PHP
Статьи по этой теме:
Миниатюры на PHP
PHP и
Управление зависимостями на примере composer
Можно ли надежно определить, по какому адресу открыли сайт?
Я уже писал о том, что в PHP нет надежного способа определить текущий домен. Сейчас столкнулся с похожей трудностью с определением порта. Ко мне обратились за помощью с ошибкой в форуме PunBB при входе пользователей.
Напомню, что на своей первой работе в 2008 году я входил в команду разработки этого форума. С тех времен он не сильно развивался, и информацию обо мне до сих пор не удалили со страницы в вики. Видимо, оттуда на меня и вышли.
Проблема у собеседника проявлялась в том, что после отправки формы с логином и паролем редирект происходил на адрес типа https://example.com:80/some_forum_url. Ответ не приходил, потому что на порту 80 никто не обрабатывал
PunBB устроен так, что в момент установки URL форума записывается в специальную переменную в файле настройки. Сама эта переменная была установлена правильно, порта в ней не было: https://example.com/. Но именно после входа неверный порт
Я поискал по коду форума «80» и нашел такую строчку:
$port = (isset($_SERVER['SERVER_PORT'])
&& (
($_SERVER['SERVER_PORT'] != '80' && $protocol == 'http://')
|| ($_SERVER['SERVER_PORT'] != '443' && $protocol == 'https://')
) && strpos($_SERVER['HTTP_HOST'], ':') === false)
? ':'.$_SERVER['SERVER_PORT']
: '';Здесь код пытается понять по значению серверной переменной $_SERVER['SERVER_PORT'], запущен ли он на нестандартном порту. Я предложил заменить строку на $port = ''. Проблема исчезла.
Оказалось, что на хостинге значение переменной $_SERVER['SERVER_PORT'] было установлено неверно. Оно равнялось 80, хотя сам сайт открывается по стандартному для https порту 443.
Надо сказать, что у меня нет понимания, нужно ли вообще обрабатывать значение $_SERVER['SERVER_PORT']. С одной стороны, если не обработать, то движок получается менее универсальным, он не может определить, что запущен на нестандартном порту. С другой стороны, если обрабатывать, можно столкнуться с некорректной настройкой
Чтобы не пытаться определять адрес сайта во время выполнения, авторы PunBB сделали это определение только во время установки для формирования «умной догадки», которую можно подправить. Но
Тесты выявляют проблемы не только с вашим кодом
Удивительные тесты
Представьте, что вы пришли на новый проект и обнаружили в нем вот такой тест:
<?php
use Codeception\Test\Unit;
class MyTest extends Unit
{
public function testHash(): void
{
$this->assertEquals('098f6bcd4621d373cade4e832627b4f6', md5('test'));
}
}
Для неспециалистов поясню, что этот тест вызывает встроенную в PHP функцию md5(), передает ей аргумент 'test' и проверяет, что она возвращает указанное значение.
Зачем нужен этот тест, если встроенная функция и так вычисляет хеш по известному задокументированному алгоритму? Мы же пишем тесты на наш проект, а не на интерпретатор PHP. Написавший этот тест коллега на вопросы отвечает так:
— В наших алгоритмах мы полагаемся на значения хешей, сохраненные в базе данных. Если вдруг функция начнет возвращать другие значения в будущих версиях PHP, мы заметим это по упавшему тесту. Конечно, такие изменения нарушают обратную совместимость, и они должны быть написаны в информации о релизе PHP. Но их можно просмотреть
Как считаете, писать в проекте тест на встроенную функцию PHP — это паранойя? Или разумная предусмотрительность? А что, если это не встроенная функция в PHP, а сторонняя библиотека? Правда же, такой тест вызывает меньше удивления:
<?php
use Codeception\Test\Unit;
use SuperVendor\SuperHashLib\SuperHash;
class MyTest extends Unit
{
public function testHash(): void
{
$this->assertEquals('098f6bcd4621d373cade4e832627b4f6', SuperHash::getHash('test'));
}
}
Тест выявил изменение поведения при обновлении PHP
В моей практике похожий тест действительно однажды помог отследить вредный побочный эффект от нарушения обратной совместимости при обновлении PHP. Минимальный пример для воспроизведения такой:
<?php
class A
{
public $prop1 = '1';
public $prop2 = '2';
public function getHash(): string
{
return md5(serialize($this->normalize()));
}
public function normalize(): array
{
return get_object_vars($this);
}
}
class B extends A
{
public $prop3 = '3';
}
$a = new A;
var_dump($a->getHash());
$b = new B;
var_dump($b->getHash());
Этот код в старых версиях PHP до 8.1 выводит следущее:
string(32) "e5f8d9c52536e3412aa273c7bd4c9dbb"
string(32) "46d9b1133eec8d47fe6e00e970cf0a77"А начиная с 8.1 значение хеша у объекта класса B изменилось:
string(32) "e5f8d9c52536e3412aa273c7bd4c9dbb"
string(32) "8275b764cf277cbbd3b00b1e86d8a4eb"Причина различий в изменении порядка свойств в массиве, возвращаемом get_object_vars(). В старых версиях сначала шли свойства самого класса, а затем унаследованные от родительского:
// До PHP 8.1
Array
(
[prop3] => 3
[prop1] => 1
[prop2] => 2
)В новых же версиях сначала идут унаследованные свойства, а потом собственные свойства класса:
// PHP 8.1 и старше
Array
(
[prop1] => 1
[prop2] => 2
[prop3] => 3
)Как видите, такое изменение поведения при обновлении PHP меняет значения хешей, вычисляемые очевидным и прямолинейным способом. И это изменение даже не было заявлено в информации о релизе как ломающее обратную совместимость!
