Избранное
Как разработать систему рекомендаций ★
Продолжим разговор о системе рекомендаций в S2. Эта система подбирает к каждой заметке набор других заметок, которые посетитель может почитать дальше. В прошлый раз я рассказал об этой системе в целом, сейчас же опишу алгоритм подбора самих рекомендаций.
За рекомендации в моем случае отвечает движок полнотекстового поиска Rose. Структура данных в полнотекстовом индексе как раз подходит для задачи подбора похожих заметок. Если совсем упростить, то получается, что обычный поиск — это подбор подходящих заметок к словам из поискового запроса, а рекомендации к заметке — это подбор других заметок по словам из нее. А теперь давайте погрузимся в детали.
Теория рекомендаций
Для начала давайте поймем, как вообще могут работать системы рекомендаций. Рассуждать будем на примере существовавшего
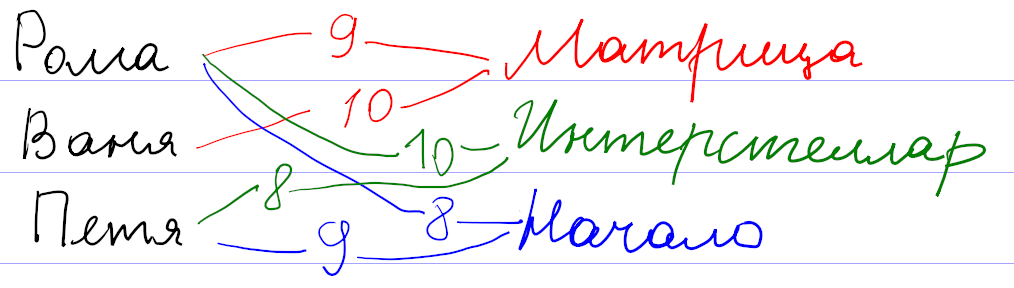
Оценки пользователей сохраняются как веса связи
Математика позволяет предложить более формальный и универсальный подход. Будем рассматривать оценки к фильмам как координаты некоторой точки во многомерном пространстве всех фильмов. Тогда всех пользователей можно представить как множество точек в таком пространстве. При достаточном количестве они начнут группироваться в кластеры по разным предпочтениям. После этого задача подбора рекомендаций сведется к поиску соответствующего кластера.
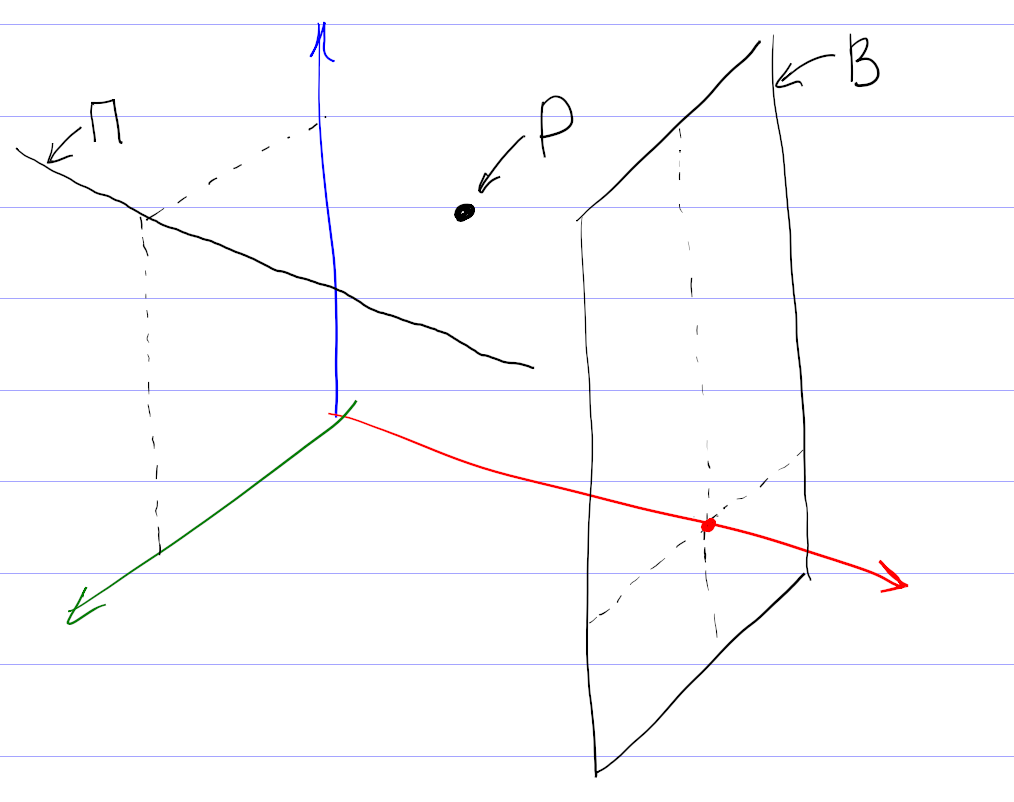
На самом деле, картина сложнее, так как никто не может поставить оценки всем фильмам. Поэтому вместо точек мы имеем дело с некоторыми подпространствами (прямыми, плоскостями и т. д.). Чтобы сформировать мои рекомендации, система проецирует все оценки на подпространство просмотренных мной фильмов, находит кластер в проекции, и по нему уже пытается восстановить кластер в полном пространстве.
Понятно, что процедура восстановления кластера из проекции неоднозначна, и в этом месте система рекомендаций может ошибаться, даже если в ней собраны оценки большого количества пользователей. Например, по оценкам фильмов, единогласно оцениваемых зрителями, нельзя восстановить предполагаемую оценку и однозначно рекомендовать фильм, мнения по которому разделились на два равновеликих полюса.
