30.0). Хотел было использовать колоколообразную функцию типа exp(-sqr(abn/30.0)), но на практике линейное уменьшение веса при малых значениях распространенности повысило качество рекомендаций.
Кроме того, повторы в оригинальной заметке (original_repeat) и в рекомендуемых заметках влияют на релевантность несимметрично: повторяющиеся слова в оригинальной заметке не ослабляются, даже если они распространены. Объяснение можно предложить такое: если автор пишет одинаково часто о шахматах и шашках, то к оригинальной заметке с пятью словами «шахматы» и одним словом «шашки» лучше рекомендовать заметку с одним словом «шахматы», чем с пятью словами «шашки». Эффект несимметричности я не закладывал специально. Практика показала, что отсутствие ослабления у original_repeat субъективно улучшает качество рекомендаций.
Несимметричность веса оригинальной заметки и рекомендуемых может быть даже полезной, чтобы избежать «зацикливания» рекомендаций, когда к заметке А мы рекомендуем заметку Б, а к заметке Б — заметку А. Правда, у меня этот критерий не был обязательным, и я не проверял, как он выполняется. Применительно к моему сайту эффект зацикливания может ослабляться ещё и за счет последующего предпочтения в рекомендациях заметок с картинками.
Последний множитель в релевантности pow(m.word_count, -0.5) учитывает размер рекомендуемой заметки в словах. Без него в моем случае среди рекомендуемых оказывались очень длинные заметки, набиравшие релевантность за счет большого количества повторяющихся слов средней распространенности. Тогда я подумал, что сортировать рекомендации нужно не по абсолютному количеству общих слов, а по относительному, то есть надо поделить вычисленную релевантность на количество слов в рекомендуемой заметке. В рекомендации стали попадать короткие заметки всего из нескольких слов, а у нормальных заметок из нескольких сотен слов релевантность сильно просела. Чтобы было ни нашим ни вашим, я попробовал поделить абсолютную релевантность на корень из длины рекомендуемой заметки, и это сработало: с первых мест рекомендаций ушли как очень короткие, так и очень длинные заметки. Изменение показателя степени −0,5 в обе стороны приводило к некоторому повышению ранга одних и понижению ранга других таких нерелевантных заметок.
У меня не было объяснения, почему нормировка релевантности именно на корень из длины оказалась подходящей. Но в момент набора этого текста появилась гипотеза. Нормировка на длину рекомендуемых заметок не учитывает длину оригинальной заметки. Но для подбора рекомендаций к одной оригинальной заметке ее длина ни на что не влияет. Возможно, что для более общей задачи подбора рекомендаций к N оригинальным заметкам релевантность нужно нормировать на среднее геометрическое из длин оригинальной и рекомендуемой заметок. Тогда для одной оригинальной заметки ее длина превратится в несущественный постоянный коэффициент и уйдет за скобки, а длина рекомендуемой заметки как раз окажется в знаменателе под корнем.
5. Получить заголовок, картинки и фрагмент текста. Это неинтересная техническая задача, решаемая во внешней части запроса. Для «сниппетов» — коротких фрагментов текста — я достаю первые два предложения из заметок. Сначала думал выводить те предложения из текста, которые содержат общие слова. Зависимость сниппетов от контекста как раз бы показала, почему рекомендуется именно эта заметка. Но
Вопросы производительности
В запросе вы видите явное указание использовать конкретные индексы. Без них планировщик не использовал часть индексов. Почему он так решал — непонятно. За счет расстановки хинтов я оптимизировал запрос раз в 20 до нескольких десятков миллисекунд. Я последние 6 лет работаю с PostgreSQL, и он даже думать отучил, что в запросы можно добавить хинты. Но тут пришлось.
Производительность в несколько десятков миллисекунд я посчитал достаточной, чтобы выполнять
При работе на настоящем сервере выяснилось, что в режиме невысокой нагрузки база данных может иногда выполнять запрос существенно дольше — несколько сот миллисекунд или даже больше секунды. Вот данные мониторинга по средней длительности запроса:
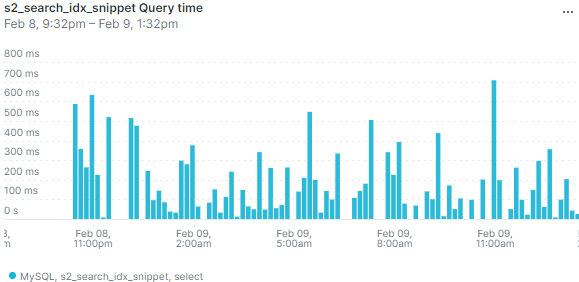
Выбросы на графике означают, что иногда пользователи будут замечать, что страница долго открывается. И изредка приходящий
Я добавил кеширование подбора рекомендаций. Кеш инвалидируется не по времени, а по обновлению заметок. Правда, мне пришлось инвалидировать весь кеш рекомендаций при любом изменении опубликованных заметок. Действительно, изменение хотя бы одного слова в
Кеш хорошо решает проблему с редкими выбросами, даже если заметки часто обновляются. Если в кеше есть устаревшие рекомендации, всё равно выводятся они, а в фоне в это время просчитываются новые рекомендации.
Я так и не понял, почему возникают такие всплески времени выполнения запроса. Не думаю, что конкуренция MySQL за процессорное время с PHP или Похоже, проблема связана с нагрузкой на гипервизор от соседних виртуальных машин.
Направления развития
- Убрать из запроса захардкоженные числа.
- [✓] Если рекомендаций с четырьмя общими словами нет, делать повторный запрос с ослабленным ограничением. А вообще тут важно найти баланс: надо ли показывать неподходящие рекомендации, если нет подходящих?
- Получать сниппеты из релевантных предложений, а не первых двух.
Дополнение о нормальной форме
Внимательный читатель отметил, что таблица полнотекстового индекса не находится даже в первой нормальной форме: в одной ячейке positions через запятую перечислен список положений слова. Что хорошо в теории, не всегда хорошо в настоящем работающем софте. Раньше действительно структура этой таблицы была другой, и каждый элемент из positions располагался на своей строке. Для корректной работы алгоритма мне нужно было обеспечить уникальность строк, поэтому элементы (word_id, toc_id, position) я еще добавил в уникальный индекс.
Достаточно быстро в целях оптимизации я отказался от индекса по word_id и повесил первичный ключ сразу на все колонки (word_id, toc_id, position). В этом есть смысл, так как первичный индекс в InnoDB кластерный, то есть данные строк хранятся на диске вместе с первичным индексом.
Сейчас я пошел в оптимизации дальше и отказался от нормальной формы для хранения положений. Базы данных устроены так, что в таблицах в каждой строке хранится дополнительная служебная информация. Объединение нескольких строк с одинаковыми word_id и toc_id в одну дало экономию места в полтора раза (поисковый индекс в целом уменьшился с 22 до 14 мегабайт при суммарном объеме заметок 2,8 мегабайт). Кроме того, скорость индексации тоже выросла примерно в полтора раза, так как сократилось количество выполняемых запросов. Я не обнаружил
Понятно, что отказ от нормальной формы — не универсальное решение. Так, в рассматриваемом примере пропала возможность фильтрации по полю position. Для задач поиска в этом ничего страшного нет, так как в них фильтрация по position не встречается. Хотя по большому счету мало что изменилось: фильтрацию всё еще можно делать через операции с поиском подстроки, и это не будет сильно медленнее, потому что и раньше по полю position отдельного индекса не было.