Мы смогли отловить проблему как раз благодаря тесту, в котором проверялось точное значение вычисленного хеша. Правда, он был написан с другой целью. В нашем случае при добавлении новых полей мы исключали их из вычисления хеша, чтобы хеш не менялся, если новые поля не используются:
<?php
class A
{
public $prop1 = '1';
public $prop2 = '2';
public $propN = null;
public function getHash(): string
{
return md5(serialize($this->normalize()));
}
private function normalize(): array
{
$data = get_object_vars($this);
if ($this->propN === null) {
unset($data['propN']);
}
return $data;
}
}Чтобы разработчики не забывали добавлять unset() новых
Пример решения проблем с обратной совместимостью алгоритмов хеширования
Чтобы дважды не вставать и рассказать не только о проблеме, но и о том, как ее решать, рассмотрим пример, в котором требуется подход с get_object_vars() и вычислением хешей.
Предположим, вы разрабатываете сервис для отслеживания цен на товары в
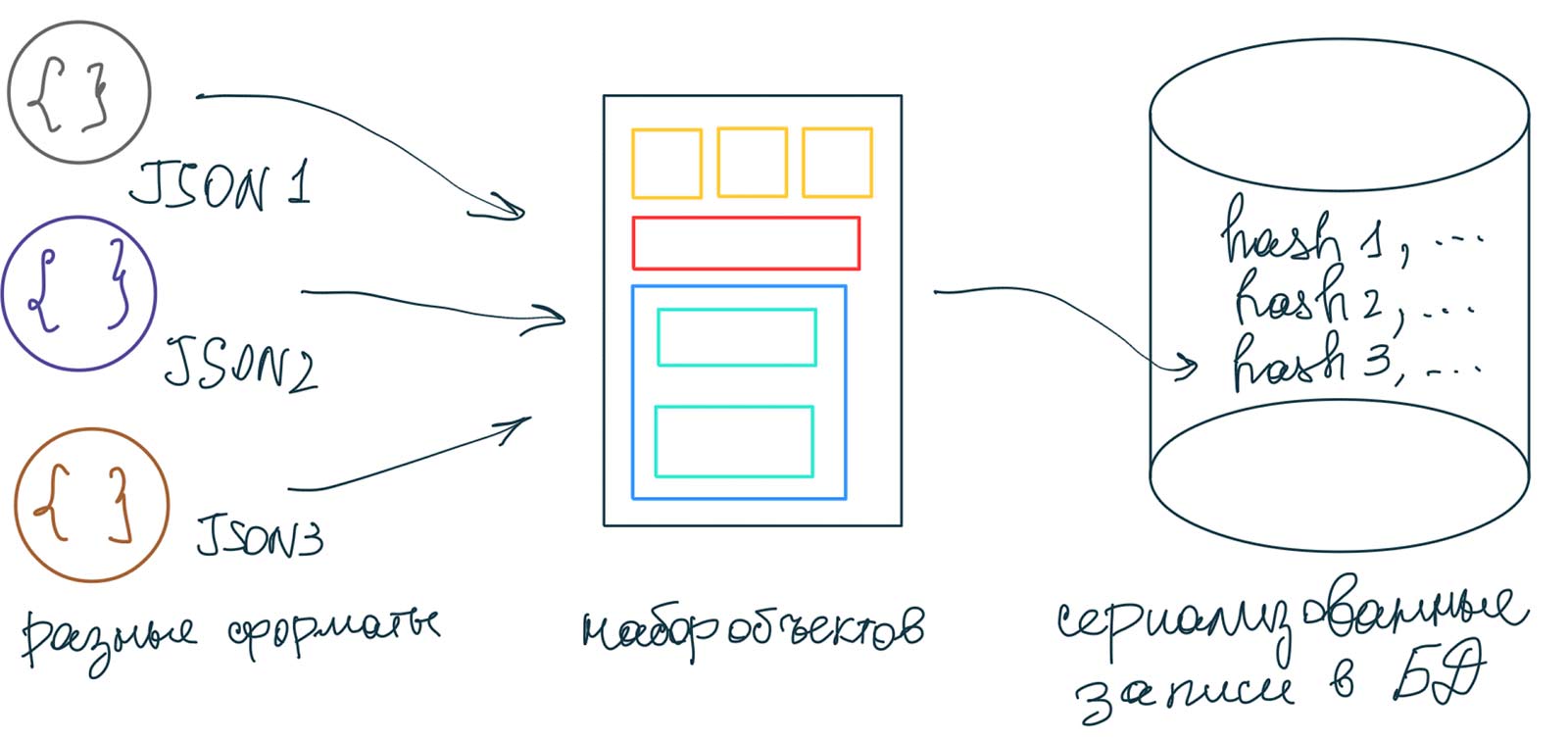
На входе у вас множество источников данных из разных products:
| id | hash | data |
|---|---|---|
| 1001 | e5f8d9c52… | {"color":"red"…} |
| 1002 | 8275b764c… | {"color":"green"…} |
После этого для записи истории цен достаточно вести таблицу price_history:
| product_id | date | price |
|---|---|---|
| 1001 | 1099,9 | |
| 1001 | 1199,9 |
Если в источниках данных появляется новый товар или новая модификация известного товара, метод getHash() вернет неизвестное ранее значение, и в таблицу products добавится новая запись. Если товар ранее уже встречался, значение getHash() уже будет присутствовать в таблице products, и значение для product_id берется из соответствующей записи.