Эта теория прекрасно выглядит на листе бумаги. Но я уверен, что при практической реализации разработчики столкнулись с кучей проблем. Очевидная проблема — нормировка оценок. Например, у меня средняя оценка была около 7. Оценки меньше 4 я практически не ставил. Задумывался над тем, чем отличается оценка 9 от 10. Оценки других пользователей наверняка отличались по характеристикам.
Вы наверняка встречались с другим примером системы рекомендаций: поиском друзей в соцсетях. Здесь тоже работает связь
Теперь давайте посмотрим, как можно эти знания применить для подбора рекомендаций заметок.
Рекомендации на основе тегов
Как видно из предыдущего рассмотрения, систему рекомендаций можно сделать везде, где есть связь
Недостатки подхода лежат на поверхности.
Рекомендации на основе похожих текстов
В движке S2 есть другая связь
| word_id | toc_id | positions |
|---|---|---|
| 1 | 1 | 0,37 |
| 3 | 4 | 0,15,74,193,614 |
| 3 | 8 | 94 |
| 3 | 9 | 73 |
| 4 | 1 | 3,16,57 |
| … |
В первой колонке хранится id «слова», во второй — внутренний id проиндексированного элемента (ToC — это сокращение от table of contents), в третьей — положения соответствующего слова в проиндексированном тексте.
При индексации исходный текст заметок очищается от
При поиске запрос преобразуется по такой же схеме: слова заменяются на идентификаторы word_id, и из поискового индекса мы получаем информацию о том, в каких проиндексированных текстах (toc_id) встречались эти слова. Положения слов (positions) нужны для вычисления релевантности: чем ближе слова из запроса друг к другу в тексте, тем выше окажется этот текст в выдаче.
Рекомендации на основе близости текста тоже используют эту таблицу. У меня получилось уместить все существенные вычисления в один
SELECT
relevance_info.*, -- информация из подзапроса
m.images, -- добавляем к ней информацию о картинках
t.*, -- добавляем к ней оглавление
-- и первые 2 предложения из текста
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1) AS snippet,
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1 OFFSET 1) AS snippet2
FROM (
SELECT -- Перебираем все возможные заметки и вычисляем релевантность каждой для подбора рекомендаций
i.toc_id,
round(sum(
original_repeat + -- доп. 1 за каждый повтор слова в оригинальной заметке
exp( - abn/30.0 ) -- понижение веса у распространенных слов
* (1 + length(positions) - length(replace(positions, ',', ''))) -- повышение при повторе в рекомендуемой заметке, конструкция тождественна count(explode(',', positions))
) * pow(m.word_count, -0.5), 3) AS relevance, -- тут нормировка на корень из размера рекомендуемой заметки. Не знаю, почему именно корень, но так работает хорошо.
m.word_count
FROM fulltext_index AS i
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) ON m.toc_id = i.toc_id
JOIN (
SELECT -- достаем информацию по словам из оригинальной заметки
word_id,
toc_id,
(SELECT count(*) FROM fulltext_index WHERE word_id = x.word_id) AS abn, -- распространенность текущего слова по всем заметкам
length(positions) - length(replace(positions, ',', '')) AS original_repeat -- сколько раз слово повторяется в оригинальной заметке. Выше используется как доп. важность
FROM fulltext_index AS x FORCE INDEX FOR JOIN(toc_id)
JOIN toc AS t ON t.id = x.toc_id
WHERE t.external_id = :external_id AND t.instance_id = :instance_id
AND length(positions) - length(replace(positions, ',', '')) < 200 -- отсекаем слишком частые слова. Хотя 200 слишком завышенный порог, чтобы на что-то влиять
HAVING abn < 100 -- если слово встречается более чем в 100 заметках, выкидываем его, так как слишком частое. Помогает с производительностью
) AS original_info ON original_info.word_id = i.word_id AND original_info.toc_id <> i.toc_id
GROUP BY 1
HAVING count(*) >= :min_word_count -- количество общих слов, иначе отбрасываем
) AS relevance_info
JOIN toc AS t FORCE INDEX FOR JOIN(PRIMARY) on t.id = relevance_info.toc_id
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) on m.toc_id = t.id
ORDER BY relevance DESC
LIMIT :limitОпишу ключевые шаги, которые здесь выполняются.
1. Взять все слова в заметке, к которой подбираем рекомендации. Я называю эту заметку оригинальной. Выбор слов происходит в самом внутреннем подзапросе.
2. Выкинуть распространенные слова. Это нужно делать для повышения точности и при поиске, и при подборе рекомендаций. Можно даже составить список игнорируемых слов вроде союзов или предлогов. Но вместо составления такого неизменяемого списка я вычисляю распространенность (abundance, сокращенно abn — количество заметок, в которых встречается это слово) для каждого слова в индексе. Например, в блоге о дизайне в каждой заметке будет слово «дизайн», и его тоже надо игнорировать.
Слова с распространенностью больше 100 наверняка окажутся слишком общими, и я отбрасываю их по соображениям производительности. Скорее всего порог должен
3. Найти одинаковые слова у оригинальной заметки с остальными заметками. Это происходит в промежуточном подзапросе. У заметок при этом должно быть достаточное количество общих слов (порог определяется параметром min_word_count).
Я пробовал разные значения параметра. Если увеличивать, количество рекомендаций падает. Если уменьшать, в рекомендации попадают не очень подходящие заметки за счет случайного использования общих слов. Я остановился на варианте, когда запрос сначала выполняется со значением 4. Если результатов нет, как это часто бывает у коротких заметок, то запрос повторяется со значением параметра 2.
