Снова на линуксе
Основной операционной системой у меня всё время была Windows. Я пробовал пересесть на Ubuntu в 2010 году, но больше недели продержаться не смог.
Два с половиной года назад я установил на новый рабочий ноутбук Ubuntu. Не то чтобы я испытывал
(Надо сказать, что я попросил на работе ноутбук ThinkPad X1 Yoga с экраном 4K. И экран у него оказался OLED с регулировкой яркости через ШИМ, то есть на пониженной яркости он мерцал на частоте около 200 герц. В интернете были
Главный вывод
Современные операционки можно настроить так, чтобы привычки, формируемые интерфейсом, работали одинаково и в Ubuntu, и в Windows. Например, в Windows я часто пользовался клавиатурным сокращением Win+R для запуска команд типа c:, mspaint, regedit, cmd, calc:
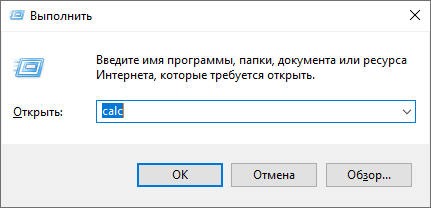
И раньше в Ubuntu я навешивал на Win+R вызов консоли. А сейчас ту же задачу можно выполнить, просто нажав на клавишу Win и начав вводить название программы. Благодаря автодополнению можно ввести только часть названия и нажать Enter, что было невозможно в предыдущем окне.
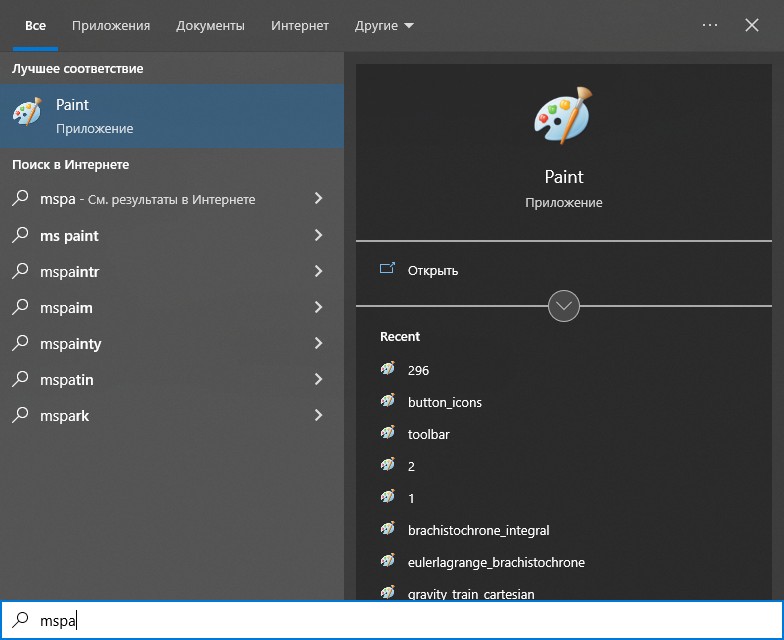
Полностью аналогично работает поиск по меню в Ubuntu, ничего настраивать не надо.
Наблюдения при работе
Для рисования стилусом по экрану я установил программу Stylus Labs (есть версии для всех операционных систем). Очень удобно рисовать схемы, пока объясняешь
PhpStorm работает так же хорошо, как и в Windows. Единственная проблема появляется при подключении внешнего монитора. В момент подключения меняется размер рабочего стола, и
Почтовый клиент Thunderbird в целом неплох. Правда, страдает интеграция с системой и приложениями. Скажем, если дважды кликнуть на прикрепленный экселевский файл, то LibreOffice запустится. Но после загрузки он выдаст ошибку об отсутствующем файле. Каждый раз, когда тебе присылают офисный файл, приходится сохранять
LibreOffice в принципе работает, но не так удобно, как микрософтовский офис. Однажды мне пришлось готовить документ по примеру некоторого вордовского документа. Я закончил и отправил коллегам. У них документ не открылся. У меня он тоже перестал открываться. К счастью, формат docx — это
Особая трудность
Одна из трудностей была связана с приложениями на электроне типа Слака и Скайпа, и переключением языка. Я переключаю язык комбинацией клавиш Alt + Shift. В Ubuntu её, разумеется, тоже можно задействовать, и почти во всех программах она работает без проблем. А в этих приложениях почти всегда при переключении языка активируется меню, которое обычно скрыто. И ладно, если бы оно просто появлялось. Оно еще и фокус забирает себе и не дает вводить текст дальше.
Эксперимент показывает, что если при переключении языка нажать Alt, нажать Shift, отпустить Shift, отпустить Alt, то язык переключается корректно и меню не вызывается. А у меня при быстром наборе последовательность отпусканий клавиш другая: я сначала отпускаю Alt, а потом отпускаю Shift, рука будто «перекатывается» между альтом и шифтом. Я пробовал изменять параметры как приложений, так и самой операционной системы. На хабре даже есть отдельная статья по решению этой проблемы. У меня ничего не получилось, и я просто стал запускать Слак в браузере. Работает он не хуже, чем в отдельном приложении.
Сюрпризы при обновлении
Каждая новая версия Ubuntu преподносит сюрпризы. Иногда приятные, когда
Еще пример. Недавно разработчики Ubuntu решили перейти с X11 на Wayland. В этом Wayland у меня не работала демонстрация экрана в Zoom. К счастью, они оставили возможность использовать и X11, только непонятно, надолго ли.
Резюме
В Ubuntu относительно удобно выполнять задачи разработчика, а задачи аналитика и менеджера выполнять или трудно, или совсем невозможно.
