Тесты выявляют проблемы не только с вашим кодом
Удивительные тесты
Представьте, что вы пришли на новый проект и обнаружили в нем вот такой тест:
<?php
use Codeception\Test\Unit;
class MyTest extends Unit
{
public function testHash(): void
{
$this->assertEquals('098f6bcd4621d373cade4e832627b4f6', md5('test'));
}
}
Для неспециалистов поясню, что этот тест вызывает встроенную в PHP функцию md5(), передает ей аргумент 'test' и проверяет, что она возвращает указанное значение.
Зачем нужен этот тест, если встроенная функция и так вычисляет хеш по известному задокументированному алгоритму? Мы же пишем тесты на наш проект, а не на интерпретатор PHP. Написавший этот тест коллега на вопросы отвечает так:
— В наших алгоритмах мы полагаемся на значения хешей, сохраненные в базе данных. Если вдруг функция начнет возвращать другие значения в будущих версиях PHP, мы заметим это по упавшему тесту. Конечно, такие изменения нарушают обратную совместимость, и они должны быть написаны в информации о релизе PHP. Но их можно просмотреть
Как считаете, писать в проекте тест на встроенную функцию PHP — это паранойя? Или разумная предусмотрительность? А что, если это не встроенная функция в PHP, а сторонняя библиотека? Правда же, такой тест вызывает меньше удивления:
<?php
use Codeception\Test\Unit;
use SuperVendor\SuperHashLib\SuperHash;
class MyTest extends Unit
{
public function testHash(): void
{
$this->assertEquals('098f6bcd4621d373cade4e832627b4f6', SuperHash::getHash('test'));
}
}
Тест выявил изменение поведения при обновлении PHP
В моей практике похожий тест действительно однажды помог отследить вредный побочный эффект от нарушения обратной совместимости при обновлении PHP. Минимальный пример для воспроизведения такой:
<?php
class A
{
public $prop1 = '1';
public $prop2 = '2';
public function getHash(): string
{
return md5(serialize($this->normalize()));
}
public function normalize(): array
{
return get_object_vars($this);
}
}
class B extends A
{
public $prop3 = '3';
}
$a = new A;
var_dump($a->getHash());
$b = new B;
var_dump($b->getHash());
Этот код в старых версиях PHP до 8.1 выводит следущее:
string(32) "e5f8d9c52536e3412aa273c7bd4c9dbb"
string(32) "46d9b1133eec8d47fe6e00e970cf0a77"А начиная с 8.1 значение хеша у объекта класса B изменилось:
string(32) "e5f8d9c52536e3412aa273c7bd4c9dbb"
string(32) "8275b764cf277cbbd3b00b1e86d8a4eb"Причина различий в изменении порядка свойств в массиве, возвращаемом get_object_vars(). В старых версиях сначала шли свойства самого класса, а затем унаследованные от родительского:
// До PHP 8.1
Array
(
[prop3] => 3
[prop1] => 1
[prop2] => 2
)В новых же версиях сначала идут унаследованные свойства, а потом собственные свойства класса:
// PHP 8.1 и старше
Array
(
[prop1] => 1
[prop2] => 2
[prop3] => 3
)Как видите, такое изменение поведения при обновлении PHP меняет значения хешей, вычисляемые очевидным и прямолинейным способом. И это изменение даже не было заявлено в информации о релизе как ломающее обратную совместимость!
Мы смогли отловить проблему как раз благодаря тесту, в котором проверялось точное значение вычисленного хеша. Правда, он был написан с другой целью. В нашем случае при добавлении новых полей мы исключали их из вычисления хеша, чтобы хеш не менялся, если новые поля не используются:
<?php
class A
{
public $prop1 = '1';
public $prop2 = '2';
public $propN = null;
public function getHash(): string
{
return md5(serialize($this->normalize()));
}
private function normalize(): array
{
$data = get_object_vars($this);
if ($this->propN === null) {
unset($data['propN']);
}
return $data;
}
}Чтобы разработчики не забывали добавлять unset() новых
Пример решения проблем с обратной совместимостью алгоритмов хеширования
Чтобы дважды не вставать и рассказать не только о проблеме, но и о том, как ее решать, рассмотрим пример, в котором требуется подход с get_object_vars() и вычислением хешей.