Cистема рекомендаций на сайте
Сделал для своего сайта систему рекомендаций. После каждой заметки отображаются аккуратно сверстанные ссылки на похожие материалы. Вот несколько скриншотов, показывающих, как это выглядит.
Пример 1 — антикоррупционный митинг:

Пример 2 — где учиться, на физтехе или физфаке:
Пример 3 — сворачивание кешбека в Бинбанке:
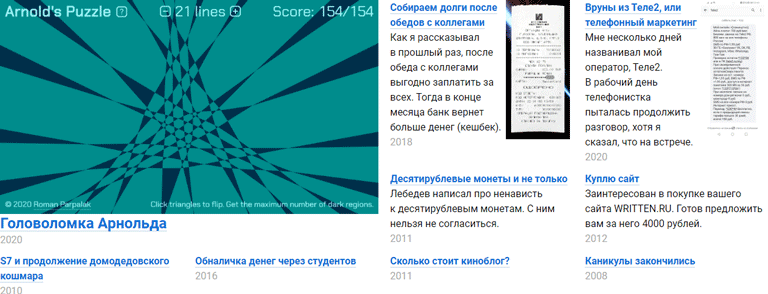
Систему рекомендаций в таком виде сделал Илья Бирман в Эгее — своем движке блогов. В его случае рекомендации к постам формируются на основе тегов. Тогда у меня появилась идея, как можно подбирать рекомендации на основе анализа текстов, без необходимости расставлять теги. Но одно дело — идея, и совсем другое — работающий продукт.
Подбор рекомендаций
Чтобы воплотить идею в жизнь, мне пришлось проделать много подготовительной работы.
Я подключил к моему движку сайтов S2 поисковый движок Rose. s2/search). Но Илья убедил меня, что библиотеке для поиска, как и любому продукту, нужно нормальное имя, и даже предложил несколько вариантов. Название «Ropsen», содержащее первые буквы из Roman Parpalak Search Engine,
Вместе с именем в Розе многое поменялось внутри. Я привел в порядок код, чтобы он следовал правилам хорошего тона для библиотек на PHP: с интерфейсами, инверсией зависимостей и прочими вещами, скрытыми за аббревиатурой SOLID. Кроме того, я сделал реализацию хранилища поискового индекса в MySQL (предыдущая реализация была просто в файле).
Поиск в S2 продолжал работать на старой кодовой базе. Мне казалось, что потребуется много времени, чтобы удалить из
Почему я вообще в заметке о рекомендациях пишу уже четвертый абзац не о рекомендациях, а о поиске? Потому что рекомендации к некоторой заметке на основе ее текста — это, грубо говоря, результаты поиска по словам из этой заметки. Мне удалось написать
Оформление рекомендаций
Чтобы выводить рекомендуемые заметки не просто списком, мне пришлось доработать поисковый движок Rose, чтобы в нем сохранялись предложения из проиндексированных заметок и информация о картинках.
Мне очень понравилось, как выглядят рекомендации у Ильи, и я решил сделать так же. Кроме того, он в своем докладе об автоматическом дизайне рассказал, каким образом работает автоматическая верстка рекомендаций в Эгее. Он подготовил список хорошо сверстанных вариантов и перевел их в некоторый декларативный конфиг с описанием критериев соответствия для каждого элемента верстки (вроде размера и пропорций картинок, длины заголовка и прочего). Дальше для набора рекомендуемых заметок подбирается наиболее подходящий вариант верстки. Обязательно посмотрите видео по ссылке о том, как это всё придумано и работает.
После повторного просмотра видео доклада, которое можно считать подробным и понятным техзаданием, я понял, что не смогу придумать
Тем не менее, я сделал свой декларативный язык. Описал несколько очевидных вариантов верстки, например для пяти рекомендаций: одна крупная рекомендация слева и четыре поменьше справа.
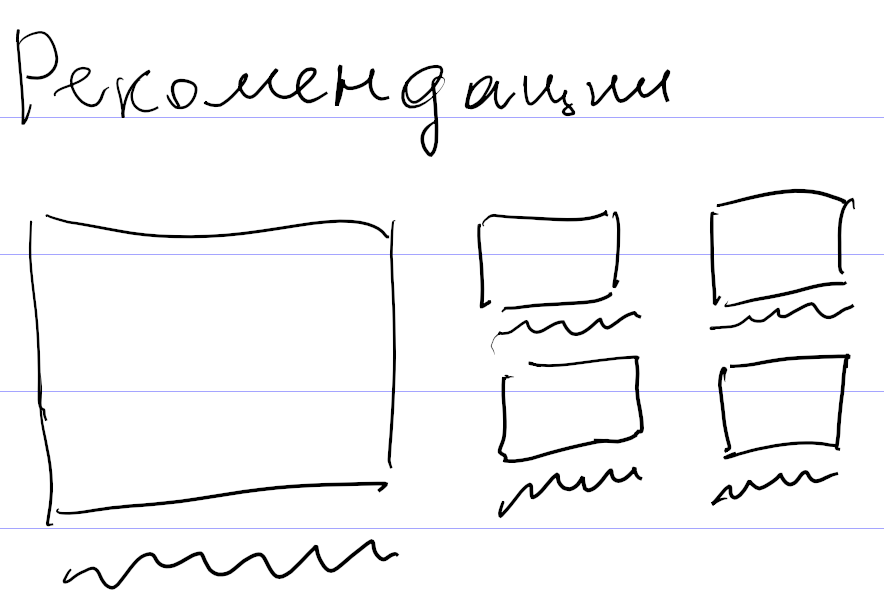
Затем стал смотреть, как имеющиеся рекомендации ко всем подряд заметкам раскладываются по этим вариантам верстки. Выбрал критерий успеха: заметки с картинками не должны выводиться без превьюшек картинок. Если этот критерий не выполнялся, значит, для таких рекомендаций не было подходящего варианта верстки. Я смотрел на них и прикидывал, как надо вывести заметки, чтобы использовать все возможные картинки. Причем делал это не в графическом редакторе, а сразу описывал новый вариант на своем декларативном языке, и он применялся к рекомендациям.