Войти в IT
Вход в IT здесь, вдруг

Как разработать систему рекомендаций ★
Продолжим разговор о системе рекомендаций в S2. Эта система подбирает к каждой заметке набор других заметок, которые посетитель может почитать дальше. В прошлый раз я рассказал об этой системе в целом, сейчас же опишу алгоритм подбора самих рекомендаций.
За рекомендации в моем случае отвечает движок полнотекстового поиска Rose. Структура данных в полнотекстовом индексе как раз подходит для задачи подбора похожих заметок. Если совсем упростить, то получается, что обычный поиск — это подбор подходящих заметок к словам из поискового запроса, а рекомендации к заметке — это подбор других заметок по словам из нее. А теперь давайте погрузимся в детали.
Теория рекомендаций
Для начала давайте поймем, как вообще могут работать системы рекомендаций. Рассуждать будем на примере существовавшего
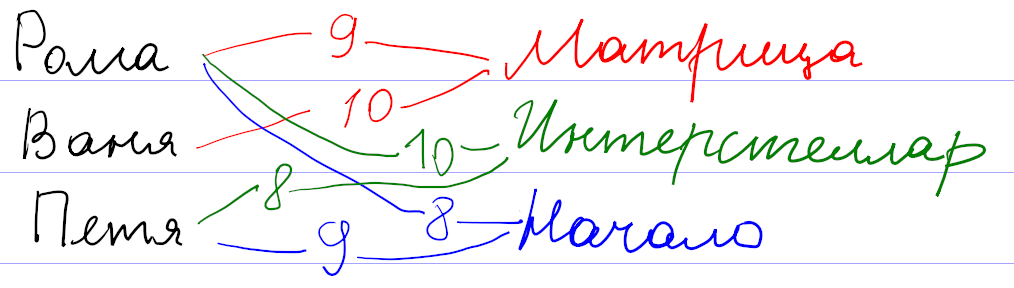
Оценки пользователей сохраняются как веса связи
Математика позволяет предложить более формальный и универсальный подход. Будем рассматривать оценки к фильмам как координаты некоторой точки во многомерном пространстве всех фильмов. Тогда всех пользователей можно представить как множество точек в таком пространстве. При достаточном количестве они начнут группироваться в кластеры по разным предпочтениям. После этого задача подбора рекомендаций сведется к поиску соответствующего кластера.
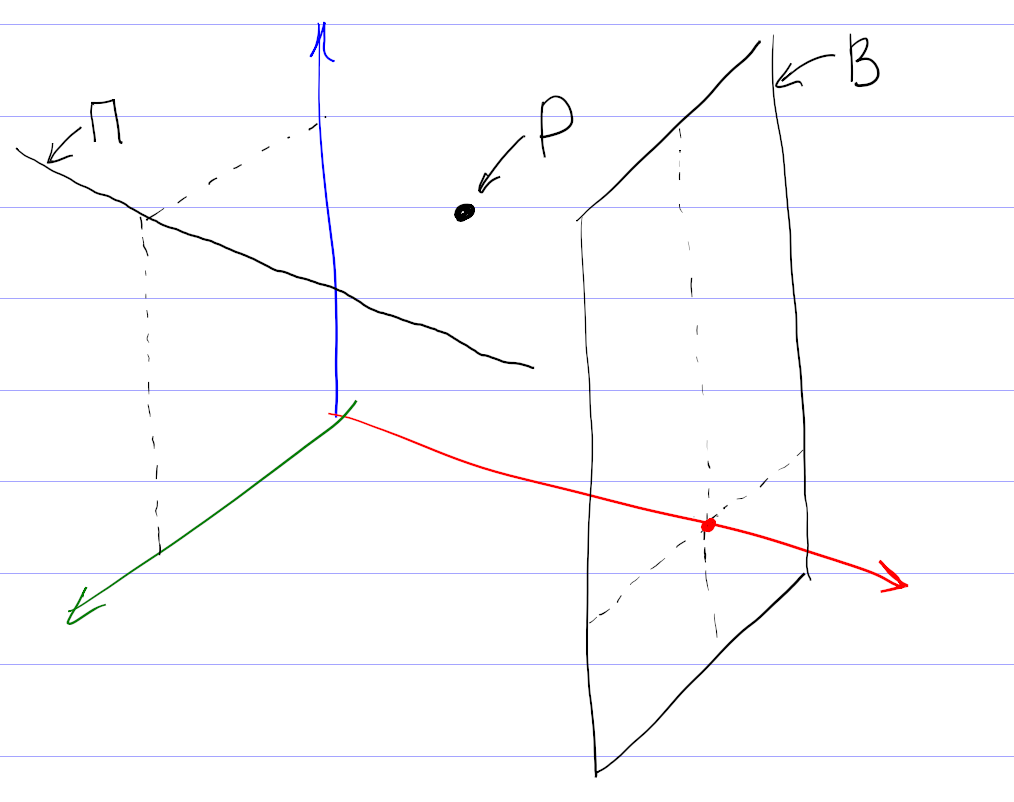
На самом деле, картина сложнее, так как никто не может поставить оценки всем фильмам. Поэтому вместо точек мы имеем дело с некоторыми подпространствами (прямыми, плоскостями и т. д.). Чтобы сформировать мои рекомендации, система проецирует все оценки на подпространство просмотренных мной фильмов, находит кластер в проекции, и по нему уже пытается восстановить кластер в полном пространстве.