Теперь мы видим, к каким последствиям может привести изменение в алгоритме вычисления хешей. product_id. Вы потратите много времени и сил, пытаясь сначала найти причину проблем, а потом исправлять данные в БД, изменяя идентификаторы и подчищая дубликаты.
Как же решать проблему с изменением алгоритма хеширования? Примерно так же, как изменяется тип колонок в огромных таблицах БД. Для начала напишем новый метод вычисления хеша, инвариантный относительно изменения порядка свойств:
public function getHash2(): string
{
$data = $this->normalize();
ksort($data);
return md5(serialize($data));
}
Далее делаем в таблице БД новую колонку со значением нового хеша. При поиске записей в этой таблице по хешу нужно сначала искать по новой версии хеша, а затем, если ничего не нашли, по старой версии. При добавлении новых записей пока будем записывать значения и новой колонки, и старой. Старые значения хеша всё еще требуются для возможного отката.
После успешной выкладки, если откат не нужен, надо обновить значения новой колонки у старых записей. Это сделает отдельный скрипт, который прочитает все записи, переведет данные в объекты, по объектам посчитает новую версию хешей и выполнит UPDATE.
В завершение можно выкладывать окончательную версию кода, в которой останется только новая версия алгоритма хеширования, и запускать миграцию, которая удалит колонку со старыми версиями хешей.
Вывод
Обычно, когда программист пишет тесты к разрабатываемому приложению, он ориентируется на выполняемые приложением функции. В нашем примере приложение собирает цены из нескольких источников и выводит на странице. Тогда и в тесте сначала импортируется несколько файлов с данными, а затем проверяется, что эти данные выводятся корректно. Это будет означать, что вся цепочка преобразования данных отработала правильно.
Кроме функций приложения, нужно задуматься еще о том, какие предположения делаются в ходе разработки. И эти предположения тоже можно проверять в тестах. Мы разобрали один из примеров, когда предполагалось, что одинаковые данные на входе дадут одинаковые значения хешей. Если забыть о неявном требовании, что хеши не должны меняться со временем (на практике они ведь сравниваются с записанными ранее значениями в БД!), легко написать тесты на саму функцию, которые не упадут при изменении алгоритма хеширования. И вы отправите проблемные изменения в рабочую систему, будучи уверенными, что всё в порядке, так как тесты пройдены.
Неудачная попытка включить JIT в PHP
Обновил на этом сервере версию PHP с 7.4 на 8.2. Решил включить
Оказалось, на JIT влияет только одна настройка, но она не var_dump(opcache_get_status()['jit']);, показывала, что на самом деле JIT не включен.
Не сразу понял, в чем проблема, потому что в логах было пусто. Определить проблему удалось, когда попытался включить JIT для запуска PHP из консоли. В консоль выводилась ошибка
PHP Warning: JIT is incompatible with third party extensions that override zend_execute_ex(). JIT disabled. in Unknown on line 0Поиск проблемы в интернете быстро подсказал причину: расширение для
Попробую JIT
Добавлено 29.03.2024: Включил JIT несколько недель назад. Видимо,
Как покрыть тестами устаревший код?
Многим разработчикам приходилось поддерживать и дорабатывать устаревшие приложения, в которых никогда не было автотестов. С помощью приемочных тестов библиотеки Codeception можно покрыть
Идея приемочных тестов в том, что приложение тестируется целиком, как есть. Для
Я расскажу на примере S2, как добавлять приемочные тесты в
Проще всего Codeception подключить к проекту через composer:
"require-dev": {
"codeception/codeception": "^4.2",
"codeception/module-asserts": "^2.0.0",
"codeception/module-phpbrowser": "^2.0"
}В проекте нужно создать файл codeception.yml:
suites:
acceptance:
actor: AcceptanceTester
modules:
enabled:
- Asserts
- PhpBrowser:
url: http://localhost:8881
curl:
CURLOPT_TIMEOUT_MS: 120000
После этого файлы тестов можно писать в таком
<?php
use Codeception\Example;
class InstallCest
{
public function tryToTest(AcceptanceTester $I, Example $example): void
{
$I->install('admin', 'passwd', $example['db_type'], $example['db_user'], $example['db_password']);
$I->amOnPage('/');
$I->see('Site powered by S2');
$I->click(['link' => 'Page 1']);
$I->see('If you see this text, the install of S2 has been successfully completed.');
$I->canWriteComment();
}
}Здесь методы amOnPage(), see(), click() — встроенные, а install() и canWriteComment() — мои сокращения, определенные в
<?php
use Codeception\Actor;
class AcceptanceTester extends Actor
{
public function install(string $userName, string $userPass, string $dbType, string $dbUser, string $dbPassword): void
{
$I = $this;
$I->amOnPage('/');
$I->seeLink('install S2', '/_admin/install.php');
$I->amOnPage('/_admin/install.php');
$I->seeResponseCodeIs(200);
$I->see('S2 2.0dev', 'h1');
$I->selectOption('req_db_type', $dbType);
$I->fillField('req_db_host', '127.0.0.1'); // not localhost for Github Actions
$I->fillField('req_db_name', 's2_test');
$I->fillField('db_username', $dbUser);
$I->fillField('db_password', $dbPassword);
$I->fillField('req_username', $userName);
$I->fillField('req_password', $userPass);
$I->click('start');
$I->canSeeResponseCodeIs(200);
$I->see('S2 is completely installed!');
}
public function canWriteComment(): void
{
$I = $this;
$name = 'Roman 🌞';
$I->fillField('name', $name);
$I->fillField('email', 'roman@example.com');
$I->fillField('text', 'This is my first comment! 👪🐶');
$text = $I->grabTextFrom('p#qsp');
preg_match('#(\d\d)\+(\d)#', $text, $matches);
$I->fillField('question', (int)$matches[1] + (int)$matches[2]);
$I->click('submit');
$I->seeResponseCodeIs(200);
$I->see($name . ' wrote:');
$I->see('This is my first comment!');
}
}Теперь посмотрим, как это всё запускается. Я написал отдельный скрипт:
# Очистка тестовой базы данных
mysql -uroot --execute="DROP DATABASE IF EXISTS s2_test; CREATE DATABASE s2_test;"
# Запуск веб-сервера
APP_ENV=test \
PHP_CLI_SERVER_WORKERS=2 \
nohup php \
-d "max_execution_time=-1" \
-d "opcache.revalidate_freq=0" \
-S localhost:8881 >/dev/null 2>&1 &
serverPID=$!