В результате таким способом, никуда не подглядывая, я накопипастил 113 вариантов верстки. Ближе к концу я стал понимать, что это
В процессе мне пришлось изобрести некоторые неочевидные приемы. Например, после определения варианта верстки я сортирую рекомендации по убыванию высоты картинок, а если высота одинакова или картинок вообще нет — по убыванию длины текста. Это нужно, чтобы дыры в верстке появлялись ближе к правому краю, который и так рваный, а не к левому. С дырами получалось забавно: я начал было подбирать длины текста так, чтобы он максимально заполнял дыры. Но рекомендации в некоторых пределах резиновые, а при изменении ширины страницы такие объекты как картинка и текст ведут себя
Еще одно изобретение — отрицательная максимальная длина текста. Она появилась при попытке собрать из картинки и текста блок примерно одинаковой высоты. Скажем, на
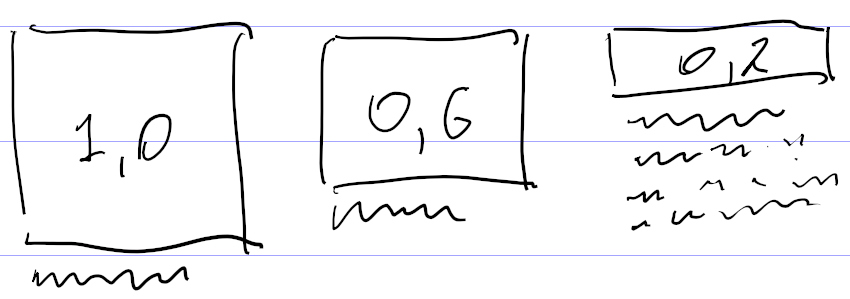
Чтобы не плодить разные варианты одной и той же верстки с таким отличием, я придумал характеризовать текст не только минимальной и максимальной длиной, но и дополнительным коэффициентом, на который умножается «нехватка» высоты картинки для определения дополнительной длины текста. А если картинка с высотой 1,0 тоже подходит, то у картинки с высотой 0,6 за счет добавки обязательно появится текст.
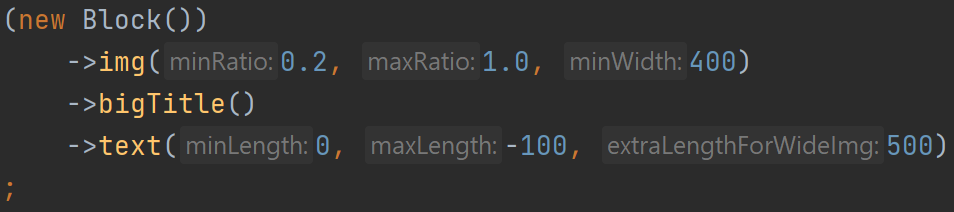
Сначала я хотел сделать дополнительный параметр для отсчета нехватки высоты от 0,6, а не от 1,0. Но потом понял, что того же можно добиться отрицательной длиной текста.
Ограничения рекомендаций и планы на будущее
У Ильи кроме рекомендаций есть еще и перебивки — оформленные таким же образом ссылки в списках записей. Я не стал их делать. В моем понимании рекомендации решают задачу направить посетителя почитать другие записи. Но в списках и так достаточно записей для чтения. Да и технически подобрать ссылки к нескольким записям на одной странице тяжелее, чем к одной записи. Нужно исключать повторы, чтобы одинаковые блоки не повторялись на этой странице.
Сейчас, если в блоке рекомендаций надо вывести текст, я беру
Как определить домен из PHP
Илья Бирман написал про баг в Эгее, когда сайт доступен по разным доменам, и RSS кешируется то с одним доменом, то с другим.
Эгея, чтобы узнать, на каком сервере она работает, смотрит, по какому адресу её открыли — больше ей это узнать неоткуда.
Проблема этого подхода в том, что в PHP (и в любом языке вообще) не существует универсального надежного способа узнать, на каком домене открыли страницу сайта.
HTTP_HOST и SERVER_NAME
Для этих целей обычно проверяют серверную переменную HTTP_HOST. Но в ней всего лишь содержимое заголовка Host из http-запроса. Этот заголовок — часть стандарта HTTP/1.1, и в HTTP/1.0 он не обязателен. Правда, без этого заголовка не заработают виртуальные хосты — разные сайты на общем сервере. Но даже в таком случае среди сайтов есть сайт по умолчанию, открывающийся при заходе напрямую по IP. Так вот, когда устаревшие клиенты (в том числе нормальные браузеры за старыми или специально настроенными прокси) открывают сайт по умолчанию, переменная HTTP_HOST будет пустой.
Есть еще одна серверная переменная — SERVER_NAME. Обычно она содержит хост, определенный в конфигурации
server_name _;Сайт будет прекрасно открываться, но при этом в SERVER_NAME окажется знак подчеркивания.
Подробности для дальнейшего чтения на стековерфлоу: HTTP_HOST vs. SERVER_NAME.
Параметр конфигурации
Если вы делаете распространяемый движок для работы на разных серверах, у вас нет гарантированного способа определить хост, по которому открыт сайт. В моем движке S2 я скопировал способ из PunBB. В нем установочный скрипт «угадывает» адрес сайта (протокол + домен + порт + подпапка) в том числе на основе HTTP_HOST, дает возможность этот адрес отредактировать и сохраняет результат в конфигурационный файл. Затем именно этот адрес используется для генерации ссылок.
Как альтернативу Илья советует настроить редиректы. Это правильно, но, опять же, не всегда выполнимо. Например, вы настроили на сервере https, но не хотите делать редирект с http на https (вы хотите поддерживать старые браузеры, но у вас нет отдельного
Когда одна и та же страница открывается по разным адресам, Гугл рекомендует в явном виде указывать
<link rel="canonical" href="https://example.com/some/url" />Именно они попадут в поисковую выдачу. Ясно, что движок не сможет сгенерировать такой тег, если не будет знать, на каком из доменов он на самом деле работает.
Кстати, давно хотел написать о том, что https — это новый www. Он вынуждает совершать дополнительные бессмысленные действия при настройке сайта вроде редиректов с www. Ради https мне пришлось сделать в S2 поддержку тега link rel="canonical".
С наступающим!
Давно я не поздравлял читателей с праздниками. И сейчас не стану писать банальные вещи. Просто верну долги в уходящем году.

Для меня год пролетел очень быстро. Сочинение музыки — одно из важных достижений. Приятно осознавать, что я достигаю успеха во всём, что мне интересно.
Видео о движке сайтов S2
Сделал видео о своем движке сайтов S2:
В хорошем качестве смотрите на главной сайта движка.
Восстановление текстов в новой версии S2
В новой версии движка S2, которую я выпустил вчера, появилось очень важное нововведение. Теперь он умеет восстанавливать несохраненные тексты после непредвиденных ситуаций вроде зависаний или падений браузера, случайного закрытия окна и т. д.
Интерфейс простой. При следующем входе в админку выводится вот такое сообщение:
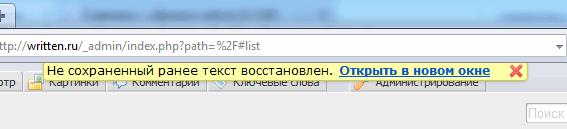
Восстановленный текст из нового окна можно затем скопировать куда угодно.
Реализация тоже крайне простая. Каждые 5 секунд содержимое редактора отправляется в
С помощью этого способа (в отличие от автосохранения) мы оставляем пользователю контроль над тем, когда сохранять редактируемый текст, но избавляемся от проблемы утери несохраненного текста при компьютерных сбоях или непродуманных действиях пользователя.