Понятно, что процедура восстановления кластера из проекции неоднозначна, и в этом месте система рекомендаций может ошибаться, даже если в ней собраны оценки большого количества пользователей. Например, по оценкам фильмов, единогласно оцениваемых зрителями, нельзя восстановить предполагаемую оценку и однозначно рекомендовать фильм, мнения по которому разделились на два равновеликих полюса.
Эта теория прекрасно выглядит на листе бумаги. Но я уверен, что при практической реализации разработчики столкнулись с кучей проблем. Очевидная проблема — нормировка оценок. Например, у меня средняя оценка была около 7. Оценки меньше 4 я практически не ставил. Задумывался над тем, чем отличается оценка 9 от 10. Оценки других пользователей наверняка отличались по характеристикам.
Вы наверняка встречались с другим примером системы рекомендаций: поиском друзей в соцсетях. Здесь тоже работает связь
Теперь давайте посмотрим, как можно эти знания применить для подбора рекомендаций заметок.
Рекомендации на основе тегов
Как видно из предыдущего рассмотрения, систему рекомендаций можно сделать везде, где есть связь
Недостатки подхода лежат на поверхности.
Рекомендации на основе похожих текстов
В движке S2 есть другая связь
| word_id | toc_id | positions |
|---|---|---|
| 1 | 1 | 0,37 |
| 3 | 4 | 0,15,74,193,614 |
| 3 | 8 | 94 |
| 3 | 9 | 73 |
| 4 | 1 | 3,16,57 |
| … |
В первой колонке хранится id «слова», во второй — внутренний id проиндексированного элемента (ToC — это сокращение от table of contents), в третьей — положения соответствующего слова в проиндексированном тексте.
При индексации исходный текст заметок очищается от
При поиске запрос преобразуется по такой же схеме: слова заменяются на идентификаторы word_id, и из поискового индекса мы получаем информацию о том, в каких проиндексированных текстах (toc_id) встречались эти слова. Положения слов (positions) нужны для вычисления релевантности: чем ближе слова из запроса друг к другу в тексте, тем выше окажется этот текст в выдаче.
Рекомендации на основе близости текста тоже используют эту таблицу. У меня получилось уместить все существенные вычисления в один
SELECT
relevance_info.*, -- информация из подзапроса
m.images, -- добавляем к ней информацию о картинках
t.*, -- добавляем к ней оглавление
-- и первые 2 предложения из текста
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1) AS snippet,
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1 OFFSET 1) AS snippet2
FROM (
SELECT -- Перебираем все возможные заметки и вычисляем релевантность каждой для подбора рекомендаций
i.toc_id,
round(sum(
original_repeat + -- доп. 1 за каждый повтор слова в оригинальной заметке
exp( - abn/30.0 ) -- понижение веса у распространенных слов
* (1 + length(positions) - length(replace(positions, ',', ''))) -- повышение при повторе в рекомендуемой заметке, конструкция тождественна count(explode(',', positions))
) * pow(m.word_count, -0.5), 3) AS relevance, -- тут нормировка на корень из размера рекомендуемой заметки. Не знаю, почему именно корень, но так работает хорошо.
m.word_count
FROM fulltext_index AS i
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) ON m.toc_id = i.toc_id
JOIN (
SELECT -- достаем информацию по словам из оригинальной заметки
word_id,
toc_id,
(SELECT count(*) FROM fulltext_index WHERE word_id = x.word_id) AS abn, -- распространенность текущего слова по всем заметкам
length(positions) - length(replace(positions, ',', '')) AS original_repeat -- сколько раз слово повторяется в оригинальной заметке. Выше используется как доп. важность
FROM fulltext_index AS x FORCE INDEX FOR JOIN(toc_id)
JOIN toc AS t ON t.id = x.toc_id
WHERE t.external_id = :external_id AND t.instance_id = :instance_id
AND length(positions) - length(replace(positions, ',', '')) < 200 -- отсекаем слишком частые слова. Хотя 200 слишком завышенный порог, чтобы на что-то влиять
HAVING abn < 100 -- если слово встречается более чем в 100 заметках, выкидываем его, так как слишком частое. Помогает с производительностью
) AS original_info ON original_info.word_id = i.word_id AND original_info.toc_id <> i.toc_id
GROUP BY 1
HAVING count(*) >= :min_word_count -- количество общих слов, иначе отбрасываем
) AS relevance_info
JOIN toc AS t FORCE INDEX FOR JOIN(PRIMARY) on t.id = relevance_info.toc_id
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) on m.toc_id = t.id
ORDER BY relevance DESC
LIMIT :limitОпишу ключевые шаги, которые здесь выполняются.
1. Взять все слова в заметке, к которой подбираем рекомендации. Я называю эту заметку оригинальной. Выбор слов происходит в самом внутреннем подзапросе.
2. Выкинуть распространенные слова. Это нужно делать для повышения точности и при поиске, и при подборе рекомендаций. Можно даже составить список игнорируемых слов вроде союзов или предлогов. Но вместо составления такого неизменяемого списка я вычисляю распространенность (abundance, сокращенно abn — количество заметок, в которых встречается это слово) для каждого слова в индексе. Например, в блоге о дизайне в каждой заметке будет слово «дизайн», и его тоже надо игнорировать.
Слова с распространенностью больше 100 наверняка окажутся слишком общими, и я отбрасываю их по соображениям производительности. Скорее всего порог должен
3. Найти одинаковые слова у оригинальной заметки с остальными заметками. Это происходит в промежуточном подзапросе. У заметок при этом должно быть достаточное количество общих слов (порог определяется параметром min_word_count).
Я пробовал разные значения параметра. Если увеличивать, количество рекомендаций падает. Если уменьшать, в рекомендации попадают не очень подходящие заметки за счет случайного использования общих слов. Я остановился на варианте, когда запрос сначала выполняется со значением 4. Если результатов нет, как это часто бывает у коротких заметок, то запрос повторяется со значением параметра 2.