4. По повторяющимся словам вычислить релевантность. Это тоже происходит в промежуточном подзапросе в выражении в селекте благодаря group by. Релевантность я вычисляю как количество повторений общих слов. Чтобы понизить влияние распространенных слов, я добавил ослабление за счет веса exp(-abn/30.0). Хотел было использовать колоколообразную функцию типа exp(-sqr(abn/30.0)), но на практике линейное уменьшение веса при малых значениях распространенности повысило качество рекомендаций.
Кроме того, повторы в оригинальной заметке (original_repeat) и в рекомендуемых заметках влияют на релевантность несимметрично: повторяющиеся слова в оригинальной заметке не ослабляются, даже если они распространены. Объяснение можно предложить такое: если автор пишет одинаково часто о шахматах и шашках, то к оригинальной заметке с пятью словами «шахматы» и одним словом «шашки» лучше рекомендовать заметку с одним словом «шахматы», чем с пятью словами «шашки». Эффект несимметричности я не закладывал специально. Практика показала, что отсутствие ослабления у original_repeat субъективно улучшает качество рекомендаций.
Несимметричность веса оригинальной заметки и рекомендуемых может быть даже полезной, чтобы избежать «зацикливания» рекомендаций, когда к заметке А мы рекомендуем заметку Б, а к заметке Б — заметку А. Правда, у меня этот критерий не был обязательным, и я не проверял, как он выполняется. Применительно к моему сайту эффект зацикливания может ослабляться ещё и за счет последующего предпочтения в рекомендациях заметок с картинками.
Последний множитель в релевантности pow(m.word_count, -0.5) учитывает размер рекомендуемой заметки в словах. Без него в моем случае среди рекомендуемых оказывались очень длинные заметки, набиравшие релевантность за счет большого количества повторяющихся слов средней распространенности. Тогда я подумал, что сортировать рекомендации нужно не по абсолютному количеству общих слов, а по относительному, то есть надо поделить вычисленную релевантность на количество слов в рекомендуемой заметке. В рекомендации стали попадать короткие заметки всего из нескольких слов, а у нормальных заметок из нескольких сотен слов релевантность сильно просела. Чтобы было ни нашим ни вашим, я попробовал поделить абсолютную релевантность на корень из длины рекомендуемой заметки, и это сработало: с первых мест рекомендаций ушли как очень короткие, так и очень длинные заметки. Изменение показателя степени −0,5 в обе стороны приводило к некоторому повышению ранга одних и понижению ранга других таких нерелевантных заметок.
У меня не было объяснения, почему нормировка релевантности именно на корень из длины оказалась подходящей. Но в момент набора этого текста появилась гипотеза. Нормировка на длину рекомендуемых заметок не учитывает длину оригинальной заметки. Но для подбора рекомендаций к одной оригинальной заметке ее длина ни на что не влияет. Возможно, что для более общей задачи подбора рекомендаций к N оригинальным заметкам релевантность нужно нормировать на среднее геометрическое из длин оригинальной и рекомендуемой заметок. Тогда для одной оригинальной заметки ее длина превратится в несущественный постоянный коэффициент и уйдет за скобки, а длина рекомендуемой заметки как раз окажется в знаменателе под корнем.
5. Получить заголовок, картинки и фрагмент текста. Это неинтересная техническая задача, решаемая во внешней части запроса. Для «сниппетов» — коротких фрагментов текста — я достаю первые два предложения из заметок. Сначала думал выводить те предложения из текста, которые содержат общие слова. Зависимость сниппетов от контекста как раз бы показала, почему рекомендуется именно эта заметка. Но
Вопросы производительности
В запросе вы видите явное указание использовать конкретные индексы. Без них планировщик не использовал часть индексов. Почему он так решал — непонятно. За счет расстановки хинтов я оптимизировал запрос раз в 20 до нескольких десятков миллисекунд. Я последние 6 лет работаю с PostgreSQL, и он даже думать отучил, что в запросы можно добавить хинты. Но тут пришлось.
Производительность в несколько десятков миллисекунд я посчитал достаточной, чтобы выполнять
При работе на настоящем сервере выяснилось, что в режиме невысокой нагрузки база данных может иногда выполнять запрос существенно дольше — несколько сот миллисекунд или даже больше секунды. Вот данные мониторинга по средней длительности запроса:
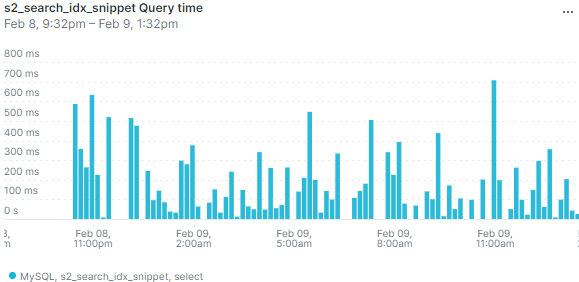
Выбросы на графике означают, что иногда пользователи будут замечать, что страница долго открывается. И изредка приходящий
Я добавил кеширование подбора рекомендаций. Кеш инвалидируется не по времени, а по обновлению заметок. Правда, мне пришлось инвалидировать весь кеш рекомендаций при любом изменении опубликованных заметок. Действительно, изменение хотя бы одного слова в
Кеш хорошо решает проблему с редкими выбросами, даже если заметки часто обновляются. Если в кеше есть устаревшие рекомендации, всё равно выводятся они, а в фоне в это время просчитываются новые рекомендации.