# Запуск тестов
php _vendor/bin/codecept run acceptance
pkill -P $serverPID # Убиваем воркеры PHP, образовавшиеся из-за PHP_CLI_SERVER_WORKERS
kill $serverPIDПеред запуском тестов поднимается встроенный в php http://localhost:8881/. PHP_CLI_SERVER_WORKERS=2), так как движок в процессе установки обращается сам к себе, чтобы понять, какая схема перезаписи URL доступна. В процессе установки создается файл config.php. Чтобы PHP сразу видел изменения в этом файле, пришлось переопределить параметр из php.ini: opcache.revalidate_freq=0. Альтернатива — добавить sleep(), но я не хотел играться с ненадежными способами. Переменная окружения APP_ENV=test говорит движку, чтобы он вместо файла config.php создавал и использовал файл config.test.php. Это упрощает запуск и тестов и обычной версии для разработки из одной папки.
Достоинства получившегося способа написания приемочных тестов следующие. Устаревший код приложения практически не нужно дорабатывать, чтобы писать тесты. Так как приложение тестируется через HTTP API, внутренние изменения в приложении, не меняющие API, не требуют доработки тестов. Тесты запускаются где угодно, я даже добавил запуск тестов в github actions при каждом пуше веток.
Недостатки, как обычно, есть продолжения достоинств. Тесты покрывают только серверную часть,
Задача о педантичном пассажире
В недавней поездке наблюдал, как люди рассаживаются в автобусе. Чтобы скоротать время в дороге, решил прикинуть, насколько тяжело пересаживаться людям, занимающим места не по билетам. Задачу пришлось решать в уме, так как черновика и ручки не было. Правда, был мобильник с интернетом, так что без чтения википедии и других сайтов не обошлось. Однако ничего полезного не нашел и решил задачу самостоятельно.

Условие
В автобусе n пронумерованных мест. Пассажиры занимают места в случайном порядке, не обращая внимание на номера в билетах. Последний пассажир оказывается педантичным — он хочет сидеть на своем месте. Если место педантичного пассажира занято, он заставляет сидящего там пассажира пересесть. Пересаживающийся пассажир тоже становится педантичным и идет на свое место. Процесс пересаживания продолжается до тех пор, пока последний педантичный пассажир не усядется в пустое место. Сколько в среднем пассажиров пересядет?
Математическая природа задачи
Знакомые с теорией представлений групп перестановок сразу скажут, какая идея скрывается за формулировкой задачи. Мне же придется пересказать некоторые математические факты, чтобы пояснить ход рассуждений.
Сидящие в
$$\begin{pmatrix} \text{места}\\ \text{билеты} \end{pmatrix}=\begin{pmatrix} 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 \\ 4 & 6 & \bf{1^*} & 2 & 5 & 3 & 8 & 7 \end{pmatrix}.$$
Для удобства рассуждений будем считать, что педантичный пассажир имеет билет номер 1. (Интуитивно понятно, что ответ в задаче не зависит от конкретного номера билета у педантичного пассажира, но вы попробуйте это доказать в качестве упражнения.) Если бы пассажир не был педантичным, он просто занял бы свободное место с номером 3. Но поскольку пассажир педантичный, он заставляет пересесть пассажира 4, тот заставляет пересесть пассажира 2, дальше пересаживается пассажир 6 и, наконец, пассажир 3 идет на свое свободное место:
$$\tikzcdset{arrow style=tikz,diagrams={>=stealth}} \begin{matrix} \left(\begin{tikzcd}[row sep=14pt,column sep=12pt] 1\ar[d] & 2\ar[d] & 3\ar[d] & 4\ar[d] & 5 & 6\ar[d] & 7 & 8 \\ 4\ar[urrr,dotted,looseness=1,in=155] & 6\ar[urrrr,dotted,looseness=1,in=160] & 1\ar[ull,dotted] & 2\ar[ull,dotted] & 5 & 3\ar[ulll,dotted] & 8 & 7 \end{tikzcd}\right) \end{matrix}$$
Получившаяся цепочка (1 4 2 6 3) называется циклом.
Таким образом, в задаче фактически нужно найти среднюю длину цикла, содержащего случайно выбранный элемент случайной перестановки.
Погружение в теорию
Любая перестановка распадается на один или несколько циклов. В нашем примере это циклы $$(1\ 4\ 2\ 6\ 3)(5)(7\ 8)$$. Циклы могут иметь произвольную положительную длину. Единственное ограничение на циклы — сумма их длин равна n. Фактически циклическая структура перестановки описывается разбиением чисел.