4. По повторяющимся словам вычислить релевантность. Это тоже происходит в промежуточном подзапросе в выражении в селекте благодаря group by. Релевантность я вычисляю как количество повторений общих слов. Чтобы понизить влияние распространенных слов, я добавил ослабление за счет веса exp(-abn/30.0). Хотел было использовать колоколообразную функцию типа exp(-sqr(abn/30.0)), но на практике линейное уменьшение веса при малых значениях распространенности повысило качество рекомендаций.
Кроме того, повторы в оригинальной заметке (original_repeat) и в рекомендуемых заметках влияют на релевантность несимметрично: повторяющиеся слова в оригинальной заметке не ослабляются, даже если они распространены. Объяснение можно предложить такое: если автор пишет одинаково часто о шахматах и шашках, то к оригинальной заметке с пятью словами «шахматы» и одним словом «шашки» лучше рекомендовать заметку с одним словом «шахматы», чем с пятью словами «шашки». Эффект несимметричности я не закладывал специально. Практика показала, что отсутствие ослабления у original_repeat субъективно улучшает качество рекомендаций.
Несимметричность веса оригинальной заметки и рекомендуемых может быть даже полезной, чтобы избежать «зацикливания» рекомендаций, когда к заметке А мы рекомендуем заметку Б, а к заметке Б — заметку А. Правда, у меня этот критерий не был обязательным, и я не проверял, как он выполняется. Применительно к моему сайту эффект зацикливания может ослабляться ещё и за счет последующего предпочтения в рекомендациях заметок с картинками.
Последний множитель в релевантности pow(m.word_count, -0.5) учитывает размер рекомендуемой заметки в словах. Без него в моем случае среди рекомендуемых оказывались очень длинные заметки, набиравшие релевантность за счет большого количества повторяющихся слов средней распространенности. Тогда я подумал, что сортировать рекомендации нужно не по абсолютному количеству общих слов, а по относительному, то есть надо поделить вычисленную релевантность на количество слов в рекомендуемой заметке. В рекомендации стали попадать короткие заметки всего из нескольких слов, а у нормальных заметок из нескольких сотен слов релевантность сильно просела. Чтобы было ни нашим ни вашим, я попробовал поделить абсолютную релевантность на корень из длины рекомендуемой заметки, и это сработало: с первых мест рекомендаций ушли как очень короткие, так и очень длинные заметки. Изменение показателя степени −0,5 в обе стороны приводило к некоторому повышению ранга одних и понижению ранга других таких нерелевантных заметок.
У меня не было объяснения, почему нормировка релевантности именно на корень из длины оказалась подходящей. Но в момент набора этого текста появилась гипотеза. Нормировка на длину рекомендуемых заметок не учитывает длину оригинальной заметки. Но для подбора рекомендаций к одной оригинальной заметке ее длина ни на что не влияет. Возможно, что для более общей задачи подбора рекомендаций к N оригинальным заметкам релевантность нужно нормировать на среднее геометрическое из длин оригинальной и рекомендуемой заметок. Тогда для одной оригинальной заметки ее длина превратится в несущественный постоянный коэффициент и уйдет за скобки, а длина рекомендуемой заметки как раз окажется в знаменателе под корнем.
5. Получить заголовок, картинки и фрагмент текста. Это неинтересная техническая задача, решаемая во внешней части запроса. Для «сниппетов» — коротких фрагментов текста — я достаю первые два предложения из заметок. Сначала думал выводить те предложения из текста, которые содержат общие слова. Зависимость сниппетов от контекста как раз бы показала, почему рекомендуется именно эта заметка. Но
Вопросы производительности
В запросе вы видите явное указание использовать конкретные индексы. Без них планировщик не использовал часть индексов. Почему он так решал — непонятно. За счет расстановки хинтов я оптимизировал запрос раз в 20 до нескольких десятков миллисекунд. Я последние 6 лет работаю с PostgreSQL, и он даже думать отучил, что в запросы можно добавить хинты. Но тут пришлось.
Производительность в несколько десятков миллисекунд я посчитал достаточной, чтобы выполнять
При работе на настоящем сервере выяснилось, что в режиме невысокой нагрузки база данных может иногда выполнять запрос существенно дольше — несколько сот миллисекунд или даже больше секунды. Вот данные мониторинга по средней длительности запроса:
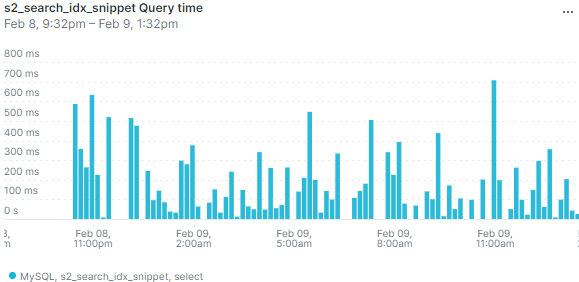
Выбросы на графике означают, что иногда пользователи будут замечать, что страница долго открывается. И изредка приходящий
Я добавил кеширование подбора рекомендаций. Кеш инвалидируется не по времени, а по обновлению заметок. Правда, мне пришлось инвалидировать весь кеш рекомендаций при любом изменении опубликованных заметок. Действительно, изменение хотя бы одного слова в
Кеш хорошо решает проблему с редкими выбросами, даже если заметки часто обновляются. Если в кеше есть устаревшие рекомендации, всё равно выводятся они, а в фоне в это время просчитываются новые рекомендации.