Совместное редактирование без блокировок
Рассмотрим ситуацию, когда над неким сайтом (или другим проектом) работает коллектив авторов, и подумаем над такой задачей: как обеспечить возможность совместного редактирования документов.
Если над такой возможностью вообще не задумываться, то в ситуации, когда два автора начинают редактировать один и тот же документ, правки одного из авторов скорее всего потеряются.
Эту проблему можно решать при помощи блокировок, как сделано, например, в движке DokuWiki. Когда документ открыт для редактирования одним пользователем, другим пользователям запрещено его редактировать.
Едва ли решение с блокировками можно признать удачным. Если автор начинает редактировать документ, а потом отвлекается, нужно отбирать блокировку по по истечению
Я придумал другой метод, который собираюсь реализовать в своем движке сайтов S2. Этот метод особенно оправдан, если совместное редактирование возникает достаточно редко. Например, редактор должен внести небольшие исправления в документ, написанный автором.
В таких ситуациях вместо надоедливых сообщений о блокировках нужно просто проверять, изменялся ли документ другими пользователями в промежутке между открытием и сохранением. Если изменялся, мы не сохраняем документ, и выводим пользователю сообщение о том, что он должен открыть новую версию документа и самостоятельно перенести туда дописанные фрагменты текста.
Блокировки держат пользователя в напряжении (нельзя отвлекаться больше, чем на 15 минут) и не решают задачу совместного редактирования до конца: всё равно остается возможность возникновения конкурирующих правок. В моем методе ничто без надобности не отвлекает пользователя от его задач.
Новая версия S2 и блог о теоретической физике
Выпустил новую версию движка S2. Среди изменений, помимо испрвлений небольших ошибок, быстрый поиск по заголовкам. Пока пользователь набирает поисковую фразу, ему можно показывать подсказки.
Другое важное изменение — выпуск нового расширения s2_latex для вставки математических формул. С ним на S2 можно легко делать сайты и блоги с кучей формул.
Причем сделал я его не просто так. На нем работает блог о теоретической физике. Мы с коллегами по учебе пишем туда о теоретической физике и связанных вещах. Теперь я публикую там заметки, которые были бы здесь явно не к месту.
Новая версия S2
Про Linode, written.ru и S2
Давно я не писал о хостинге. Не писал, потому что с хостингом у меня до недавнего времени ничего не менялось.
Зимой я решил опубликовать код движка S2 и стал подыскивать репозиторий для исходников. SourceForge, как и другие похожие сервисы для проектов с открытым кодом, имеет в лицензионном соглашении
В одном из пунктов условий использования говорится, что передаваякакие-либо данные через SourceForge.net, пользователи дают SourceForge, Inc. неисключительную пожизненную лицензию на их использование, изменение и продажу.
Мне это не понравилось, и я решил заказать виртуальный сервер, поднять на нем репозиторий subversion и со временем перенести на этот сервер все свои сайты.
Примерно в это же время Иван Сагалаев написал о переезде на
Я заказал самый дешевый вариант. Виртуальный сервер с жестким диском 16 гигабайт, 384 мегабайтами оперативной памяти и месячным трафиком в 200 гигабайт стоил 20 долларов в месяц. Летом, в честь дня рождения Linode, увеличили количество оперативной памяти до 512 мегабайт. Для моих целей такого сервера более чем достаточно.
Приведу свой реферальный код: 8c0e35f89f3d4065678d05cdb156f494d9e8d4c3. Если вы укажете его при регистрации и станете клиентом Linode, мне перепадет копеечка в благодарность за рекомендацию :)
А рекомендаций Linode действительно заслуживает: есть возможность простой смены тарифного плана; переездов между
Со временем я установил и настроил практически все нужные программы. Единственное, с чем не справился — с настройкой почтового сервера. Если быть точным, я повторил инструкцию по настройке SMTP и POP/IMAP серверов с виртуальными почтовыми ящиками, и они даже заработали. Но у меня не хватило терпения, чтобы прикрутить к этому делу хоть
Да и конфигурация почтового сервера не для простых смертных. Я пытался изменить поведение
Мне ничего не оставалось, кроме как сдаться Гуглу — настроить пересылку всех писем на ящик на gmail.com.
Предыдущей ночью настал момент истины. На старом хостинге заканчивается оплаченный период, и я перенес written.ru на свой сервер. Скопировал файлы и содержимое базы данных, переделал .htaccess в конфигурацию nginx, обновил конфигурацию exim, настроил
В качестве лирического отступления расскажу о достоинствах модульной архитектуры S2. Специфичные для конкретных сайтов вещи лучше всего оформить в виде плагинов — расширений. При этом код ядра и других расширений остается нетронутым, и его легко обновлять до новых версий.
Сайт на новом месте себя чувствует очень хорошо. Включил отображение времени работы скриптов в нижней части страницы. Оно редко превышает 10 миллисекунд. Это говорит о том, что и хостинг хороший, и движок хороший :)
Если вдруг заметите, что перестало
Поиск
Написал в блог разработки S2 всё, что я думаю о поиске на сайтах.
А еще я сделал автоматический экспорт
Первый релиз S2
Я доделал сайт движка S2 и сделал самый первый релиз — выпустил
Да, и если можете — попиарьте его, пожалуйста :)
Демо-сайт движка S2
Установил последнюю ревизию S2 на демонстрационный сайт (спасибо рефератам Яндекса). Можно протестировать админку (логин admin и пароль admin). Любые изменения демонстрационного сайта откатываются каждый час, так что не стесняйтесь в своих желаниях :)
Кстати, на дефолтный стиль оформления потратил целый день, и теперь он мне очень нравится.
Пора делать сайт движка и самый первый
Базы данных
Сейчас S2 поддерживает две базы данных: MySQL и PostgreSQL (правда, поддержку последней нужно тестировать).
Вопрос: сильно ли нужна движку сайта поддержка SQLite?
S2
Интересующиеся знают, что written.ru работает на движке, практически целиком написанном с нуля. Последний раз я занимался этим движком два года назад. Тогда нужно было на
Похоже, лучшие времена наступили. Я решил доработать и опубликовать движок. Вообще, характеристики у него и раньше были неплохие, а интерфейс администратора — просто отличный. На этот раз основное внимание я уделил настраиваемости и расширяемости, стилям, языковым пакетам и шаблонам. В общем, всему тому, без чего written.ru спокойно обходился, но без чего нельзя представить себе «настоящую» CMS. В результате в движке поменялось многое.
- оно не вполне уникально;
- интересные домены, содержащие sitex, оказались занятыми;
- название можно прочитать несколькими способами (я подразумевал «сайтекс», а некоторые произносили «сайт икс»).
Я решил изменить название на «S2». Новое название лишено прежних недостатков и обладает рядом достоинств:
- это намек на SiteX второй версии;
- его можно прочитать единственным способом, «эс два»;
- такое название похоже на названия движков b2, e2, R2;
- домены s2cms.ru и даже s2cms.com оказались свободными;
- символы S и 2, расположенные рядом, образуют неповторимую форму, такую, что долго думать над логотипом не приходится.