Разбиения чисел, как и циклы в перестановках, изображают графически в виде диаграмм Юнга. Каждая строка этой диаграммы соответствует своему циклу, строки расположены в порядке убывания длины. В нашем примере диаграмма Юнга имеет вид:
$$\begin{tikzpicture}[scale=0.52725]\small \draw[line width=0.2mm] (0,0) grid (5,-1) (0,-1) grid (2,-2) (0,-2) grid (1,-3); \end{tikzpicture}$$
Каждой диаграмме Юнга, в которой $$m_1$$ циклов длины 1, $$m_2$$ циклов длины 2 и т. д. соответствует следующее количество перестановок:
$$N={n!\over 1^{m_1}m_1!\cdot 2^{m_2}m_2!\cdot\ldots\cdot n^{m_n}m_n!}.$$
Давайте для тренировки проверим, что получится для нашей диаграммы Юнга:
$$N_{8 = 5 + 2 + 1}={8!\over 1^{1}1!\cdot 2^{1}1!\cdot 5^{1}1!}={8!\over 10}=4032.$$
Выходит, среди всех 8! = 40320 перестановок из 8 элементов десятая часть имеет структуру, описываемую разбиением 8 = 5 + 2 + 1.
Теперь надо перебрать все диаграммы Юнга, для каждой вычислить вес по этой формуле и усреднить длину строк с такими коэффициентами. Осталась «небольшая» проблема — я не знаю простого аналитического способа перебора диаграмм Юнга. Такой метод решения задачи заводит в тупик, особенно если решать в уме. Поэтому забудем всё, что здесь было написано, и будем решать задачу с нуля без
Решение «на пальцах»
Как было написано выше, мы будем вычислять среднюю длину цикла, содержащего первый элемент в случайной перестановке длины n. (Вместо первого элемента можно брать любой: из формул дальше видно, что ответ от этого не зависит.) Под средней длиной понимается математическое ожидание — усреднение длины цикла с весами, равными вероятностям:
$$L=P_1\cdot 1+P_2\cdot 2 +\ldots+P_n\cdot n,$$
где $$P_1$$ — вероятность того, что цикл имеет длину 1, $$P_2$$ — что имеет длину 2 и т. д. Ясно, что циклов с длиной больше чем полное количество элементов n не бывает, и слагаемые в формуле останавливаются на n.
В этой формуле легко подсчитать $$P_1$$. Так как перестановки случайные, элемент 1 с равной вероятностью может переводиться перестановкой в любой другой элемент от 1 до n. Если 1 переходит в 1, мы получаем цикл длины 1:
$$\begin{pmatrix} 1 & 2 & \ldots & n\\ 1 & * & \ldots & * \end{pmatrix}.$$
В противном случае длина цикла будет больше. Таким образом, $$P_1=1/n$$ — с такой вероятностью можно выбрать число 1 из первых n чисел.
Попробуем теперь вычислить $$P_2$$. Чтобы получился цикл длины 2, элемент 1 должен переходить в элемент $$k\neq 1$$, а элемент k — в 1:
$$\begin{pmatrix} 1 & \ldots & k & \ldots & n\\ k & \ldots & 1 & \ldots & *\\ \end{pmatrix}.$$
Есть $$n-1$$ способ выбрать первый элемент $$k\neq1$$, что дает вероятность $$(n-1)/n$$ (действительно, в противном случае мы бы получили цикл длины 1 с вероятностью $$P_1=1/n$$). Вторым элементом должен быть 1, его можно выбрать из оставшихся $$n-1$$ элементов с вероятностью $$1/(n-1)$$. Таким образом,
$$P_2={n-1\over n}\cdot{1\over n-1}={1\over n}.$$
Удивительно, но мы получили, что $$P_1=P_2=1/n$$. Давайте проверим, совпадение ли это, или закономерность. Цикл будет иметь длину 3, если его длина не 1 и не 2, и если третьим элементом мы выберем 1. Вероятность этого
$$P_3=\left(1-P_1-P_2\right)\cdot{1\over n-2}={n-2\over n}\cdot{1\over n-2}={1\over n}.$$
Аналогично все остальные вероятности тоже совпадают: $$P_i=1/n$$. Таким образом, средняя длина цикла $$L=(n+1)/2$$.
Вывод
В автобусе с количеством мест n педантичный пассажир спровоцирует $$(n+1)/2$$ пересадок. Или, если исключить его самого из этого числа, пересядет $$(n-1)/2$$ других пассажиров. Мы не только вычислили среднее количество пересаживающихся пассажиров, а еще и нашли распределение этого количества: оно оказалось равномерным. Иными словами, с равной вероятностью педантичный пассажир сядет в свое пустое место, или заставит пересесть одного пассажира, или двух и т. д. Все эти исходы оказываются равновероятными.
Послесловие
Простота ответа — пересесть должна половина автобуса — наводит на мысль о том, что задачу можно решить только с помощью некоторой наглядной картинки, вообще без вычислений. К сожалению, я пока не придумал, как это сделать. Например, можно мысленно переставить сиденья с пассажирами в один ряд так, чтобы в процессе пересаживания педантичный пассажир садился на случайное место, заставляя пересесть всех пассажиров справа от него на одно место. Ясно, что для такой вставки элемента среднее количество операций совпадает с вычисленным ответом. Но откуда возьмется связь между случайным циклом случайной перестановки и элементами справа от случайно выбранного элемента? Как между ними установить соответствие, сохраняющее вероятности?