Я так и не понял, почему возникают такие всплески времени выполнения запроса. Не думаю, что конкуренция MySQL за процессорное время с PHP или Похоже, проблема связана с нагрузкой на гипервизор от соседних виртуальных машин.
Направления развития
- Убрать из запроса захардкоженные числа.
- [✓] Если рекомендаций с четырьмя общими словами нет, делать повторный запрос с ослабленным ограничением. А вообще тут важно найти баланс: надо ли показывать неподходящие рекомендации, если нет подходящих?
- Получать сниппеты из релевантных предложений, а не первых двух.
Дополнение о нормальной форме
Внимательный читатель отметил, что таблица полнотекстового индекса не находится даже в первой нормальной форме: в одной ячейке positions через запятую перечислен список положений слова. Что хорошо в теории, не всегда хорошо в настоящем работающем софте. Раньше действительно структура этой таблицы была другой, и каждый элемент из positions располагался на своей строке. Для корректной работы алгоритма мне нужно было обеспечить уникальность строк, поэтому элементы (word_id, toc_id, position) я еще добавил в уникальный индекс.
Достаточно быстро в целях оптимизации я отказался от индекса по word_id и повесил первичный ключ сразу на все колонки (word_id, toc_id, position). В этом есть смысл, так как первичный индекс в InnoDB кластерный, то есть данные строк хранятся на диске вместе с первичным индексом.
Сейчас я пошел в оптимизации дальше и отказался от нормальной формы для хранения положений. Базы данных устроены так, что в таблицах в каждой строке хранится дополнительная служебная информация. Объединение нескольких строк с одинаковыми word_id и toc_id в одну дало экономию места в полтора раза (поисковый индекс в целом уменьшился с 22 до 14 мегабайт при суммарном объеме заметок 2,8 мегабайт). Кроме того, скорость индексации тоже выросла примерно в полтора раза, так как сократилось количество выполняемых запросов. Я не обнаружил
Понятно, что отказ от нормальной формы — не универсальное решение. Так, в рассматриваемом примере пропала возможность фильтрации по полю position. Для задач поиска в этом ничего страшного нет, так как в них фильтрация по position не встречается. Хотя по большому счету мало что изменилось: фильтрацию всё еще можно делать через операции с поиском подстроки, и это не будет сильно медленнее, потому что и раньше по полю position отдельного индекса не было.
Запрет висячих заголовков в CSS
Пару лет назад я сделал стили для печати в своем редакторе математических текстов Upmath. Тогда же я отмечал проблемы подхода, в частности, «висячие заголовки». Не уверен, что такой термин существует, под ним я имею в виду заголовок, расположенный последним на странице и оторванный от следующего текста.
В CSS есть свойства, которые управляют запретом на разбиение страниц. Но мне так и не удалось заставить их работать. Я предположил, что это баг в браузерах, и добавил в трекер периодически всплывающую задачу «проверить запрет разбиения страницы после заголовка». Наконец, сегодня проверка показала, что в Хроме свойства заработали!
Есть два варианта синтаксиса, сейчас работают оба:
h1, h2, h3 {
page-break-after: avoid;
break-after: avoid;
}Результат применения выглядит так (было — стало):

Проверил еще Firefox, в нем запрет разбиения не заработал. А больше
Cистема рекомендаций на сайте
Сделал для своего сайта систему рекомендаций. После каждой заметки отображаются аккуратно сверстанные ссылки на похожие материалы. Вот несколько скриншотов, показывающих, как это выглядит.
Пример 1 — антикоррупционный митинг:

Пример 2 — где учиться, на физтехе или физфаке:
Пример 3 — сворачивание кешбека в Бинбанке:
Систему рекомендаций в таком виде сделал Илья Бирман в Эгее — своем движке блогов. В его случае рекомендации к постам формируются на основе тегов. Тогда у меня появилась идея, как можно подбирать рекомендации на основе анализа текстов, без необходимости расставлять теги. Но одно дело — идея, и совсем другое — работающий продукт.
Подбор рекомендаций
Чтобы воплотить идею в жизнь, мне пришлось проделать много подготовительной работы.
Я подключил к моему движку сайтов S2 поисковый движок Rose. s2/search). Но Илья убедил меня, что библиотеке для поиска, как и любому продукту, нужно нормальное имя, и даже предложил несколько вариантов. Название «Ropsen», содержащее первые буквы из Roman Parpalak Search Engine,
Вместе с именем в Розе многое поменялось внутри. Я привел в порядок код, чтобы он следовал правилам хорошего тона для библиотек на PHP: с интерфейсами, инверсией зависимостей и прочими вещами, скрытыми за аббревиатурой SOLID. Кроме того, я сделал реализацию хранилища поискового индекса в MySQL (предыдущая реализация была просто в файле).
Поиск в S2 продолжал работать на старой кодовой базе. Мне казалось, что потребуется много времени, чтобы удалить из
Почему я вообще в заметке о рекомендациях пишу уже четвертый абзац не о рекомендациях, а о поиске? Потому что рекомендации к некоторой заметке на основе ее текста — это, грубо говоря, результаты поиска по словам из этой заметки. Мне удалось написать
Оформление рекомендаций
Чтобы выводить рекомендуемые заметки не просто списком, мне пришлось доработать поисковый движок Rose, чтобы в нем сохранялись предложения из проиндексированных заметок и информация о картинках.
Мне очень понравилось, как выглядят рекомендации у Ильи, и я решил сделать так же. Кроме того, он в своем докладе об автоматическом дизайне рассказал, каким образом работает автоматическая верстка рекомендаций в Эгее. Он подготовил список хорошо сверстанных вариантов и перевел их в некоторый декларативный конфиг с описанием критериев соответствия для каждого элемента верстки (вроде размера и пропорций картинок, длины заголовка и прочего). Дальше для набора рекомендуемых заметок подбирается наиболее подходящий вариант верстки. Обязательно посмотрите видео по ссылке о том, как это всё придумано и работает.