По сравнению с SiteX пользовательский интерфейс существенно не изменился. Изменилась (точнее, появилась) идеология: S2 — это относительно небольшой и быстрый, но легко расширяемый движок сайта.
Первый релиз S2
Опять про SiteX
SiteX назвали конкурентом движка блогов с названием «Явь» (правда, что он собой представляет и каковы условия его использования — неясно). Забавно.
Кстати, я всё еще не передумал сделать SiteX оупенсорсом. Сейчас SiteX выполняет одну из первых задач — быть движком для written.ru, причем выполняет ее, как нетрудно заметить, вполне успешно. У меня были и другие идеи, реализация которых сделает SiteX
Однако я совсем не против, чтобы отдачу от времени и умственных усилий, ушедших на SiteX, почувствовали и другие. Один из вариантов — сделать код SiteX'а открытым. Смена лицензии будет иметь смысл, если
Мысли и вопросы по поводу вышеизложенного приветствуются.
SiteX
Несколько недель назад я закончил работу над движком сайта SiteX, на котором сейчас работает written.ru. Текущая версия — 0.91. Для тех, кто хочет узнать, что такое SiteX и с чем его едят, я написал небольшой обзор движка.
CMS SiteX — это движок и система редактирования сайта. По сути, она объединяет в себе два различных (хоть и тесно связанных) движка: движок
Краткое описание движка
Движок
Элементы
Структурная единица в блоге — запись (пост). Помимо естественной для блога временной навигации, организована навигация с использованием ключевых слов. Каждая запись отмечается одним или несколькими ключевыми словами. Ключевым словам можно давать описание. Оно будет отображаться на странице этого ключевого слова вместе со всеми связанными записями.
Имеется RSS для статей и для записей в блоге. Записи из блога можно выборочно экспортировать в дневник на LiveJournal.com.
Посетители сайта могут оставлять комментарии к статьям и записям. Система комментариев допускает настройку в достаточно широких пределах.
Система редактирования
Система редактирования (административный интерфейс) использует технологию Ajax и обладает богатой функциональностью. В ней после небольших модификаций были использованы следующие разработки:
—
— сортировка таблиц на JavaScript Александра Шуркаева (удобная штука, кстати);
— всплывающие подсказки оттуда же;
— иконки Silk Icons.
В данной реализации по умолчанию основным редактором является редактор
Административный интерфейс образован несколькими закладками, на каждой из которых сгруппированы элементы управления с близкой функциональностью. Содержимое некоторых закладок приведено на скриншотах.
Управление статьями на сайте. Перетаскивание (drag and drop) — изменение структуры, щелчок — переименование, двойной щелчок — открывает статью для просмотра.
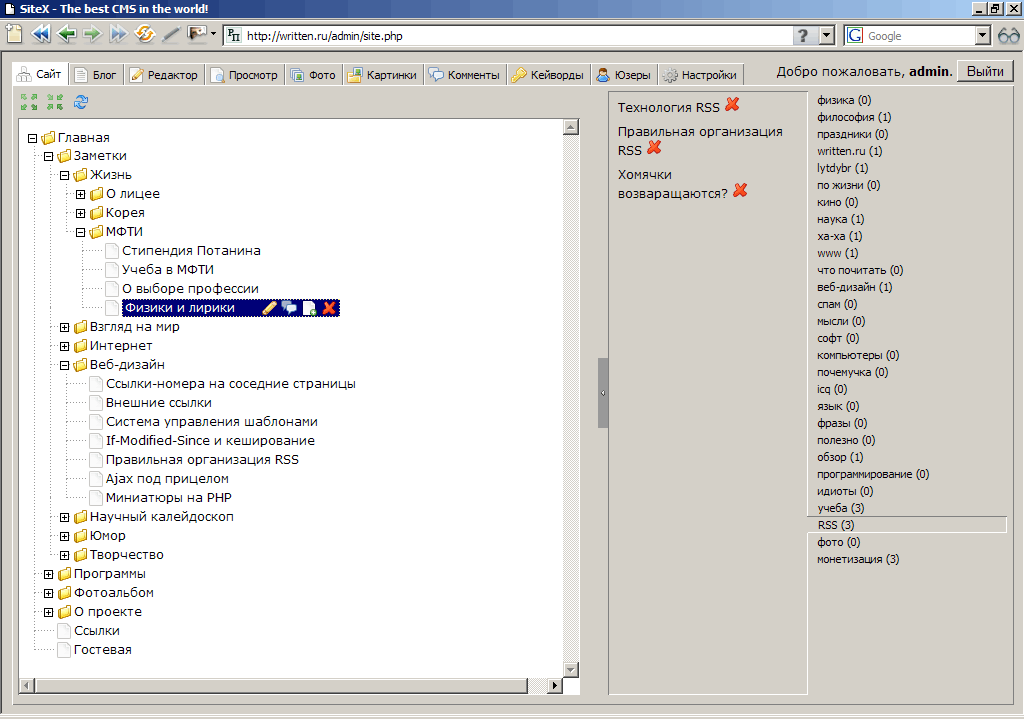
Управление записями в блоге. Поиск записей по критериям, сортировка результатов по дате/названию/количеству комментариев, выбор записи для редактирования.
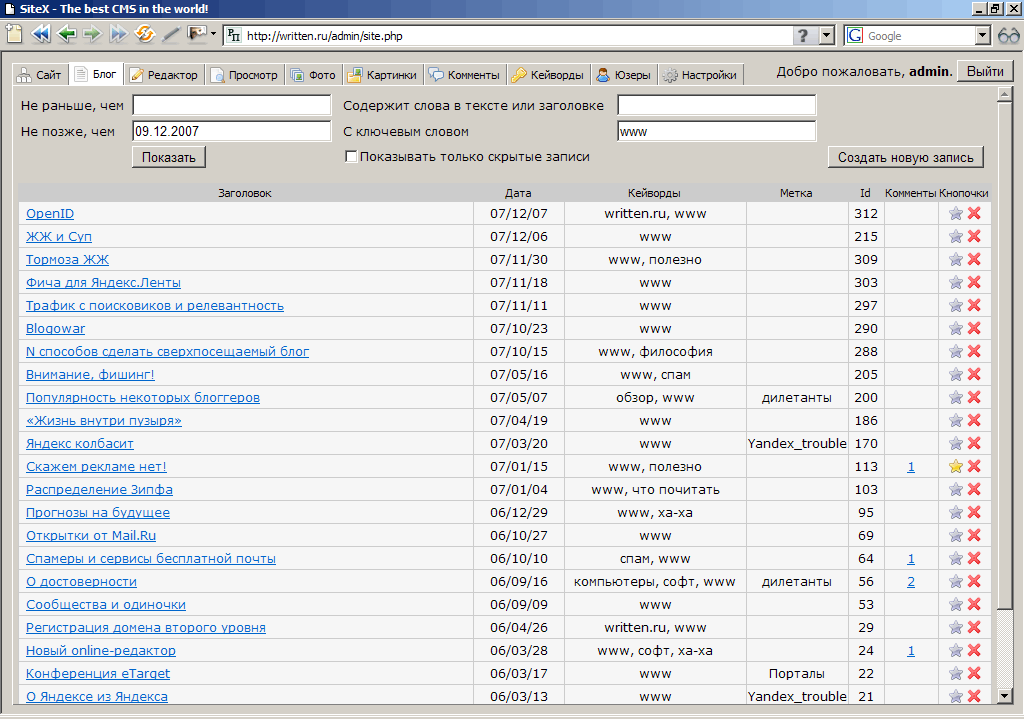
Редактор записей в блоге (основной режим — HTML).