И, наконец, если вы сомневаетесь в правильности ответа, можете запустить скрипт, вычисляющий ответ методом полного перебора. Алгоритм перебора перестановок взял из книжки. Сконвертировал код из Perl в PHP с помощью ChatGPT. Усреднение длины цикла делается тривиально.
<?php
function nextShuffle(array $shuffle): ?array {
for ($i = 1, $count = count($shuffle); $i < $count; $i++) {
if ($shuffle[$i] < $i) {
$shuffle[$i]++;
return $shuffle;
}
$shuffle[$i] = 0;
}
return null;
}
// Длина цикла, содержащего элемент 1.
function cycleLength(array $p): int {
$num = 1;
$result = 0;
while ($p[$num - 1] !== 1) {
$num = $p[$num - 1];
$result++;
}
return $result;
}
$n = (int)$argv[1];
if ($n <= 0) {
die("$argv[0]: Нужно неотрицательное число!\n");
}
$shuffle = array_fill(0, $n, 0);
$totalLength = 0;
$totalPermutations = 0;
while ($shuffle !== null) {
// Начальная перестановка
$p = range(1, $n);
// Применение транспозиций
for ($i = 0; $i < $n; $i++) {
$temp = $p[$i];
$p[$i] = $p[$shuffle[$i]];
$p[$shuffle[$i]] = $temp;
}
$length = cycleLength($p);
$totalLength += $length;
$totalPermutations++;
// echo implode(" ", $p), " | ", $length, "\n";
// Генерирование следующего набора транспозиций
$shuffle = nextShuffle($shuffle);
}
echo "Всего перестановок (факториал) = ", $totalPermutations, "\n",
"Среднее количество пересадок = ", $totalLength / $totalPermutations, "\n";
Пример результата запуска:
> php script.php 8
Всего перестановок (факториал) = 40320
Среднее количество пересадок = 3.5
Http-прокси на PHP
Обычно в постах о программировании я пишу об успешных подходах и находках. В этот раз расскажу об идее, которая на практике не заработала.
В прошлый раз я рассказывал, что если у вас есть свой виртуальный сервер, вы можете не возиться с VPN, а отправить трафик из браузера через
Я задумался, можно ли провернуть такой же трюк без своего виртуального сервера. Стал смотреть в сторону виртуальных (shared) хостингов, в частности бесплатных или предоставляющих бесплатный тестовый период. На hostings.info нашел бесплатный хостинг с доступом по SSH. Трюк с
Я стал думать дальше и решил попробовать другой вариант. На сервере хостера запущен PHP. Я могу подключиться к нему через обычный
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Psr7\Request;
use GuzzleHttp\Psr7\ServerRequest;
// Создание экземпляра клиента Guzzle
$client = new Client();
// Обработка входящего запроса
$request = ServerRequest::fromGlobals();
// Получение URL-адреса запрашиваемого сайта
$url = $request->getUri();
$url
// Я собирался ходить на https-сайты, поэтому подменил протокол и порт
->withScheme('https')
->withPort(443)
// Подменяем хост (видимо, тут и происходит обработка протокола http-прокси)
->withHost($request->getHeaderLine('host'))
->withQuery($request->getUri()->getQuery())
;
// Создание прокси-запроса
$proxyRequest = new Request(
$request->getMethod(),
$url,
$request->getHeaders(),
$request->getBody(),
$request->getProtocolVersion()
);
// Отправка прокси-запроса и получение ответа
$response = $client->send($proxyRequest, [
'stream' => true,
'verify' => false,
'allow_redirects' => false, // Коды редиректов отправляем назад в браузер
]);
// Передача заголовков ответа клиенту
foreach ($response->getHeaders() as $name => $values) {
foreach ($values as $value) {
header(sprintf('%s: %s', $name, $value), false);
}
}
// Передача тела ответа клиенту
echo $response->getBody();
Чтобы этот скрипт завести, нужно сохранить его в файл со произвольным редким названием, например, q7e6r53t.php, и установить через composer библиотеку guzzle. Кроме того, в nginx в настройку хоста надо добавить следующее:
server {
listen 8082;
server_name localhost;
root /mnt/c/git/proxy;
location / {
try_files $uri $uri/ /q7e6r53t.php$is_args$args;
}
location ~ \q7e6r53t.php$ {
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_index index.php;
include fastcgi.conf;
}
}
В таком варианте прокси заработал локально, даже с авторизацией и куками. Самый большой недостаток этого подхода в том, что нельзя проксировать
127.0.0.1 - - [18/Jun/2023:12:56:47 +0300] "CONNECT www.google.com:443 HTTP/1.1" 400 166 "-" "-"И даже если вдруг представить, что такое возможно, это был бы man in the middle. Поэтому в браузере приходится набирать адрес сайта с http, а скрипт подменяет протокол на https. Если в PHP нет нужных сертификатов, подключиться к сайту будет невозможно. Для отключения проверки сертификатов я добавил флаг 'verify' => false. Конечно, это несекьюрно, но тут и так трафик передается хостеру в открытом виде, так что держать ворота запертыми в открытом поле смысла нет :)
На практике у хостера этот скрипт не заработал. В браузере отображалась страница ошибки Apache о неправильно сконфигурированном хосте. Очевидно, Apache настроен так, чтобы не позволять так просто делать
В ходе лабораторной работы мы написали простейший скрипт
Очередь на основе PHP-FPM
Применил на практике прием, когда асинхронная очередь обработки сообщений реализовывается через
Обычно
Положительные стороны:
- Не нужны дополнительные компоненты в системе.