После повторного просмотра видео доклада, которое можно считать подробным и понятным техзаданием, я понял, что не смогу придумать
Тем не менее, я сделал свой декларативный язык. Описал несколько очевидных вариантов верстки, например для пяти рекомендаций: одна крупная рекомендация слева и четыре поменьше справа.
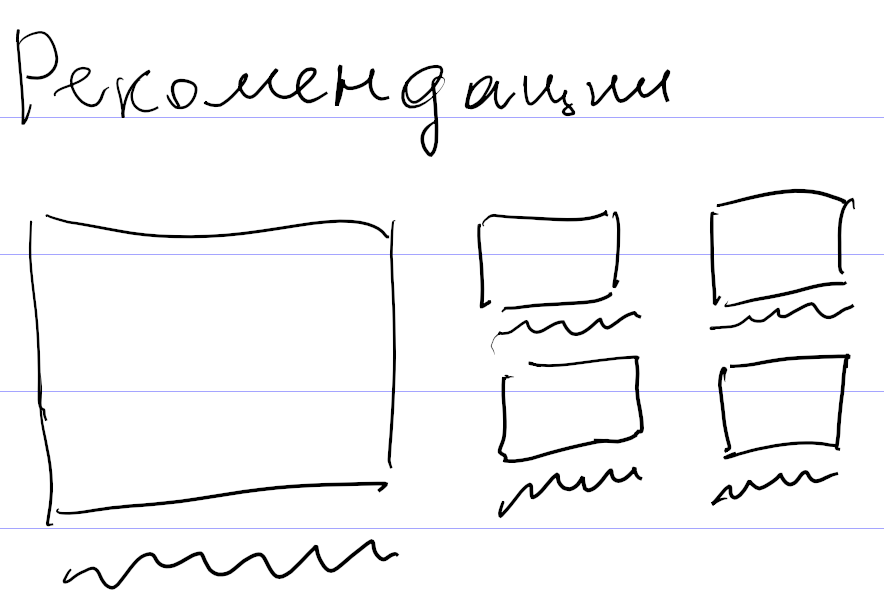
Затем стал смотреть, как имеющиеся рекомендации ко всем подряд заметкам раскладываются по этим вариантам верстки. Выбрал критерий успеха: заметки с картинками не должны выводиться без превьюшек картинок. Если этот критерий не выполнялся, значит, для таких рекомендаций не было подходящего варианта верстки. Я смотрел на них и прикидывал, как надо вывести заметки, чтобы использовать все возможные картинки. Причем делал это не в графическом редакторе, а сразу описывал новый вариант на своем декларативном языке, и он применялся к рекомендациям.
В результате таким способом, никуда не подглядывая, я накопипастил 113 вариантов верстки. Ближе к концу я стал понимать, что это
В процессе мне пришлось изобрести некоторые неочевидные приемы. Например, после определения варианта верстки я сортирую рекомендации по убыванию высоты картинок, а если высота одинакова или картинок вообще нет — по убыванию длины текста. Это нужно, чтобы дыры в верстке появлялись ближе к правому краю, который и так рваный, а не к левому. С дырами получалось забавно: я начал было подбирать длины текста так, чтобы он максимально заполнял дыры. Но рекомендации в некоторых пределах резиновые, а при изменении ширины страницы такие объекты как картинка и текст ведут себя
Еще одно изобретение — отрицательная максимальная длина текста. Она появилась при попытке собрать из картинки и текста блок примерно одинаковой высоты. Скажем, на
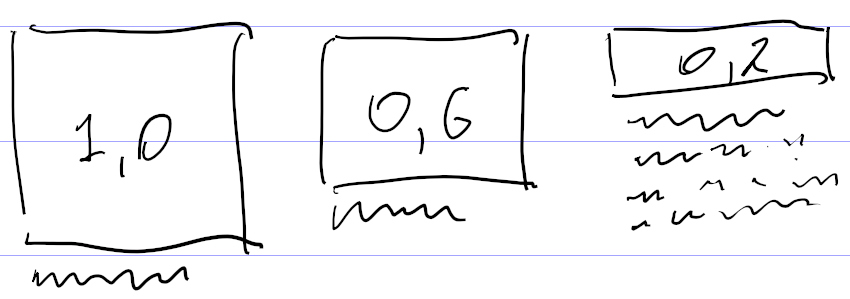
Чтобы не плодить разные варианты одной и той же верстки с таким отличием, я придумал характеризовать текст не только минимальной и максимальной длиной, но и дополнительным коэффициентом, на который умножается «нехватка» высоты картинки для определения дополнительной длины текста. А если картинка с высотой 1,0 тоже подходит, то у картинки с высотой 0,6 за счет добавки обязательно появится текст.
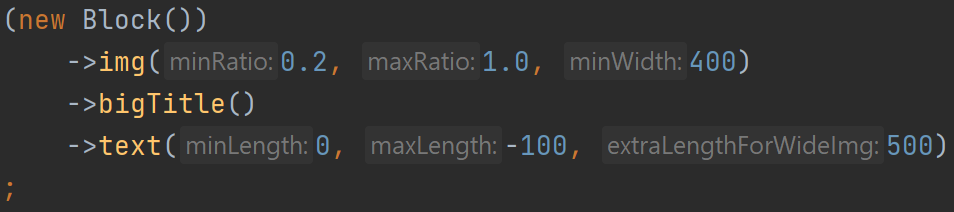
Сначала я хотел сделать дополнительный параметр для отсчета нехватки высоты от 0,6, а не от 1,0. Но потом понял, что того же можно добиться отрицательной длиной текста.