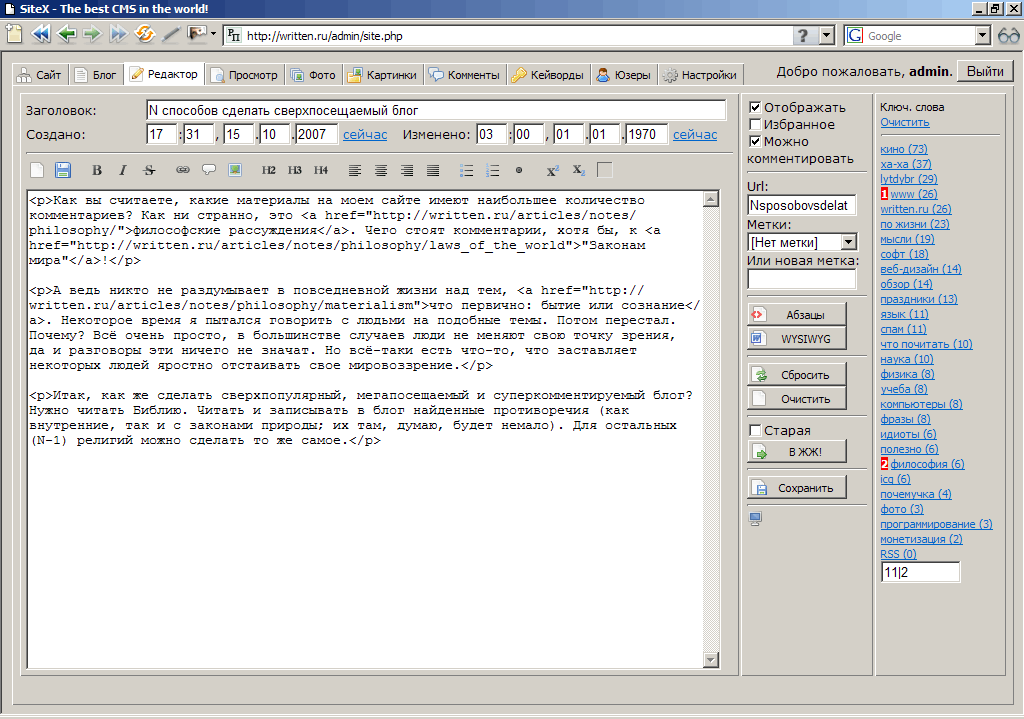
Предварительный просмотр редактируемой записи. Показывает, как будет выглядеть заметка.
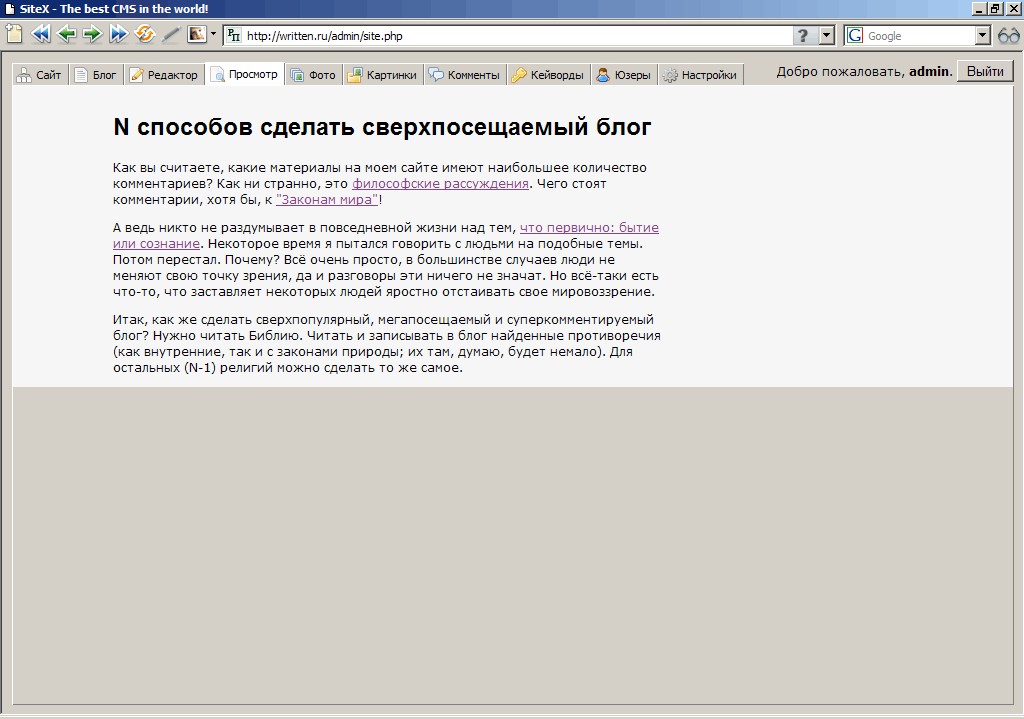
Менеджер картинок. Работает перетаскивание, переименование, загрузка файлов.