Я так и не понял, почему возникают такие всплески времени выполнения запроса. Не думаю, что конкуренция MySQL за процессорное время с PHP или Похоже, проблема связана с нагрузкой на гипервизор от соседних виртуальных машин.
Направления развития
- Убрать из запроса захардкоженные числа.
- [✓] Если рекомендаций с четырьмя общими словами нет, делать повторный запрос с ослабленным ограничением. А вообще тут важно найти баланс: надо ли показывать неподходящие рекомендации, если нет подходящих?
- Получать сниппеты из релевантных предложений, а не первых двух.
Дополнение о нормальной форме
Внимательный читатель отметил, что таблица полнотекстового индекса не находится даже в первой нормальной форме: в одной ячейке positions через запятую перечислен список положений слова. Что хорошо в теории, не всегда хорошо в настоящем работающем софте. Раньше действительно структура этой таблицы была другой, и каждый элемент из positions располагался на своей строке. Для корректной работы алгоритма мне нужно было обеспечить уникальность строк, поэтому элементы (word_id, toc_id, position) я еще добавил в уникальный индекс.
Достаточно быстро в целях оптимизации я отказался от индекса по word_id и повесил первичный ключ сразу на все колонки (word_id, toc_id, position). В этом есть смысл, так как первичный индекс в InnoDB кластерный, то есть данные строк хранятся на диске вместе с первичным индексом.
Сейчас я пошел в оптимизации дальше и отказался от нормальной формы для хранения положений. Базы данных устроены так, что в таблицах в каждой строке хранится дополнительная служебная информация. Объединение нескольких строк с одинаковыми word_id и toc_id в одну дало экономию места в полтора раза (поисковый индекс в целом уменьшился с 22 до 14 мегабайт при суммарном объеме заметок 2,8 мегабайт). Кроме того, скорость индексации тоже выросла примерно в полтора раза, так как сократилось количество выполняемых запросов. Я не обнаружил
Понятно, что отказ от нормальной формы — не универсальное решение. Так, в рассматриваемом примере пропала возможность фильтрации по полю position. Для задач поиска в этом ничего страшного нет, так как в них фильтрация по position не встречается. Хотя по большому счету мало что изменилось: фильтрацию всё еще можно делать через операции с поиском подстроки, и это не будет сильно медленнее, потому что и раньше по полю position отдельного индекса не было.
Головоломка Арнольда ★
Постоянные читатели помнят, что мы с коллегами по учебе лет 10 назад занимались задачей Арнольда. В ней остались открытые вопросы, и я недавно решил к ним вернуться. Дописал одну из программ, отрисовывающих и распрямляющих конфигурации, и понял, что получилась хорошая игровая механика для головоломки. Переписал код визуализации и моделирования на js, и получилась браузерная головоломка.
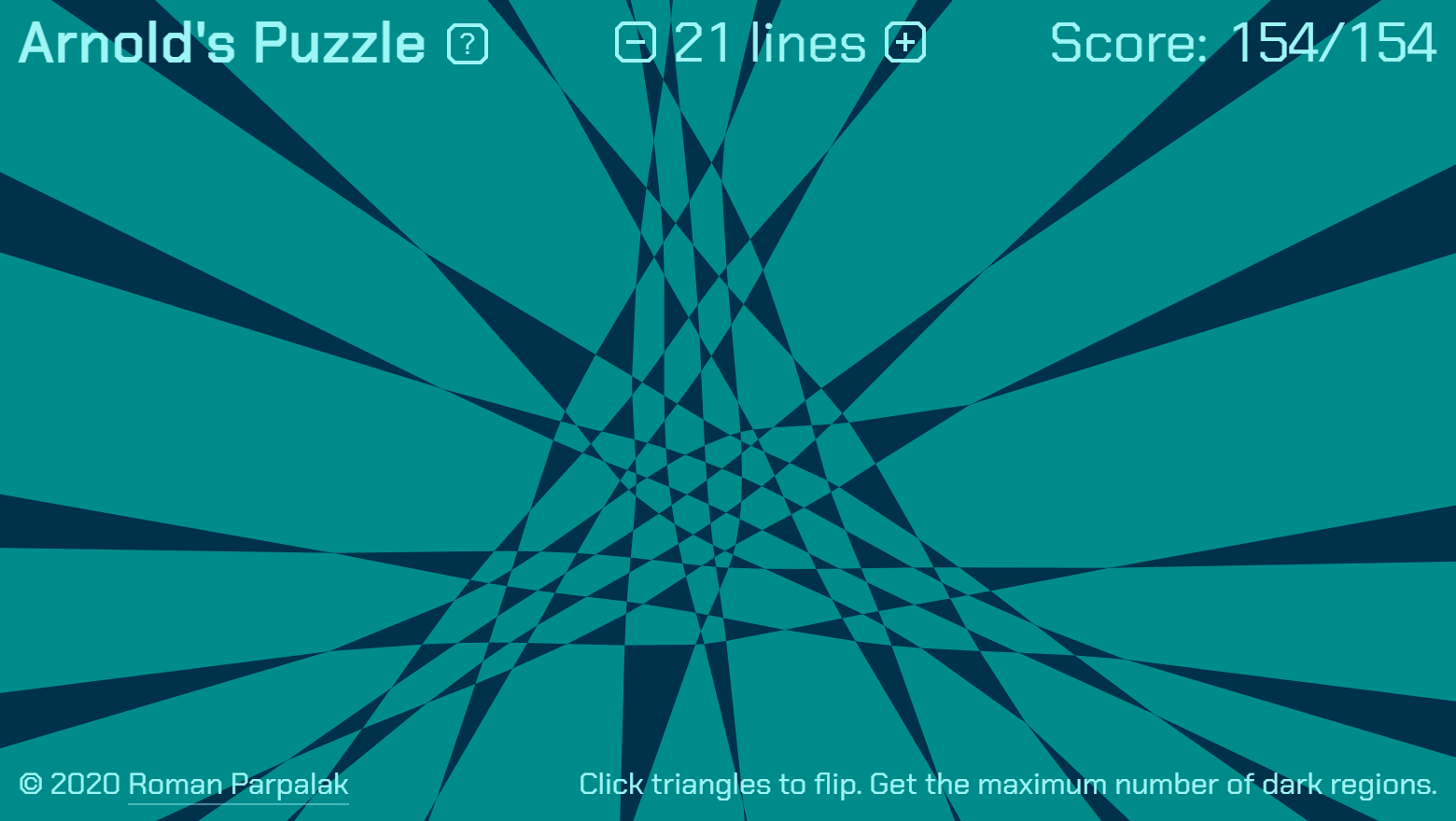
Правила
В этой игре выполняются простые правила:
- На плоскости проведены несколько линий, каждая пара линий пересекается в одной точке.