PHP-FPM сам заботится о запуске рабочих процессов, достаточно отредактировать конфиг.
Отрицательные стороны:
- Нет надежного хранения сообщений. Если процесс
PHP-FPM упадет, сообщения потеряются. - Нет мониторинга. Если нужен — придется делать самостоятельно.
Чтобы сделать такую очередь, возьмите готовые библиотеки для общения по протоколу fastcgi, например,
Как определить домен из PHP
Илья Бирман написал про баг в Эгее, когда сайт доступен по разным доменам, и RSS кешируется то с одним доменом, то с другим.
Эгея, чтобы узнать, на каком сервере она работает, смотрит, по какому адресу её открыли — больше ей это узнать неоткуда.
Проблема этого подхода в том, что в PHP (и в любом языке вообще) не существует универсального надежного способа узнать, на каком домене открыли страницу сайта.
HTTP_HOST и SERVER_NAME
Для этих целей обычно проверяют серверную переменную HTTP_HOST. Но в ней всего лишь содержимое заголовка Host из http-запроса. Этот заголовок — часть стандарта HTTP/1.1, и в HTTP/1.0 он не обязателен. Правда, без этого заголовка не заработают виртуальные хосты — разные сайты на общем сервере. Но даже в таком случае среди сайтов есть сайт по умолчанию, открывающийся при заходе напрямую по IP. Так вот, когда устаревшие клиенты (в том числе нормальные браузеры за старыми или специально настроенными прокси) открывают сайт по умолчанию, переменная HTTP_HOST будет пустой.
Есть еще одна серверная переменная — SERVER_NAME. Обычно она содержит хост, определенный в конфигурации
server_name _;Сайт будет прекрасно открываться, но при этом в SERVER_NAME окажется знак подчеркивания.
Подробности для дальнейшего чтения на стековерфлоу: HTTP_HOST vs. SERVER_NAME.
Параметр конфигурации
Если вы делаете распространяемый движок для работы на разных серверах, у вас нет гарантированного способа определить хост, по которому открыт сайт. В моем движке S2 я скопировал способ из PunBB. В нем установочный скрипт «угадывает» адрес сайта (протокол + домен + порт + подпапка) в том числе на основе HTTP_HOST, дает возможность этот адрес отредактировать и сохраняет результат в конфигурационный файл. Затем именно этот адрес используется для генерации ссылок.
Как альтернативу Илья советует настроить редиректы. Это правильно, но, опять же, не всегда выполнимо. Например, вы настроили на сервере https, но не хотите делать редирект с http на https (вы хотите поддерживать старые браузеры, но у вас нет отдельного
Когда одна и та же страница открывается по разным адресам, Гугл рекомендует в явном виде указывать
<link rel="canonical" href="https://example.com/some/url" />Именно они попадут в поисковую выдачу. Ясно, что движок не сможет сгенерировать такой тег, если не будет знать, на каком из доменов он на самом деле работает.
Кстати, давно хотел написать о том, что https — это новый www. Он вынуждает совершать дополнительные бессмысленные действия при настройке сайта вроде редиректов с www. Ради https мне пришлось сделать в S2 поддержку тега link rel="canonical".
Пишем объектно-ориентированный код в PhpStorm — В кресле препода №1
В прошлом посте я разрушал мифы о среде разработки PhpStorm. В продолжение я записал скринкаст о том, как в ней писать
Скринкаст рассчитан на людей, не владеющих уверенно ООП. На записи я перевожу фрагмент кода из процедурного стиля в
Содержание:
00:19 Процедурный стиль vs.
01:11 PHP не для процедурного программирования
02:22 ООП в PHP: много рутины
03:05 Задача: показать не только приемы работы в PhpStorm, но и пользу от ООП
04:08 Выбираем код для рефакторинга
05:10 Создаем класс: пространство имен; методы; константы
10:36 Автозагрузка классов через composer
13:28 Разбираем проблемы кода
15:34 Возвращаем вместо массива объект (DTO)
24:29 Избавляемся от глобальных переменных по принципу инверсии зависимостей (dependency inversion)
29:29 Наполняем DTO логикой: __toString
33:16 Рефакторинг
35:14 Наполняем DTO логикой: валидация в конструкторе
39:40 Получился код по принципам SOLID
40:24 Проблема создания сервисов
41:04 Решение с помощью контейнеров зависимостей; подключение Pimple через composer
46:01 Обзор изменений, привнесенных
48:09 Дополнение: подключаем библиотеку поиска Rose, описывая сервисы в контейнере
01:01:38 Подведение итогов
Оптимизация памяти в PHP и функция serialize
Хорошая статья на Хабре про особенности выделения памяти в PHP. Обычно на расход памяти в
Не так давно я писал требовательный к памяти скрипт. Это скрипт поиска, ранняя версия которого используется на сайте правил русского языка, а адаптированная версия перекочевала в мой движок сайтов.
Я немного поколдовал с кодом и в итоге сократил потребление памяти более чем в два раза. Раньше для индексации этого сайта нужно было 32 мегабайта оперативной памяти, а теперь достаточно и 16. Кроме методов из статьи, я применил запись чисел в системе счисления по основанию 36 (перевод осуществляется функцией
Дело в том, что функция
file_put_contents($filename, 'a:'.count($array).':{');
$buffer = '';
$length = 0;
foreach ($array as $word => $data)
{
$chunk = serialize($word).serialize($data);
$length += strlen($chunk);
$buffer .= $chunk;
if ($length > 100000)
{
file_put_contents($filename, $buffer, FILE_APPEND);
$buffer = '';
$length = 0;
}
}
file_put_contents($filename, $buffer.'}', FILE_APPEND);Запись происходит порциями размером около 100 килобайт. Этот код подходит для сохранения в файл массива с большим количеством элементов среднего размера и решает проблему перерасхода памяти функцией
Загадка специалистам по PHP
Как вы думаете, что выведут следующие операторы?