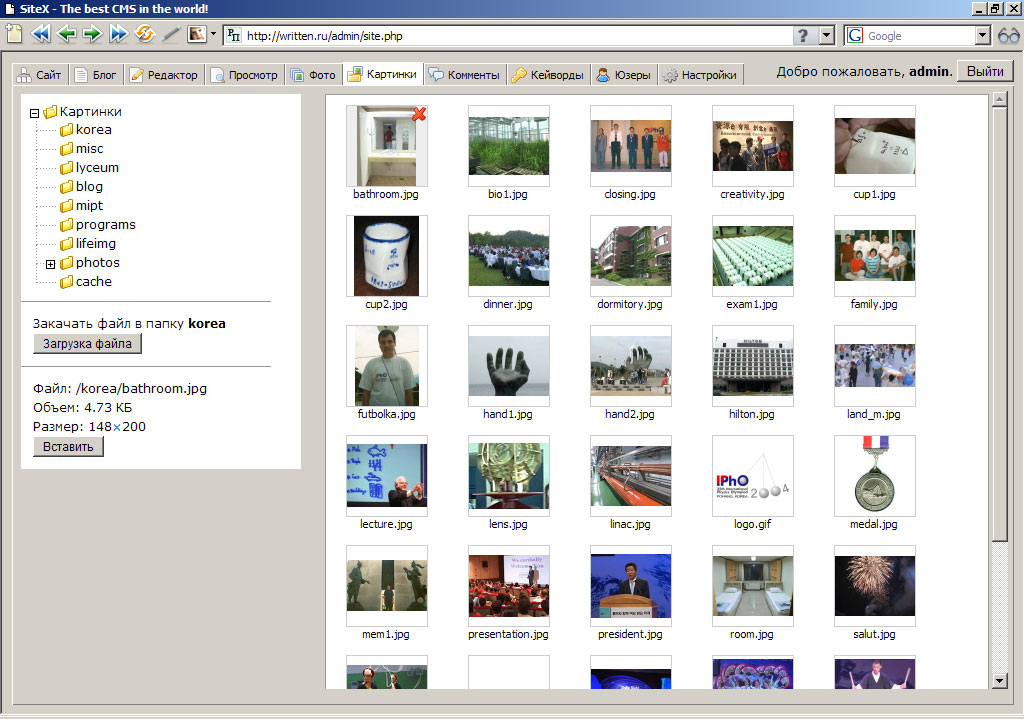
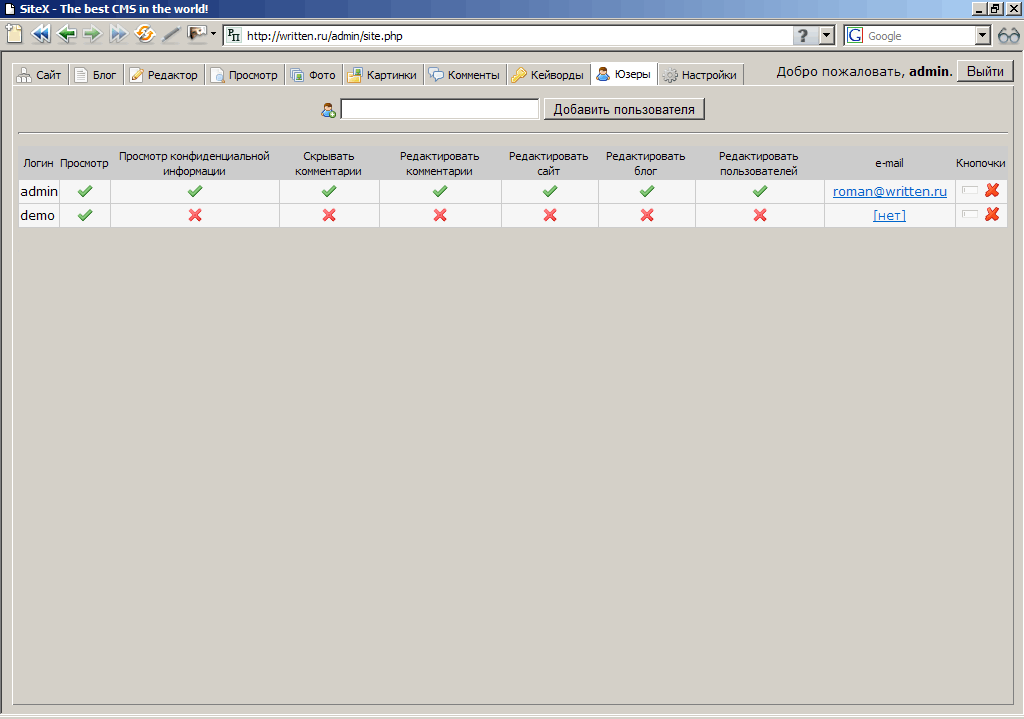
Список пользователей, имеющих доступ к системе редактирования. Администратор может указывать, какой пользователь какими правами обладает. Так назначаются модераторы, главные модераторы и т. д.
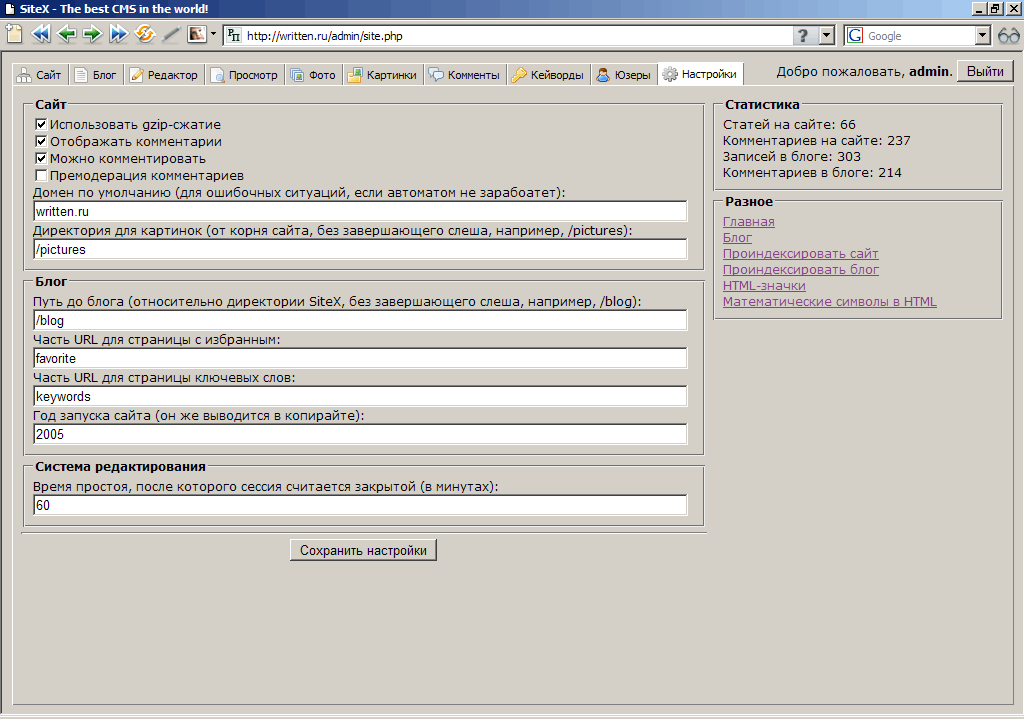
Страница настроек.
Особенности
Узкое место системы — шаблоны. Попытка реализовать универсальный шаблонизатор привела бы к излишней громоздкости. Поэтому в текущей версии движка идея шаблонов хорошо работает только для наиболее универсальных элементов, таких, как заголовок и текст страницы, навигация. Специальные возможности (такие, как последние комментарии на главной странице written.ru) должны в каждом случае реализовываться отдельно, в соответствии с требованиями к проекту.
Движок написан на PHP и требует для работы MySQL версии не ниже 4.1, весьма желательно наличие mod_rewrite.
Движок SiteX бесплатно распространяться не будет. Массовое платное распространение сейчас тоже не планируется. Однако желающие иметь сайт, работающий на SiteX, могут обращаться ко мне, я готов выслушать ваши предложения.
На систему редактирования можно посмотреть в
Комментарии можно оставлять здесь.
У сайта день рождения
Сегодня у сайта written.ru день рождения. Ровно два года назад я закачал на сервер набор
В течение трех недель я написал новый движок (и систему редактирования) с рабочим названием SiteX, о котором я думал и который планировал написать последние полгода. Теперь сайт работает на базе данных, у него есть система редактирования с удобным
Как это обычно случается, я реализовал не всё, что хотел. Иначе чем бы я занимался дальше? ;)
Подробно анализировать события, произошедшие с сайтом за прошедший год, я не буду.