- Линии разбивают плоскость на области, раскрашенные в шахматном порядке.
- Вы можете перестраивать разбиение, «схлопывая» и «выворачивая» треугольники.
- Ваша цель — получить максимально возможное количество темных областей.
В простейшем случае 5 линий процесс игры выглядит так:

Пользовательский опыт
При небольшом количестве линий решить головоломку можно случайным перебором. Нужно помнить, что иногда надо «пожертвовать» счетом (количеством темных областей), так как не всегда есть «прямая дорога» к цели, на которой счет только увеличивается.
Я довольно быстро «прошел» все уровни до 19 линий. 21 линию (на скриншоте в начале) собрал часа за полтора. Правда, я знал, что существует
С увеличением уровня сложность игры растет не только количественно (нужно дольше идти к цели), но и качественно: приходится придумывать новые приемы и подходы, так как старых становится недостаточно.
По ощущениям игра похожа на паззл, каждый кусочек которого подходит к любому другому кусочку, но общая картина из них всё никак не складывается.
Игра полностью отвлекает от происходящего вокруг, подходит для убивания времени в метро.
Математическая основа
Напомню формулировку задачи Арнольда:
На плоскости проведены N прямых. Найти максимальную разность между числом черных и белых областей шахматной раскраски дополнения.
Это открытая математическая проблема. Она является частным случаем
Таким образом, переворачивая треугольники в головоломке, вы на самом деле решаете в частном случае
Для преобразования конфигураций в головоломке именно схлопывание треугольников выбрано не случайно. Оказывается, с помощью таких схлопываний можно перевести произвольную конфигурацию в любую другую конфигурацию. Действительно, линии на плоскости, описанные в правилах, называются конфигурацией (псевдо)прямых. Они представляют элемент из группы кос. Суть теоремы Артина об образующих группы кос как раз и состоит в возможности перевода конфигураций друг в друга последовательностью преобразований треугольников.
Также задача Арнольда тесно связана с задачей о треугольниках Кобона.
Вместе со мной Денис Уткин и Сергей Белёв потратили немало времени на попытки решения, результаты которого есть во многостраничном
Вычислительная модель игры
В основе визуализации — математическое моделирование некоторой «механической» системы. В этой системе массивные точки соединены ломаными линиями, отталкиваются друг от друга, испытывают сопротивление среды. В узлах ломаных — распрямляющие «пружинки». Концы ломаных прибиты внешними зафиксированными точками. Для расчетов движения точек по законам механики применяется метод Рунге — Кутты четвертого порядка с оценкой ошибок и плавающим шагом. Преподаватели вычматов были бы довольны :) Код, как обычно, открыт на гитхабе.
Серебристые облака — 4 ★
Прошлой ночью опять наблюдал серебристые облака.

Попробовал заснять облака на видео. Получилось не очень впечатляюще. Вот ускоренная в 4 раза запись.
Если получится, в следующий раз попробую снять много кадров подряд, с выдержкой побольше и равномерными интервалами, и склеить из них видео.
Фортепиано ★
Позавчера улетел из Кишинева. В зале вылета опять поставили рояль. Не очень хотелось кому попало давать мобильник для съемки ролика. Вместо этого записал игру на своем инструменте. Это хорошо известная композиция:
А это новая композиция. С помарками, но зато сейчас, а не еще через три года:
Клиент хочет копировать эксель-таблицы на сайт
★
Попробуем новый для этого блога формат советов.
Клиент хочет копировать отформатированные таблицы из Экселя в визуальный редактор на сайте, чтобы ничего не менялось. Мы разработали сайт на базе Вордпресса, и в нем это не получается, форматирование не сохраняется. Возможно ли в принципе то, что хочет клиент? Если нет, то как это красиво и обоснованно ему объяснить?
Вот тут пишут, что можно настроить визуальный редактор Вордпресса TinyMCE. Правда, в комментариях отмечают, что это зависит от версии Экселя, так что решение может быть не универсальным.
Как применить это решение в вашем конкретном случае — не знаю. Возможно, поможет плагин
Вообще я бы запрещал любое форматирование, кроме курсива и жирного текста. Если клиент просит возможность копировать фрагменты таблицы из Экселя с форматированием, надо выяснять, какую задачу клиент будет решать таким способом.
Возможный выход — договориться о разработке дополнительной функциональности по загрузке
В варианте с копированием из Экселя больше неконтролируемых звеньев, в которых
Последовательная загрузка торрентов ★
Самая важная функция торрентов, помимо собственно файлообмена, — это последовательное скачивание файлов.