Предположим, вы разрабатываете сервис для отслеживания цен на товары в
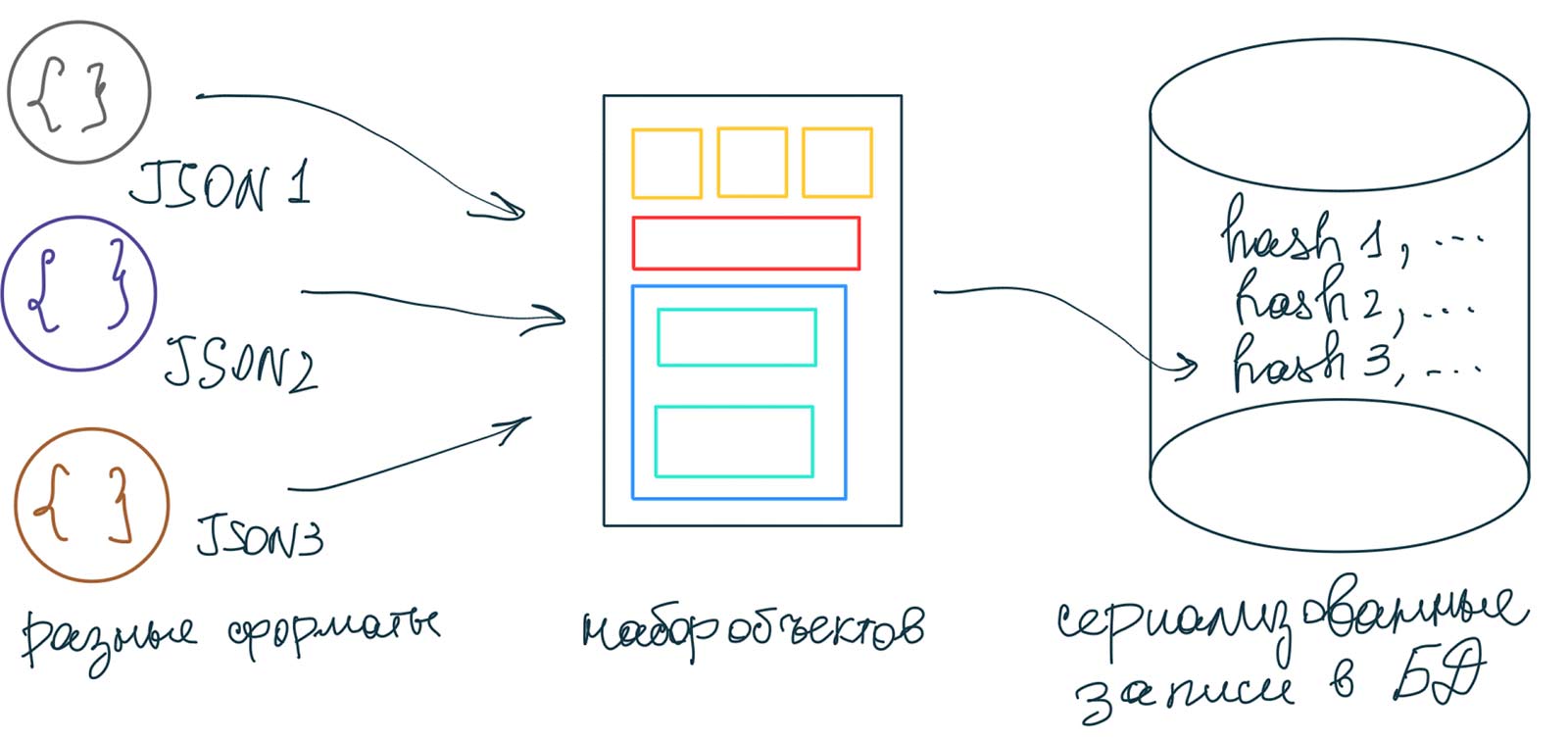
На входе у вас множество источников данных из разных products:
| id | hash | data |
|---|---|---|
| 1001 | e5f8d9c52… | {"color":"red"…} |
| 1002 | 8275b764c… | {"color":"green"…} |
После этого для записи истории цен достаточно вести таблицу price_history:
| product_id | date | price |
|---|---|---|
| 1001 | 1099,9 | |
| 1001 | 1199,9 |
Если в источниках данных появляется новый товар или новая модификация известного товара, метод getHash() вернет неизвестное ранее значение, и в таблицу products добавится новая запись. Если товар ранее уже встречался, значение getHash() уже будет присутствовать в таблице products, и значение для product_id берется из соответствующей записи.
Теперь мы видим, к каким последствиям может привести изменение в алгоритме вычисления хешей. product_id. Вы потратите много времени и сил, пытаясь сначала найти причину проблем, а потом исправлять данные в БД, изменяя идентификаторы и подчищая дубликаты.
Как же решать проблему с изменением алгоритма хеширования? Примерно так же, как изменяется тип колонок в огромных таблицах БД. Для начала напишем новый метод вычисления хеша, инвариантный относительно изменения порядка свойств:
public function getHash2(): string
{
$data = $this->normalize();
ksort($data);
return md5(serialize($data));
}
Далее делаем в таблице БД новую колонку со значением нового хеша. При поиске записей в этой таблице по хешу нужно сначала искать по новой версии хеша, а затем, если ничего не нашли, по старой версии. При добавлении новых записей пока будем записывать значения и новой колонки, и старой. Старые значения хеша всё еще требуются для возможного отката.
После успешной выкладки, если откат не нужен, надо обновить значения новой колонки у старых записей. Это сделает отдельный скрипт, который прочитает все записи, переведет данные в объекты, по объектам посчитает новую версию хешей и выполнит UPDATE.
В завершение можно выкладывать окончательную версию кода, в которой останется только новая версия алгоритма хеширования, и запускать миграцию, которая удалит колонку со старыми версиями хешей.
Вывод
Обычно, когда программист пишет тесты к разрабатываемому приложению, он ориентируется на выполняемые приложением функции. В нашем примере приложение собирает цены из нескольких источников и выводит на странице. Тогда и в тесте сначала импортируется несколько файлов с данными, а затем проверяется, что эти данные выводятся корректно. Это будет означать, что вся цепочка преобразования данных отработала правильно.
Кроме функций приложения, нужно задуматься еще о том, какие предположения делаются в ходе разработки. И эти предположения тоже можно проверять в тестах. Мы разобрали один из примеров, когда предполагалось, что одинаковые данные на входе дадут одинаковые значения хешей. Если забыть о неявном требовании, что хеши не должны меняться со временем (на практике они ведь сравниваются с записанными ранее значениями в БД!), легко написать тесты на саму функцию, которые не упадут при изменении алгоритма хеширования. И вы отправите проблемные изменения в рабочую систему, будучи уверенными, что всё в порядке, так как тесты пройдены.
Оставьте свой комментарий