<?php
echo preg_match('#тес#iu', 'Такой Вот Тест');
echo preg_match('#Тес#Siu', 'Такой Вот Тест');
echo preg_match('#тес#Siu', 'Такой Вот Тест');
echo preg_match('#во#Siu', 'Такой Вот Тест');Логика подсказывает, что 1111, а на опыте оказалось 1101. Причем и в Windows, и в Linux (Debian, PHP 5.2.6). Я подумал, что комбинация модификаторов Siu несовместима (и даже убрал в отлаживаемом коде модификатор S). Но почему тогда последнее регулярное выражение срабатывает правильно?
Кто подскажет, в чем тут дело?
UTF-8 bad chars
Вопрос о «плохих» данных в
#.*#/u
У регулярных выражений PHP есть специальный модификатор u для работы со строками в кодировке
Когда же модификатор u необходим? Только тогда, когда в регулярном выражении указывается количество символов или в квадратных скобках присутствуют символы, не входящие в нижнюю половину таблицы ASCII.
В процессе оптимизации можно попытаться изменить регулярное выражение и убрать из него модификатор u.
Как всегда, лучше проверять на практике необходимость модификатора u в каждом конкретном регулярном выражении и его влияние на время выполнения скрипта.
PHP: навигация
Некоторое время назад Илья Бирман написал про подсветку ключевых слов. В комментариях после моего замечания о возможности использовать функцию preg_replace развязалась небольшая дискуссия о том, как правильно нужно генерировать подобные вещи. Вот что писал Илья:
*_replace — это вообще не наш метод, надо сразу всё правильно генерировать, а не резать по живому потом.
…
А генерировать неправильный контент, чтобы потом его героически исправить — это левак, нужно сразу генерировать правильный.
Рассмотрим достоинства и недостатки различных подходов к генерации контента на простом примере навигационных ссылок.
Использование preg_replace позволяет сделать код коротким и понятным.
$cur_url = 'item2.htm';
$menu = '<a href="item1.htm">item1</a><br />
<a href="item2.htm">item2</a><br />
<a href="item3.htm">item3</a><br />
<a href="item4.htm">item4</a><br />
<a href="item5.htm">item5</a>';
$menu = preg_replace(
'#<a href="'.$cur_url.'">([^<]*)</a>#',
'<span>\\1</span>',
$menu);Однако на мой взгляд этот код может быть расценен в соответствии с цитатой как «левак». Я не знаю, какой способ является правильным в этой ситуации с точки зрения Ильи, но могу предположить, что он должен быть примерно таким:
$cur_url = 'item2.htm';
$menu_array = array(
'item1.htm' => 'item1',
'item2.htm' => 'item2',
'item3.htm' => 'item3',
'item4.htm' => 'item4',
'item5.htm' => 'item5'
);
$menu = '';
foreach ($menu_array as $url => $link) {
if ($url != $cur_url)
$menu .= '<a href="'.$url.'">'.$link.'</a><br />';
else
$menu .= '<span>'.$link.'</span><br />';
}Этот код является чуть более громоздким. К тому же, у метода не всё в порядке с производительностью. Проведенные тесты показали, что он примерно в три раза медленнее, чем предыдущий.
Можно применить и третий способ:
$cur_url = 'item2.htm';
if ($url != 'item1.htm')
$menu = '<a href="item1.htm">item1</a><br />';
else
$menu = '<span>item1</span><br />';
if ($url != 'item2.htm')
$menu .= '<a href="item2.htm">item2</a><br />';
else
$menu .= '<span>item2</span><br />';
if ($url != 'item3.htm')
$menu .= '<a href="item3.htm">item3</a><br />';
else
$menu .= '<span>item3</span><br />';
if ($url != 'item4.htm')
$menu .= '<a href="item4.htm">item4</a><br />';
else
$menu .= '<span>item4</span><br />';
if ($url != 'item5.htm')
$menu .= '<a href="item5.htm">item5</a>';
else
$menu .= '<span>item5</span>';
Он еще более громоздкий, да еще и избыточный. Хотя данный способ в полтора раза быстрее первого, в подобной ситуации я отдаю предпочтение использованию preg_replace.
PHP и timestamp
На мой взгляд, функции time(), mktime(), date(), gmmktime(), gmdate() недостаточно хорошо описаны в документации. Легко запутаться при попытках понять, что же происходит в разных часовых поясах. Вот доходчивое объяснение (правда, на английском). Вкратце его суть в следующем. Метка времени (timestamp) фиксированного момента одна и та же для всех часовых поясов. Функции date() и mktime() преобразуют timestamp ко времени в часовом поясе, установленном на сервере, и обратно. Функции gmdate() и gmmktime() делают то же самое, но только для гринвичского времени.
PHP: mkdir
Сегодня потратил немало времени в попытках понять, почему права у директории dir после выполнения функции mkdir('dir', 0777); не выставляются в 777. А ведь в документации написано:
На аргумент mode также влияет текущее значение umask, которое можно изменить при помощи umask().
Тема umask осталась нераскрытой. В общем, про второй параметр у функции mkdir() можно забыть, а правильный код выглядит так:
mkdir('dir');
chmod('dir', 0777);