В процессе обмена
Порядок загрузки не имеет значения, если вы скачиваете фильм на медленном соединении. Или программу. Или образ диска операционной системы. Но если у вас быстрый интернет, и двухчасовой фильм скачается за час, не получится ли загружать фрагменты фильма последовательно и сразу отправлять их в плеер? Тогда начинать просмотр можно сразу, не дожидаясь полной загрузки файла.
Пионер технологии uTorrent
Впервые подобная функция под названием streaming появилась в uTorrent версии 3.0. Он скачивал подряд несколько первых фрагментов и умел отдавать их через встроенный сервер потокового видео. Просматривать это потоковое видео можно было через плеер VLC. По мере просмотра зона последовательной предзагрузки продвигалась вперед, чтобы обеспечить систему достаточным для воспроизведения набором данных.
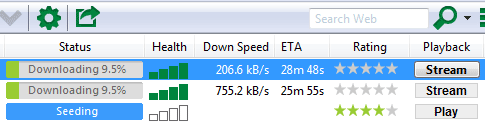
Интуиция подсказывает, что сложная схема с участием торрентокачалки, встроенного в нее сервера потокового видео и плеера VLC может заработать не так, как ожидается. И практика эти опасения подтверждает.
Увеличение области предзагрузки означало и увеличение времени ожидания перед началом просмотра.
Потом я сообразил, что можно запустить два плеера одновременно: VLC на большой скорости без звука, чтобы обеспечить последовательную загрузку данных, и обычный плеер с незавершенным файлом. И, наконец, я выставил в параметрах
Итоговая схема:
- запускаешь торрент на скачивание;
- нажимаешь на кнопку «Поток»;
- открываешь файл в обычном плеере.
На втором шаге, благодаря завышенному размеру области предзагрузки, VLC никогда не запускался, а файл загружался последовательно. На самом деле схема чуть сложнее, потому что
Я использовал такую схему несколько лет. Но в прошлом году вышла версия
Нормальная реализация в qBittorrent
Некоторое время я использовал предыдущую версию с выключенными обновлениями. Но, настраивая новый ноутбук, я подумал, что пляски с бубном вокруг
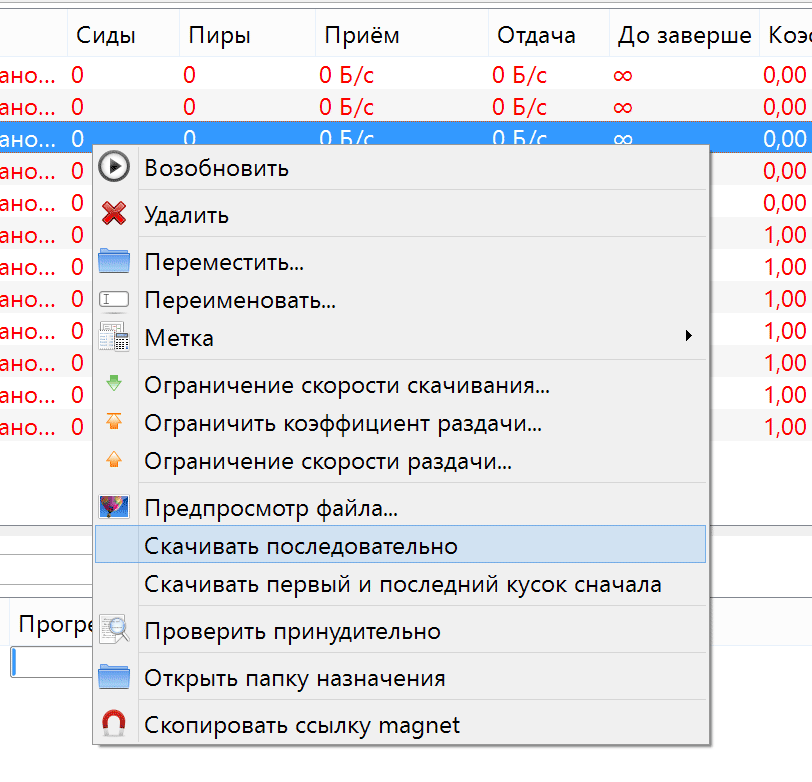
При последовательной загрузке торрентов не надо ждать окончания загрузки фильмов, если у вас быстрый интернет и если на торренте несколько сидов. Когда торрент раздается одним сидом (сразу после публикации), скорость загрузки определяется его исходящим каналом, и последовательное скачивание не поможет быстро начать смотреть видео.
А как вы скачиваете фильмы? Используете последовательную загрузку? Будете ли использовать?
Непослушные программы ★
Иногда в отношениях между людьми оказывается полезным следующий принцип: «Не делай того, о чем тебя не просили». Его нужно применять и к разработке программного обеспечения. Чтобы пояснить эту мысль, расскажу историю.
Однажды я отправился на деловую встречу. Вышел из метро, осмотрелся, достал телефон, чтобы уточнить место встречи. Нужного номера в списке не оказалось. Я был абсолютно уверен в том, что номер там должен быть, так что у меня даже не возникло мысли заранее его проверять. Поиск по контактам телефона не помог. Я залез в электронную почту, но в письмах номера тоже не было. Чтобы выйти из этой ситуации, пришлось позвонить общему знакомому.