Ограничения рекомендаций и планы на будущее
У Ильи кроме рекомендаций есть еще и перебивки — оформленные таким же образом ссылки в списках записей. Я не стал их делать. В моем понимании рекомендации решают задачу направить посетителя почитать другие записи. Но в списках и так достаточно записей для чтения. Да и технически подобрать ссылки к нескольким записям на одной странице тяжелее, чем к одной записи. Нужно исключать повторы, чтобы одинаковые блоки не повторялись на этой странице.
Сейчас, если в блоке рекомендаций надо вывести текст, я беру
Зарисовка для объяснения понятия формата
Нашел черновик статьи о понятии формата и вебе, которую я так и не написал и вместо которой снял видео из серии «в кресле препода». В черновик я успел написать только одну зарисовку для иллюстрации понятия формата. В видео зарисовка не вошла, вместо нее я сослался на известный ролик о работе техподдержки. Решил опубликовать черновик, может
Многие люди, даже профессионально занимающиеся разработкой сайтов, имеют смутные представления о понятии формата. Это понятие играет трудно уловимую, но важную роль в проектировании и разработке сайтов. Чем больше будущий сайт соответствует формату, тем быстрее пойдет разработка и тем проще будет посетителям.
Чтобы пояснить, что я подразумеваю под форматом, рассмотрим для примера газеты и книги. И то и другое — печатная продукция. На газетах распространяется небольшая порция ежедневной информации. Их после прочтения выбрасывают. Поэтому газеты печатают на дешевой тонкой бумаге. Книги объемнее, используются и хранятся долго. Их печатают на хорошей плотной бумаге и переплетают.
Можно представить, что будет с романом, напечатанным в формате газеты, а не формате книги. А вот более яркий пример. Представьте, что вы работаете в типографии и к вам приходит клиент.
— Я хочу напечатать свою поэму.
— Какой у вас тираж?
— Штук сто,
— Большая поэма? Сколько страниц?
— 100 страниц в Ворде. Но я не хочу, чтобы это была обычная книга. Я хочу напечатать на рулоне бумаги.
— Что? — вырывается у вас с плохо скрываемым удивлением.
— Ну на таком рулоне, типа как обои, только поменьше, — размахивает руками клиент.
— А чем вас книга не устраивает?
— Книга? Это вчерашний день. Рулон удобнее.
— Чем же он удобнее?
— Как чем? Страницы в книге нужно перелистывать. Это неудобно. На время перелистывания отрываешься от чтения. Ну и если книга закроется, трудно найти место, где читал, если не запомнить страницу.
— И что? А причем тут рулон?
— Ну как причем? Если напечатать на рулоне, то в процессе чтения его легко перематывать. Не нужно перескакивать с одной страницы на другую. И рулон можно спокойно отложить, он не закроется.
— Я вообще первый раз такое слышу. Все печатают и читают книги. Их удобно носить и держать на полке. И недостатки не такие уж и большие. Есть же закладки, оглавление. И перевернуть страницу ничего не стоит.
— Если все
— Извините, у нас нет такого оборудования, — мягко посылаете клиента.
Разговор в таком стиле вряд ли возможен о привычных предметах окружающего мира, но постоянно встречается при обсуждении компьютерных интерфейсов. Я задумался, почему так происходит, когда прочитал на хабрахабре статью о критике современных
Как нормально сверстать хотя бы такой блокнотик с закладками на CSS/HTML без извращений и большого количества JS кода вовсе не ради динамики, а прямо для самой отрисовки и позиционирования?
И из моего ответа:
Есть понятие формата, которое вы себе, судя по уже второму посту, плохо представляете. Нужно думать не о переносе конкретной реализации блокнотика из операционной системы в веб, а о решении той же задачи, которую решал блокнотик.
Очевидно, этот блокнотик был придуман, чтобы разместить в одном окне ограниченного размера как можно больше элементов управления. Даже если оставить в стороне уродливость внешнего вида, такое решение со вкладками не является очень хорошим примером интерфейса, так как пользователь не знает (или не помнит, ведь окном настройки не пользуются постоянно) плотность заполнения каждой вкладки и не имеет представления о том, сколько еще параметров можно изменить.
Проблема нехватки места в вебе прекрасно решается прокруткой. Поэтому, чтобы решить ту же задачу, нужно поместить друг под другом содержимое каждой вкладки, предваренное крупными заголовками. У такого метода целая куча достоинств. К прокрутке привыкли все. На больших экранах пользователь увидит сразу всю форму. Таким образом, на HTML/CSS блокнотика нет, но задача, которую он выполнял, решается.
При проектировании интерфейсов не нужно забывать о формате.
Еще в черновике было написано graceful degradation и progressive enhancement. Скорее всего, я хотел сказать, что начинать разработку надо с чистого HTML, а затем добавлять оформление в CSS и поведение в JS (progressive enhancement). А не делать наоборот — сначала разработать
Кстати, посмотрите само видео о понятии формата, если еще не посмотрели или уже забыли, о чем оно:
Мастер костылей, или сущности в DOMDocument
Я тут решил потратить некоторое время на собственные проекты. Сейчас перерабатываю движок для поиска Rose. На нем работает поиск на этом сайте, также его использует Илья Бирман в Эгее.