Я неоднократно имел возможность убедиться в том, что самое главное — это сделать первый шаг. Написать материалы, нарисовать
Я знаю, что сделал правильно, когда позапрошлым летом решил создать сайт и довел задуманное до конца.
По мотивам нового движка блога
PHP меня радует такими вещами (хотя заслуги PHP в этом особой нет, это типичный синтаксис C):
while ($row = mysql_fetch_row($result))
$tag_ord[$a[] = $row[0]] = ++$i;А вот MySQL порадовал меня следующим:
SELECT
recs.c_time,
title,
recs.text,
recs.url,
commented,
count(if(comms.id = recs.id, 1, NULL))
FROM recs, rectags, comms
WHERE recs.id = rectags.record_id
AND tag_id = 5
AND published = 1
GROUP BY recs.id
ORDER BY recs.c_time DESCДобавлено 13.12.2007: А сейчас MySQL радует меня возможностью написать такой запрос:
SELECT s.id, b.title, b.c_time, b.url,
FROM (
SELECT rec.id, label
FROM (
SELECT record_id
FROM rectags
WHERE tag_id = 4
) tt, recs
WHERE recs.id = tt.record_id
AND recs.label <> ''
) s, recs b
WHERE s.label = b.label
AND b.id <> s.id
ORDER BY 3 DESCНовый движок блога
Больше месяца прошло с тех пор, как я размышлял о том, что мне не хватает в блоге как в системе для хранения и доступа к информации. Я написал новый движок, на котором сейчас блог и работает. Я реализовал не все возможности, которые хотел. Передо мной стояла дилемма: отложить разработку на неопределенный срок в связи с нехваткой времени, либо доделать до завершенного вида, но без части функций. Поскольку функциональность предыдущего варианта была достигнута и превзойдена, я остановился на втором варианте. Итак, перечислю основные особенности нового движка:
- Для хранения информации используется MySQL (раньше были текстовые файлы).
- Линейная навигация, использовавшая «страницы» по 20 записей, заменена на календарь (как
в R2 илив Interra). - Списки последних записей и комментариев.
- ЧПУ — человекопонятные Url.
- Кеширование на стороне сервера и настройка правильного кеширования в браузере.
- Через RSS экспортируются только те записи, которые появились после предыдущего обращения клиента к RSS.
- Можно подписаться на комментарии к определенной записи.
- Я попробовал сделать защиту от спама в комментариях. Если метод окажется хорошим, я потом напишу о нем.
- У ключевых слов может быть описание (например, как у слова кино). Это позволит в определенной степени реализовать идею «knowledge base» (загляните в размышления).
- Автоматическая типографика.
- Административный интерфейс.
Последний пункт — самый важный. Собственно,
Что еще в планах?
- Поиск. (сделано)
- Простейшая разметка в комментариях, цитирование. (сделано)
- Связывание записей в группы и автоматическая расстановка ссылок «см. также» (некий аналог ключевых слов, только без явного их выделения). (сделано)
- Возможно, RSS отдельно для ключевых слов, комментариев и т. д.
Комментарии по поводу нового движка приветствуются.
Опять об авторских проектах и блогах
Первоначально я задумывал written.ru как авторский проект, на котором будут истории и размышления. Тогда всё выглядело как набор файлов html, редактируемых во FrontPage. Достаточно быстро я сообразил, что это не есть хорошо. Через полгода статьи перекочевали в отдельные почти текстовые файлы, дизайн ушел в шаблоны, и всем этим управляет
Прошло еще полгода. К этому времени стало ясно, что трудно провести границу между блогом и остальной частью сайта в том плане, что не всегда однозначно можно сказать, где следует расположить тот или иной материал. Кроме того, записей в блоге накопилось достаточно много, и он начинает «перевешивать» на сайте. Иногда у меня появляются мысли перенести все статьи в блог и оставить только его (особенно после того, как я в блоге сделал систему редактирования). Независимо от этих соображений (а может и зависимо) у меня назрело желание переписать движок для сайта с использованием MySQL. С нуля. Ну или почти с нуля. С нормальной системой редактирования. Фактически, CMS, но узкоспециализированную.
Возможные решения:
1. Изменить модель хранения и доступа к информации. Сейчас это отдельно статьи на сайте и записи в блоге. Предлагается для рассмотрения вариант knowledge base. Зачем это надо? Такая система хранения записей в отличие от уже надоевших блогов не распространена. Можно постараться и сделать CMS доступной для распространения. Нужно продумать, как те материалы (в том числе из блога), что есть сейчас, впишутся в рамки knowledge base.
2. Оставить всё, как есть. Наиболее простое решение. Правда, придется писать два отдельных движка для блога и для сайта, что не является оригинальным, поскольку уже проделывалось очень много раз.
Добавлено: Материалы на сайте в разделе «Заметки» и записи здесь, в блоге, совершенно различны «по духу». Нет смысла размещать статьи в блоге. Они представляют самостоятельную ценность. Им больше подходит роль структурной единицы на сайте. Записи в блоге в большинстве своем короткие. Они описывают
Структура сайта (распределение статей по разделам) сейчас достаточно наглядна, трудностей у пользователей не возникает. Они также знакомы с блогами. А «knowledge base» может вызвать у новых посетителей затруднения.
Один из вариантов — сделать «блогообразный knowledge base». К некоторым (или всем) ключевым словам можно сделать описание, которое и будет «основным темообразующим документом» в случае необходимости, затем можно разместить ссылки на статьи или даже разделы, имеющие те же ключевые слова, а после выводить записи.
Еще добавлено:
…контент, который востребован и не теряет актуальности со временем (или теряет, но не так быстро, как, например, новости)…
Не совсем понятно, что делать с контентом, который устаревает достаточно быстро (а у меня он есть). В результате размышлений я пришел к выводу, что существующая форма, в которой воплощено содержимое, адекватнее «knowledge base». Придется делать по сути два отдельных движка, хоть и тесно интегрированных. В блоге сделаю возможность давать описание ключевым словам. А также нужно подумать о реализации более тесной связи между блогом и статьями через ключевые слова.
Простейший редактор на javascript
На выходных сделал простейший редактор записей в этом блоге на javascript. За основу взята эта разработка.
Получилось весьма удобно. До сих пор приходилось все теги вручную прописывать (ну, или почти вручную :) ). Непонятно, почему я раньше не сделал нечто подобное.
Может, стоит сделать нечто похожее для комментариев на сайте и блоге. Пока думаю, насколько это будет нужным.
Добавлено: Это дело правильно работает только в Опере. В IE работает немного не так, как хотелось. А Firefox совсем капризничает. Буду выяснять, в чем дело.
Еще добавлено: Firefox капризничает, потому что не понимает document.selection.createRange(). Ну и пусть не понимает, всё равно я Оперой пользуюсь. Тем, кто хочет во всём этом разбираться, можно посоветовать статью о создании своего