Как оказалось, «умный» Андроид без спросу синхронизировал контакты в телефоне и в почте. В ходе этого процесса он объединил номер телефона и
Безусловно, программное обеспечение должно быть самостоятельным. Не надо останавливать работу и ожидать очевидный ответ пользователя. Например, программа WinSCP выдает следующее предупреждение, когда я нажимаю кнопку «открыть терминал»:
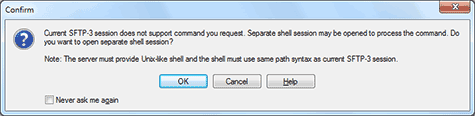
Она сообщает, что придется открыть еще одно соединение с сервером, и спрашивает, согласен ли я. Разумеется, я согласен на всё что угодно, чтобы окно терминала
Однако программы не должны выполнять
С этой точки зрения система обновления Хрома, когда в системе оказываются постоянно запущенными процессы, незаметно скачивающие новые версии, вообще находится за пределами добра и зла. Но даже такие драконовские меры поддержки актуального состояния браузера не являются абсолютно эффективными. Обновления применяются только при перезапуске браузера. Если мой браузер запущен неделями, незачем скачивать обновления пять раз в день.
Чурофметика ★
Слушатели Эха Москвы помнят недавнее интервью Чурова, в котором он опровергает математику:
Чуров совершенно правильно назвал свою аналогию с конфетками наперсточничеством. Я собираюсь показать это, предложив адекватную аналогию.
Статистический анализ результатов выборов никакого отношения к нескольким конфеткам не имеет. Чтобы правильно показать его суть, нужно представить следующую ситуацию.
Наш герой отправляется в каждый магазин известной торговой сети и покупает несколько упаковок
Известно, что в одну упаковку в силу ограниченности объема можно поместить не больше 100 конфет. Но так как конфеты до упора никто не набивает, разумно ожидать, что в среднем
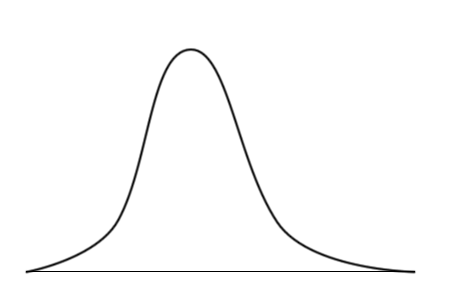
Как же удивляется исследователь, обнаружив нечто совершенно неожиданное!
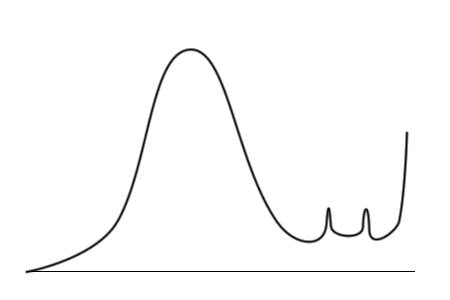
Здесь примечательны три вещи.
Тогда исследователь строит гистограммы, откладывая по вертикали не число упаковок, а уже общее число конфет разных цветов в упаковках с данным количеством конфет.
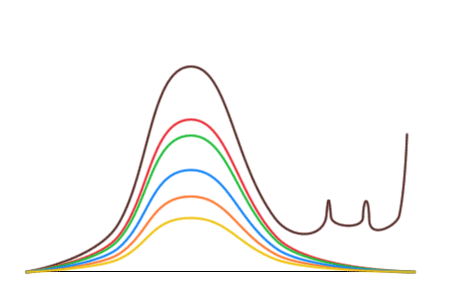
Оказывается, что безобразие действительно происходит только с коричневыми конфетами. Кривые для остальных конфет выглядят нормально и переходят друг в друга при растяжении или сжатии по вертикали. Их симметрия говорит о том, что конфеты ярких цветов в результате фальсификаций не изымаются. Таким образом, фальсификации заключаются только в преимущественном добавлении коричневых конфет.
Однако эти кривые позволяют сделать большее — сказать, сколько коричневых конфет было в упаковках до вброса! Так как левая половина коричневой кривой напоминает остальные, распределение которых не отличается от заводского, то можно растянуть красную кривую, чтобы левые половины красной и коричневой кривой совпали, и заменить искаженную правую часть.
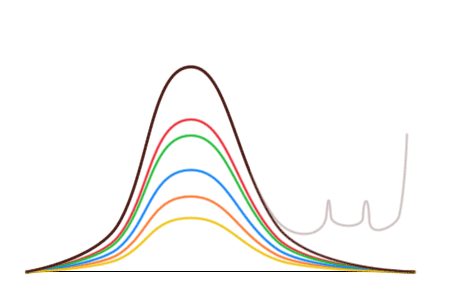
«Это прекрасно, но какое отношение имеют все эти конфеты к выборам и причем здесь Чуров?» — спросит нетерпеливый читатель. Если заменить конфеты разных цветов на проценты за ту или иную партию, а упаковки
Подобный анализ проводился для выборов 2007 — 2009 годов и для последних думских выборов (идея несколько подробнее описана в первом материале). Анализ показывает, например, что на последних выборах Единая Россия получила не 49%, а 34%.
Вот такие, господин Чуров, конфетки!
Универсальная мера всех форм взаимодействия материи ★
В комментариях к одной старой заметке написали следующее:
Универсальная мера всех форм взаимодействия материи?
Это, видимо, пытались найти ответ на вопрос, не нашли и задали его в комментариях. Так вот, я хочу рассказать о своем отношении к таким вопросам.
Я их ненавижу. Это вопрос договоренности и определений. Ответ на него не сообщает о природе ничего. Действительно, только человеку приходит в голову мерить
Моих знаний физики достаточно, чтобы предположить, что правильный ответ — это энергия. Но я не могу гарантировать правильность ответа. Потому что придет
Совершенно
Ни один человек, хоть
Ксилометазолин ★
 Сегодня зашел в аптеку. Нет, за каплями для носа.