Для извлечения текста из
Как оказалось, DOM API не поддерживает HTML5. Это выливается в практическую проблему с непоследовательной обработкой сущностей HTML. Например, если в исходнике написать & ★, при получении текстового содержимого из & ★. Видим, что первая сущность из HTML предыдущих версий распознается и раскодируется, а вторая из HTML5 — нет. Такие ошибки приведут к искажениям при выводе сниппетов.
Моя первая идея — прогнать текстовое содержимое через html_entity_decode($a, ENT_HTML5);. Действительно, что не доделал встроенный парсер, доделает эта функция. Но проблема в том, что раскодирование неидемпотентно. Если на вход подать &bigstar;, то после DOM API мы получим ★. И на этапе повторного раскодирования мы не будем знать, нужно ли раскодировать ★ еще раз, или нет.
Поиск проблемы в гугле разумного решения не выявил. В классе DOMDocument есть
Для начала нужно все вхождения амперсанда заменить на его сущность:
$text = str_replace('&', '&', $text);После этого DOM API раскодирует копии только одой сущности — этого самого амперсанда. При рекурсивном обходе в текстовом содержимом узлов html_entity_decode($a, ENT_HTML5);.
Уже который раз убеждаюсь, что искусство программиста во многом заключается в умении подобрать нужный костыль. Так и живем.
Отладка запросов к FastCGI из консоли
Обычно протокол FastCGI применяется для общения между
Однако как быть, если у вас есть собственный сервис, работающий по протоколу FastCGI (скажем, простая асинхронная очередь через
Можно было бы настроить в nginx отдельный location, подключить к нему отлаживаемый сервис и отправлять
Предположим, у вас есть скрипт, который забирает входные данные из $_POST['formula'] и $_POST['extension']. Тогда вызвать этот скрипт с данными formula=12345 и extension=svg можно вот так:
user@tau:~$ echo "formula=12345&extension=svg" | sudo -uwww-data \
> CONTENT_TYPE='application/x-www-form-urlencoded' CONTENT_LENGTH=28 \
> SCRIPT_FILENAME=/var/www/.../.../cache_processor.php \
> REQUEST_METHOD=POST cgi-fcgi -bind -connect /var/run/php_fpm.sockВ консоли мы увидим ответ, например, такой:
PHP message: PHP Warning: file_get_contents(...): failed to open stream: No such file or directory in ... on line 88Content-type: text/html; charset=UTF-8
В этом методе используется утилита
Про войну
Скоро уже будет год, как идет война в Украине (я называю вещи своими именами, как и Путин). Я хотел написать о войне раньше. Текст мне не понравился, я не стал публиковать его. Но и писать о
Решил сформулировать и записать свои мысли и ощущения. Не потому, что они представляют для
Стремительное начало войны было для меня совсем неожиданным. Первые дни тяжело было психологически. Невозможно было представить, что твоя страна нападает на ближайшего соседа и развязывает полномасштабную войну. Логика подсказывает, что ты должен быть на стороне жертвы и оправдывать отпор агрессору. Но отпор в этом случае — убийство таких же во многом невиновных людей. И становилось еще хуже от ощущения, что ни на что повлиять не можешь.
Немного помогали проявления солидарности с Украиной в повседневной жизни. Вот, например, 26 февраля украинский флаг на гирлянде с управляемой подсветкой:

Больше я такой подсветки в этом окне не видел. Надеюсь, его не разбили. А вот еще идеологическая борьба на лестничной площадке, где неравнодушный житель оставлял надписи, а его противник не ленился искать краску и их замазывать:


Из рациональных мыслей в начале войны у меня была одна, которой можно поделиться. Нападение Путина на Украину можно сравнить с нападением Сталина на Польшу в 1939 году. Он тоже проводил «военную операцию» в Польше после подписания пакта Молотова — Риббентропа и секретного протокола к нему (подлинность этих документов подтверждена МИДом в 2019 году). Но Сталин смог оказаться среди победителей во второй мировой войне и участвовать в ялтинском разделе мира только
Выходить на протесты я не стал. Сейчас любой протест автоматом означает задержание. И польза от протестов может быть только в расколе элит, что возможно при численности митингов от миллионов или хотя бы нескольких сот тысяч людей. Сегодня это непредставимые числа. 10 лет назад была совершенно другая атмосфера. Как очевидцу событий на Болотной мне было ясно, что Путин самостоятельно из Кремля не уйдет. А уже 8 лет назад, когда происходили события в Крыму, «очнувшимся» людям с вопросом «а что можно сделать?» оставался только один ответ — «валить». Хотя тогда всё еще можно было выйти на марш против войны, но его численность была на порядок меньше необходимой.
В новостях сообщали о задержаниях людей даже с пустым листом бумаги. Известный анекдот советских времен про мужика, разбрасывающего пустые листовки, стал реальностью. Кроме того, стали реальностью даже лозунги из оруэлловской антиутопии «1984»: «война — это мир, свобода — это рабство, незнание — сила».
Кстати, Марш мира и Марш правды — это ответ на вопрос о том, где я был 8 лет назад. И у меня для вас есть встречный вопрос — а где вы были 11 лет назад, когда Путин в нарушение конституции возвращался в кресло президента, чтобы оставить более заметный след в учебнике истории? Если бы он не пошел на выборы в 2012 году, его бы все вспоминали как хорошего президента. А как его будут вспоминать теперь?
Еще в черновике было
Прокси-сервер через ssh
Полезная вещь в современных условиях —
ssh -D 1337 -q -C -N example.comРазумеется, вместо example.com нужно подставить ваш хост. После запуска вы можете использовать localhost и порт 1337 как параметры SOCKS5
Если у вас windows, можете взять консоль WSL, установить MinGW или поискать аналогичную функциональность в PuTTY на вкладке Connection/SSH/Tunnels.