Сегодня зашел в аптеку. Нет, за каплями для носа.
— У вас есть ксилометазолин?
Вообще, ксилометазолин — отличные капли, очень помогают переносить насморк. Фармацевт с умным видом нажала кнопки на клавиатуре, посмотрела на монитор и выдала:
— Ксилометазолин — это действующее вещество. Оно может встречаться в разных лекарствах.
Она перечислила четыре совершенно не запоминающихся названия (единственное, что в них мелькало, это буквосочетание «рино») и поинтересовалась, какое же из них мне нужно.
Ее ответ, как и следовало ожидать, сразу же поставил меня в ступор.
Представьте, что вам позарез понадобился знаменитый учебник по русскому языку Д. Э. Розенталя. Вы приходите в библиотеку и видите кучу полок с тысячами всевозможных книг. Вы зовёте библиотекаря, и спрашиваете:
— У вас есть Розенталь?
— Конечно! У нас каждая десятая книга содержит учебник Розенталя.
— Какая удача! Дайте мне его, пожалуйста.
— Какой именно?
— Как какой? Обычный, по которому все учатся!
— Понимаете, у нас все Розентали в разных обложках, разной толщины, разного содержания, многие без подписи или подписаны неправильно.
— Не путайте меня, дайте мне обычный учебник, свежий,3-е издание, серенький.
— Это невозможно, в библиотеке отдельных учебников мало, почти все Розентали входят в сборники. Хотите «Самый Полный Сборник Материалов по Русскому Языку»? У нас их сотни, все очень толстые и разные.
— Бог с вами, давайте. А ктосоставитель-то? Розенталь?
— Нет, некто Вася Пупкин.
— Аааааааааааа!!!
Никогда не думал, что нечто подобное может произойти на самом деле. Но вот, произошло. Чтобы
— А сколько они стоят?
Фармацевт выбрала один из препаратов и сказала, что он стоит 162 рубля, а остальные — дешевле. Ее ответ никак мне не помог в принятии решения. Скорее наоборот. Разумеется, я не готов платить за капли для носа 162 рубля. Но мой следующий вопрос попал в точку:
— А галазолин у вас есть?
По моим ощущениям и воспоминаниям галазолин хуже ксилометазолина, но лучше уж галазолин, чем кот в мешке за 162 рубля.
— Есть, но там другое действующее вещество, — со знанием дела сказала фармацевт. — Хотя нет, то же, — добавила она, вернувшись с лекарством. Стоит 34 рубля 90 копеек.

Госэкзамен ★
В эту летнюю сессию мы сдаем государственный экзамен по физике. Как и другие экзамены, он состоит из двух частей: письменной и устной. Вчера был письменный экзамен, а сегодня проходил разбор задач.
Одна из них была такой. Кусочек льда, имеющий форму параллелепипеда размером 10×10×8 сантиметров, плавает в воде с температурой 20 °C. Через 20 минут он переворачивается на 90°. Оценить, через какое время перевернется айсберг размером 500×500×300 метров, если температура моря составляет 5 °C.
Сегодня я был поражен тем, какую работу проделали составители, придумавшие эту задачу. Они взяли кусок льда указанных выше размеров и наблюдали за тем, как он будет таять; проверили, что параллелепипед, тая, примерно сохраняет свою форму; измерили время, через которое этот кусочек переворачивается. Всё это засняли, смонтировали в двухминутный ролик и сегодня показали его нам. С ноутбуком и проектором, как полагается.
Я был поражен, причем весьма приятно. Просто бессмысленно сравнивать с «трудолюбием» и «старательностью» преподавателей физфака Молдавского государственного университета (о которых я писал в заметке об олимпиадах). В общем, мегареспект вам, чуваки!
Еще несколько фактов об экзамене. В одном из вариантов была забавная опечатка: «ядерный ректор».
Для интересующихся замечу, что все задачи я решил правильно, только в одной из них ошибся при переводе времени из минут в года.
Скрип мела ★
Мел, которым пишут по доске, имеет свойство скрипеть. Впрочем, вы должны это знать. Не то, чтобы он всегда скрипит. Но как скрипнет — мало не покажется. В свое время я исследовал это явление. Самое главное условие — мел должен быть достаточно длинным. Таким, какой он бывает в упаковках. Короткие кусочки мела не скрипят. От доски тоже многое зависит. Идеальный вариант — стеклянные матовые доски. Мел нужно держать за один конец, прижав его к доске, чтобы другой конец был свободным. Мел должен быть расположен почти перпендикулярно к поверхности доски, свободный конец можно немного отклонить против направления движения. Достаточно начать передвигать мел, как раздается громкий скрип, приводящий окружающих в замешательство. На других досках результат менее предсказуем, возможно, придется экспериментально подобрать оптимальное давление и угол отклонения. Если доска не «запела», можно попробовать провести описанную процедуру на оконном стекле. Оно при этом не царапается, так как мел мягче стекла. Следует отметить, что нужно не переусердствовать в извлекании звуков, так как мел может поломаться. Получившиеся кусочки слишком короткие, и они не поют.
Вчера мы с другом пришли в аудиторию раньше преподавателя и обнаружили длинный мел. Я сразу же вспомнил вышеописанную забаву и стал извлекать звуки из него. Доска не запела. С оконным стеклом получилось удачнее. В тот момент, когда аудитория была наполнена страшными звуками, приоткрылась дверь и из нее показалась голова нашего преподавателя. Когда он понял, что происходит, произнес:
— А, я думал, тут